Adaptable and Reliable Text Classification using Large Language Models
作者: Zhiqiang Wang, Yiran Pang, Yanbin Lin, Xingquan Zhu
分类: cs.CL
发布日期: 2024-05-17 (更新: 2024-12-07)
备注: ICDM Workshop ARRL 2024
🔗 代码/项目: GITHUB
💡 一句话要点
提出一种基于大语言模型的可适应、高可靠文本分类范式,简化传统流程。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 文本分类 大型语言模型 零样本学习 少样本学习 微调 自然语言处理 情感分析
📋 核心要点
- 传统文本分类流程复杂,依赖大量预处理和领域知识,限制了其适应性和可靠性。
- 利用大型语言模型(LLM)作为核心,简化文本分类流程,减少对领域知识的依赖。
- 实验表明,特定LLM在情感分析等任务上超越传统方法,且微调后性能更优。
📝 摘要(中文)
本文提出了一种可适应且可靠的文本分类范式,该范式利用大型语言模型(LLM)作为核心组件来解决文本分类任务。我们的系统简化了传统的文本分类工作流程,减少了对大量预处理和领域特定专业知识的需求,从而提供可适应且可靠的文本分类结果。我们在四个不同的数据集上评估了几种LLM、机器学习算法和基于神经网络的架构的性能。结果表明,某些LLM在情感分析、垃圾短信检测和多标签分类方面超越了传统方法。此外,通过少样本学习或微调策略可以进一步提高系统的性能,微调后的模型在所有数据集中表现最佳。源代码和数据集可在GitHub存储库中找到:https://github.com/yeyimilk/llm-zero-shot-classifiers。
🔬 方法详解
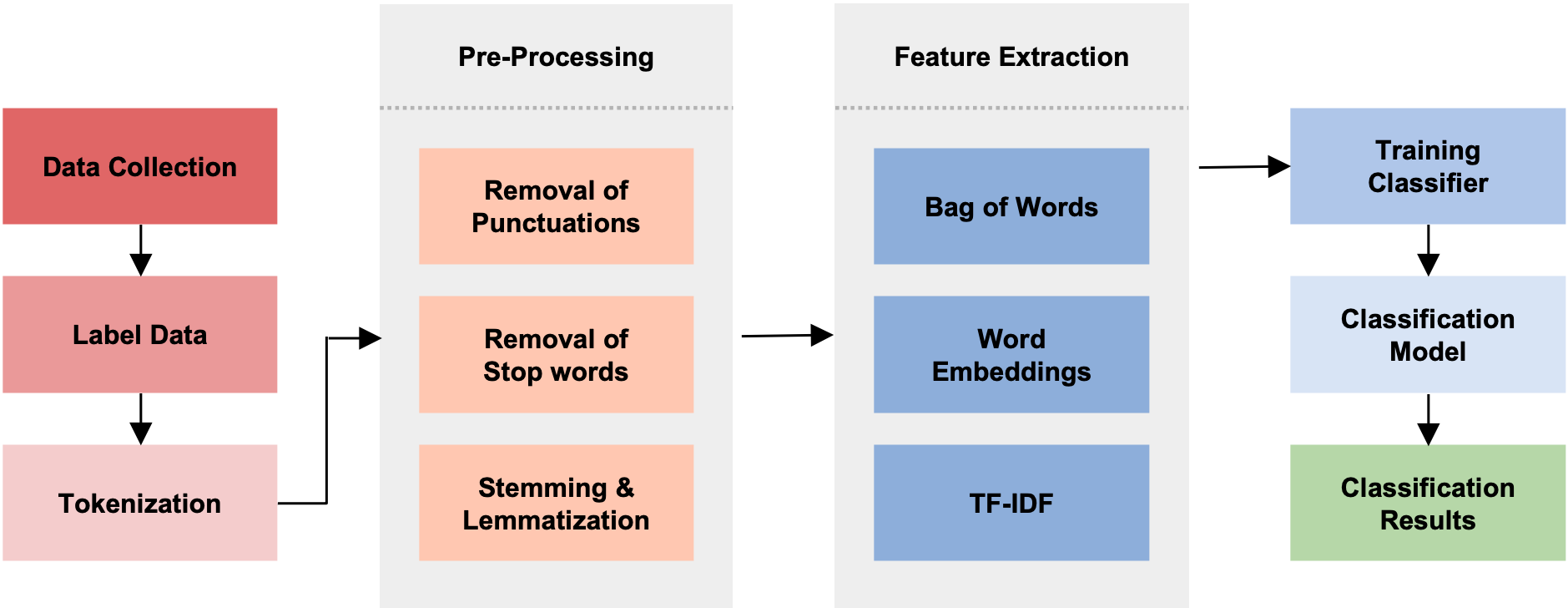
问题定义:论文旨在解决传统文本分类方法流程复杂、依赖大量预处理和领域知识的问题。现有方法在面对不同领域或任务时,需要耗费大量人力进行特征工程和模型调优,缺乏通用性和可移植性。
