Dynamic data sampler for cross-language transfer learning in large language models
作者: Yudong Li, Yuhao Feng, Wen Zhou, Zhe Zhao, Linlin Shen, Cheng Hou, Xianxu Hou
分类: cs.CL
发布日期: 2024-05-17
备注: Accepted by ICASSP 2024
💡 一句话要点
提出ChatFlow,一种基于跨语言迁移学习的动态数据采样中文LLM训练方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 跨语言迁移学习 动态数据采样 中文LLM LLaMA2 自然语言处理 持续训练 混合语料库
📋 核心要点
- 训练非英语LLM面临语料库和计算资源挑战,现有方法成本高昂且效果有限。
- ChatFlow通过跨语言迁移学习,利用混合语料库对齐跨语言表示,实现知识有效迁移。
- 动态数据采样器平滑过渡预训练和微调阶段,加速模型收敛,提升中文任务性能。
📝 摘要(中文)
大型语言模型(LLM)因其广泛的应用在自然语言处理(NLP)领域受到了极大的关注。然而,由于难以获取大规模语料库和所需的计算资源,训练非英语语言的LLM面临着巨大的挑战。本文提出了一种基于跨语言迁移的LLM——ChatFlow,旨在解决这些挑战,并以经济高效的方式训练大型中文语言模型。我们采用中文、英文和并行语料库的混合数据,持续训练LLaMA2模型,旨在对齐跨语言表示,并促进知识迁移到中文语言模型。此外,我们使用动态数据采样器,逐步将模型从无监督预训练过渡到有监督微调。实验结果表明,我们的方法加速了模型收敛并取得了优异的性能。我们在流行的中文和英文基准测试中评估了ChatFlow,结果表明它优于在LLaMA-2-7B上进行后训练的其他中文模型。
🔬 方法详解
问题定义:论文旨在解决中文大型语言模型训练中数据稀缺和训练成本高昂的问题。现有方法要么依赖大量计算资源从头训练,要么直接使用英文预训练模型进行微调,但后者在中文任务上的表现往往不尽如人意。痛点在于如何高效地利用有限的中文数据和已有的英文知识,训练出高性能的中文LLM。
核心思路:论文的核心思路是利用跨语言迁移学习,将英文LLM(LLaMA2)的知识迁移到中文LLM。通过混合中文、英文和并行语料库进行持续训练,使模型能够同时理解和生成多种语言,从而对齐跨语言表示。此外,采用动态数据采样策略,逐步调整训练数据分布,实现从无监督预训练到有监督微调的平滑过渡。
技术框架:ChatFlow的整体训练框架基于LLaMA2模型。主要包含以下几个阶段:1) 混合语料库构建:收集并整合中文、英文和并行语料库。2) 持续预训练:使用混合语料库持续训练LLaMA2模型,使其具备初步的跨语言能力。3) 动态数据采样:根据模型训练进度,动态调整不同语料库的采样比例,逐步增加中文数据的比例,并引入有监督数据。4) 评估与调优:在中文和英文基准测试中评估模型性能,并进行相应的调优。
关键创新:论文的关键创新在于动态数据采样策略。传统的迁移学习方法通常采用固定的数据比例进行训练,而ChatFlow能够根据模型训练的实际情况,动态调整不同语料库的采样比例,从而更好地平衡跨语言知识迁移和中文任务的适应性。这种动态调整机制能够加速模型收敛,并提升中文任务的性能。
关键设计:动态数据采样器的具体实现细节未知,论文中可能没有详细描述。但可以推测,其关键设计可能包括:1) 采样比例的调整策略:例如,可以根据模型在中文任务上的表现,动态调整中文数据的采样比例。2) 采样比例的平滑过渡:为了避免训练过程中的突变,可以采用平滑函数来控制采样比例的变化。3) 损失函数的权重调整:可以根据不同语料库的特点,调整损失函数的权重,以更好地平衡不同语言的学习。
🖼️ 关键图片
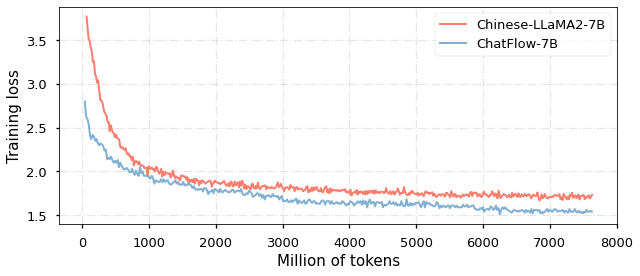


📊 实验亮点
实验结果表明,ChatFlow在中文和英文基准测试中均取得了优异的性能,优于在LLaMA-2-7B上进行后训练的其他中文模型。具体性能数据未知,但摘要中明确指出ChatFlow加速了模型收敛,并实现了性能的提升。这些结果验证了跨语言迁移学习和动态数据采样策略的有效性。
🎯 应用场景
该研究成果可广泛应用于中文自然语言处理领域,例如智能客服、机器翻译、文本摘要、情感分析等。通过低成本地训练高性能中文LLM,可以促进中文NLP技术的发展和应用,并为中文用户提供更好的服务。未来,该方法还可以扩展到其他低资源语言的LLM训练中,具有重要的实际价值和广泛的应用前景。
📄 摘要(原文)
Large Language Models (LLMs) have gained significant attention in the field of natural language processing (NLP) due to their wide range of applications. However, training LLMs for languages other than English poses significant challenges, due to the difficulty in acquiring large-scale corpus and the requisite computing resources. In this paper, we propose ChatFlow, a cross-language transfer-based LLM, to address these challenges and train large Chinese language models in a cost-effective manner. We employ a mix of Chinese, English, and parallel corpus to continuously train the LLaMA2 model, aiming to align cross-language representations and facilitate the knowledge transfer specifically to the Chinese language model. In addition, we use a dynamic data sampler to progressively transition the model from unsupervised pre-training to supervised fine-tuning. Experimental results demonstrate that our approach accelerates model convergence and achieves superior performance. We evaluate ChatFlow on popular Chinese and English benchmarks, the results indicate that it outperforms other Chinese models post-trained on LLaMA-2-7B.