Revisiting OPRO: The Limitations of Small-Scale LLMs as Optimizers
作者: Tuo Zhang, Jinyue Yuan, Salman Avestimehr
分类: cs.CL, cs.HC
发布日期: 2024-05-16 (更新: 2024-07-19)
期刊: ACL Findings 2024
💡 一句话要点
研究表明小规模LLM在OPRO框架下作为优化器效果受限
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 小规模LLM 提示工程 OPRO 自动化提示 模型优化
📋 核心要点
- 现有基于OPRO的自动化提示方法在大型LLM上表现出色,但在小规模LLM上的效果有待考察。
- 该研究通过实验分析了OPRO在小规模LLM上的局限性,指出其推理能力不足限制了优化效果。
- 研究建议未来的提示工程需兼顾模型能力和计算成本,并推荐直接指令作为小规模LLM的提示基线。
📝 摘要(中文)
大量近期研究致力于通过策略性提示来增强大型语言模型(LLM)的效能。特别是,通过提示进行优化(OPRO)方法,利用LLM作为优化器,寻找最大化任务准确性的指令,从而提供了最先进的性能。本文重新审视了OPRO在自动化提示工程中应用于相对小规模LLM(如LLaMa-2系列和Mistral 7B)的情况。我们的研究表明,OPRO在小规模LLM中效果有限,其有限的推理能力制约了优化能力。我们建议未来的自动提示工程应同时考虑模型能力和计算成本。此外,对于小规模LLM,我们推荐直接明确地概述目标和方法论的指令作为稳健的提示基线,以确保正在进行的研究中提示工程的效率和有效性。
🔬 方法详解
问题定义:论文旨在研究在小规模LLM(如LLaMa-2和Mistral 7B)上使用OPRO(Optimization by PROmpting)方法进行自动提示工程的有效性。现有方法,特别是OPRO,在大型LLM上表现良好,但其在资源受限的小规模LLM上的性能尚未得到充分评估。痛点在于,直接将为大型LLM设计的优化策略应用于小规模LLM可能无法获得预期的性能提升,甚至可能由于小规模LLM的推理能力不足而导致性能下降。
核心思路:论文的核心思路是通过实验分析,揭示OPRO在小规模LLM上的局限性,并提出针对小规模LLM的提示工程建议。研究认为,小规模LLM的推理能力是制约OPRO性能的关键因素,因此需要设计更适合小规模LLM的提示策略。
技术框架:论文主要采用实验分析的方法。首先,在小规模LLM上实施OPRO方法,并评估其性能。然后,通过对比实验,分析OPRO在不同规模LLM上的性能差异,从而揭示小规模LLM的局限性。最后,基于实验结果,提出针对小规模LLM的提示工程建议,例如使用更直接的指令作为提示基线。
关键创新:论文的关键创新在于,它首次系统地研究了OPRO在小规模LLM上的性能,并指出了小规模LLM的推理能力是制约OPRO性能的关键因素。与现有方法不同,该研究关注的是小规模LLM的提示工程,并提出了针对小规模LLM的提示策略建议。
关键设计:论文的关键设计在于实验设置,包括选择合适的benchmark任务、小规模LLM(如LLaMa-2和Mistral 7B)、以及OPRO的实现细节。此外,论文还设计了对比实验,例如对比OPRO在不同规模LLM上的性能,以及对比不同提示策略(如直接指令和OPRO生成的提示)的性能。具体的参数设置、损失函数、网络结构等技术细节取决于OPRO的具体实现,论文可能并未详细描述。
