Autonomous Workflow for Multimodal Fine-Grained Training Assistants Towards Mixed Reality
作者: Jiahuan Pei, Irene Viola, Haochen Huang, Junxiao Wang, Moonisa Ahsan, Fanghua Ye, Jiang Yiming, Yao Sai, Di Wang, Zhumin Chen, Pengjie Ren, Pablo Cesar
分类: cs.CL, cs.AI, cs.HC
发布日期: 2024-05-16 (更新: 2024-06-05)
备注: Accepted by ACL 2024
💡 一句话要点
提出用于混合现实中细粒度训练的自主多模态工作流
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 混合现实 多模态学习 自主代理 细粒度训练 语言模型 视觉问答 扩展现实
📋 核心要点
- 现有方法在多模态环境下对环境的细粒度、全面理解不足,限制了AI代理在XR中的应用。
- 设计了一种自主工作流,集成了语言代理和视觉-语言代理,使AI代理能根据经验在XR环境中自主行动。
- 提出了LEGO-MRTA数据集,并以此评估了多个LLM的性能,为XR环境下的AI助手研究提供了基准。
📝 摘要(中文)
本文设计了一种自主工作流,旨在将人工智能(AI)代理无缝集成到扩展现实(XR)应用中,以实现细粒度的训练。通过在XR环境中进行乐高积木组装的演示,展示了一个多模态细粒度训练助手。该助手包含一个整合了LLM、记忆、规划以及与XR工具交互能力的“大脑”语言代理,以及一个视觉-语言代理,使代理能够根据过去的经验决定其行为。此外,本文还提出了LEGO-MRTA,一个通过商业LLM自动合成的多模态细粒度组装对话数据集,包含多模态指令手册、对话、XR响应和视觉问答。最后,评估了几个流行的开源LLM在有无使用该数据集进行微调情况下的性能。该工作流有望推动更智能的助手在XR环境中实现无缝用户交互,促进AI和HCI领域的研究。
🔬 方法详解
问题定义:论文旨在解决在扩展现实(XR)环境中,如何让AI代理能够理解多模态信息,并进行细粒度的任务训练。现有方法难以对XR环境进行细粒度、全面的理解,导致AI代理无法有效地辅助用户完成复杂任务,例如乐高积木的组装。
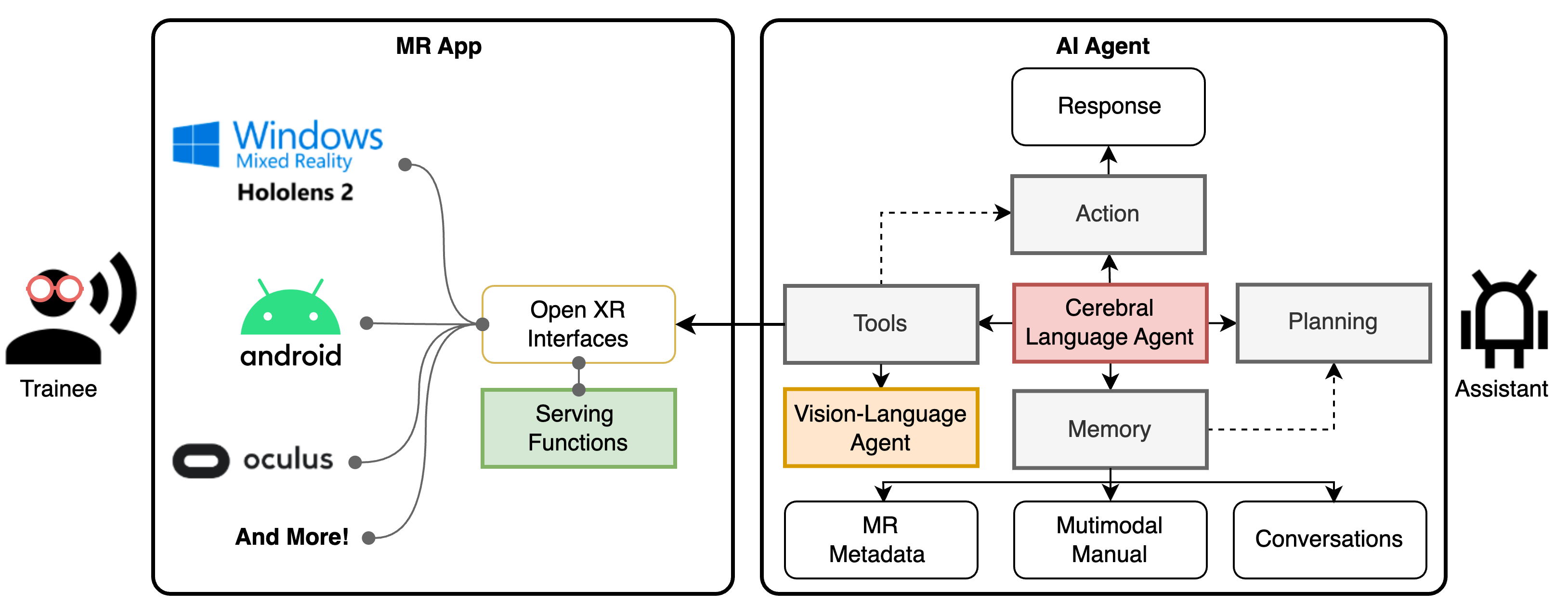
核心思路:论文的核心思路是构建一个自主工作流,该工作流包含一个“大脑”语言代理和一个视觉-语言代理。语言代理负责处理语言指令,进行任务规划,并与XR工具交互;视觉-语言代理负责理解视觉信息,并回答相关问题。通过整合这两个代理,AI助手能够理解多模态信息,并根据过去的经验自主地执行任务。
技术框架:该工作流主要包含以下几个模块:1) 大脑语言代理:基于LLM,整合了记忆模块、规划模块和交互模块,负责理解用户指令,规划任务步骤,并与XR环境进行交互。2) 视觉-语言代理:负责理解XR环境中的视觉信息,并回答相关问题。3) LEGO-MRTA数据集:用于训练和评估AI代理的多模态数据集,包含多模态指令手册、对话、XR响应和视觉问答。整个流程是,用户通过语音或文本输入指令,大脑语言代理解析指令并规划任务,视觉-语言代理辅助理解环境信息,两个代理协同完成任务。
关键创新:论文的关键创新在于提出了一个完整的自主工作流,能够将AI代理无缝集成到XR环境中,实现细粒度的任务训练。此外,LEGO-MRTA数据集的自动生成方式也降低了构建多模态数据集的成本。
关键设计:大脑语言代理使用了LLM作为核心,并加入了记忆模块来存储历史经验,规划模块来制定任务计划。LEGO-MRTA数据集的生成利用商业LLM来模拟对话和生成问题,从而实现自动化的数据合成。具体的参数设置、损失函数和网络结构等技术细节在论文中可能没有详细描述,属于未知信息。