核心思路:论文的核心思路是利用大型语言模型(LLM)强大的zero-shot学习能力,直接将文本分类任务转化为LLM的prompting任务,从而减少对领域知识的依赖。通过few-shot学习或微调,进一步提升LLM在特定任务上的性能。
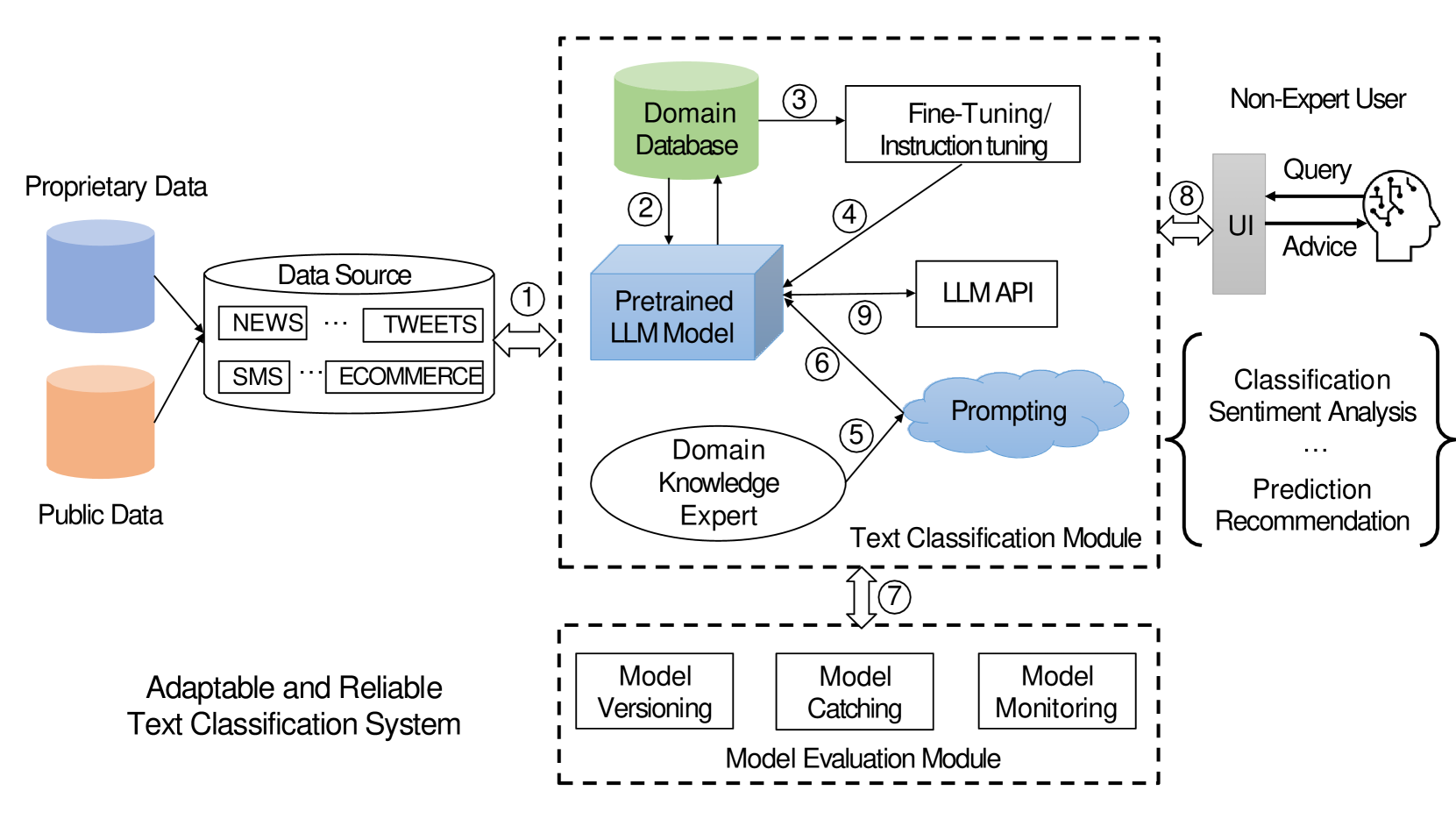
技术框架:该文本分类系统主要包含以下几个阶段:1) 选择合适的LLM作为基础模型;2) 设计合适的prompt,将文本分类任务转化为LLM可以理解的自然语言问题;3) 使用zero-shot、few-shot或fine-tuning策略来训练或调整LLM;4) 评估模型在不同数据集上的性能。
关键创新:该方法最重要的创新点在于利用LLM的zero-shot能力,极大地简化了文本分类流程,降低了对领域知识和人工特征工程的需求。通过prompt工程和模型微调,可以进一步提升模型在特定任务上的性能,实现可适应和高可靠的文本分类。
关键设计:论文中涉及的关键设计包括:1) prompt的设计,需要根据不同的文本分类任务进行调整,以引导LLM正确理解任务目标;2) few-shot样本的选择,需要选择具有代表性的样本,以提升LLM的学习效率;3) fine-tuning策略的选择,需要根据数据集的大小和特点选择合适的优化算法和超参数。
🖼️ 关键图片

📊 实验亮点
实验结果表明,某些LLM在情感分析、垃圾短信检测和多标签分类等任务上超越了传统的机器学习和深度学习方法。通过少样本学习或微调策略,可以进一步提高系统的性能,微调后的模型在所有数据集上表现最佳,验证了该方法的可行性和有效性。
🎯 应用场景
该研究成果可广泛应用于各种文本分类场景,如情感分析、垃圾邮件检测、新闻分类、舆情监控等。其简化流程和高可靠性使其在实际应用中具有重要价值,尤其是在缺乏领域专家或需要快速部署的场景下。未来,该方法有望进一步扩展到其他自然语言处理任务,如文本摘要、机器翻译等。
📄 摘要(原文)
Text classification is fundamental in Natural Language Processing (NLP), and the advent of Large Language Models (LLMs) has revolutionized the field. This paper introduces an adaptable and reliable text classification paradigm, which leverages LLMs as the core component to address text classification tasks. Our system simplifies the traditional text classification workflows, reducing the need for extensive preprocessing and domain-specific expertise to deliver adaptable and reliable text classification results. We evaluated the performance of several LLMs, machine learning algorithms, and neural network-based architectures on four diverse datasets. Results demonstrate that certain LLMs surpass traditional methods in sentiment analysis, spam SMS detection, and multi-label classification. Furthermore, it is shown that the system's performance can be further enhanced through few-shot or fine-tuning strategies, making the fine-tuned model the top performer across all datasets. Source code and datasets are available in this GitHub repository: https://github.com/yeyimilk/llm-zero-shot-classifiers.