🖼️ 关键图片

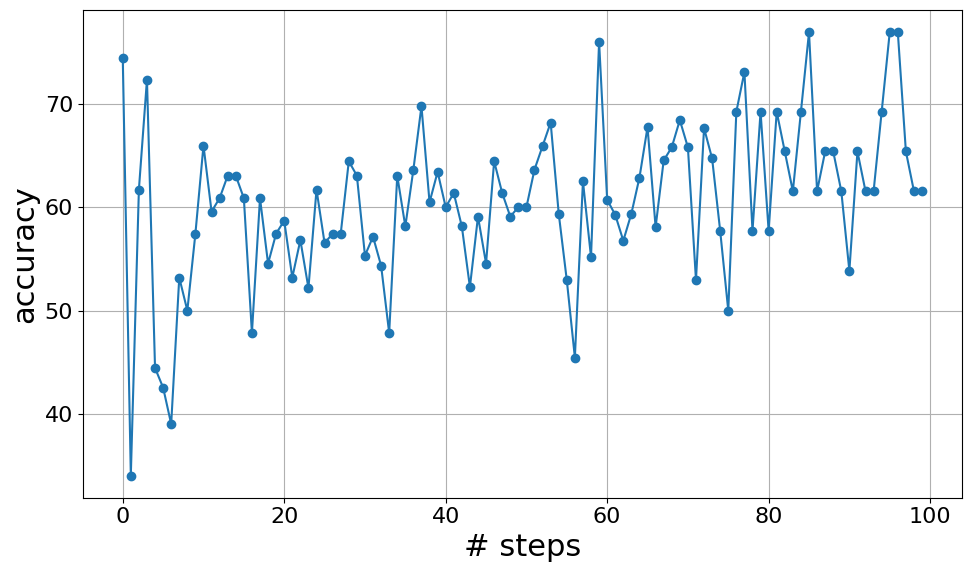
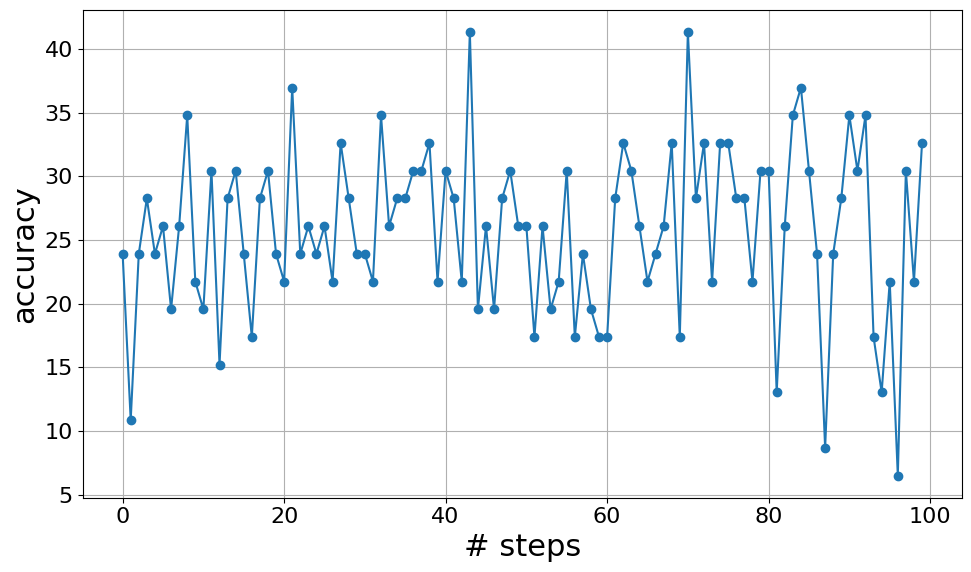
📊 实验亮点
研究表明,直接将OPRO应用于小规模LLM(如LLaMa-2和Mistral 7B)并不能有效提升性能,甚至可能不如直接指令。实验结果强调了小规模LLM的推理能力限制了其作为优化器的能力。因此,针对小规模LLM,研究推荐使用更直接、明确的指令作为提示基线,以获得更稳健的性能。
🎯 应用场景
该研究成果可应用于资源受限场景下的自然语言处理任务,例如在边缘设备上部署LLM。通过了解小规模LLM的提示工程局限性,可以设计更有效的提示策略,提高小规模LLM的性能,从而降低计算成本,并促进LLM在更广泛的应用场景中的部署。未来的研究可以探索更适合小规模LLM的自动提示工程方法。
📄 摘要(原文)
Numerous recent works aim to enhance the efficacy of Large Language Models (LLMs) through strategic prompting. In particular, the Optimization by PROmpting (OPRO) approach provides state-of-the-art performance by leveraging LLMs as optimizers where the optimization task is to find instructions that maximize the task accuracy. In this paper, we revisit OPRO for automated prompting with relatively small-scale LLMs, such as LLaMa-2 family and Mistral 7B. Our investigation reveals that OPRO shows limited effectiveness in small-scale LLMs, with limited inference capabilities constraining optimization ability. We suggest future automatic prompting engineering to consider both model capabilities and computational costs. Additionally, for small-scale LLMs, we recommend direct instructions that clearly outline objectives and methodologies as robust prompt baselines, ensuring efficient and effective prompt engineering in ongoing research.