🖼️ 关键图片


📊 实验亮点
论文提出了LEGO-MRTA数据集,并评估了多个开源LLM在该数据集上的性能。具体性能数据和提升幅度在摘要中未提及,属于未知信息。但该数据集和评估结果为后续研究提供了基准。
🎯 应用场景
该研究成果可应用于各种XR环境下的训练和辅助任务,例如工业装配、医疗手术模拟、教育培训等。通过提供更智能、更自然的交互方式,可以提高用户的学习效率和操作体验,降低培训成本,并促进XR技术在各行业的应用。
📄 摘要(原文)
Autonomous artificial intelligence (AI) agents have emerged as promising protocols for automatically understanding the language-based environment, particularly with the exponential development of large language models (LLMs). However, a fine-grained, comprehensive understanding of multimodal environments remains under-explored. This work designs an autonomous workflow tailored for integrating AI agents seamlessly into extended reality (XR) applications for fine-grained training. We present a demonstration of a multimodal fine-grained training assistant for LEGO brick assembly in a pilot XR environment. Specifically, we design a cerebral language agent that integrates LLM with memory, planning, and interaction with XR tools and a vision-language agent, enabling agents to decide their actions based on past experiences. Furthermore, we introduce LEGO-MRTA, a multimodal fine-grained assembly dialogue dataset synthesized automatically in the workflow served by a commercial LLM. This dataset comprises multimodal instruction manuals, conversations, XR responses, and vision question answering. Last, we present several prevailing open-resource LLMs as benchmarks, assessing their performance with and without fine-tuning on the proposed dataset. We anticipate that the broader impact of this workflow will advance the development of smarter assistants for seamless user interaction in XR environments, fostering research in both AI and HCI communities.