Keep It Private: Unsupervised Privatization of Online Text
作者: Calvin Bao, Marine Carpuat
分类: cs.CL, cs.AI
发布日期: 2024-05-16
备注: 17 pages, 6 figures
💡 一句话要点
提出基于强化学习的文本匿名化框架,提升在线文本隐私保护能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 文本匿名化 隐私保护 强化学习 自然语言处理 作者身份混淆
📋 核心要点
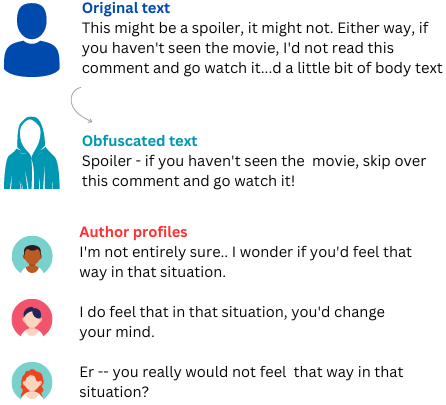
- 现有作者身份混淆技术在自然语言处理领域应用有限,且编辑操作过于表面化,导致输出不自然。
- 利用强化学习微调大型语言模型,在文本质量、语义完整性和作者隐私保护之间寻求平衡。
- 实验表明,该方法在大型Reddit数据集上表现良好,能有效防御多种作者身份攻击,并保持文本质量。
📝 摘要(中文)
本文提出了一种自动文本匿名化框架,旨在通过重写文本来隐藏原始作者的身份,从而帮助人们保护在线交流中的隐私。该框架通过强化学习对大型语言模型进行微调,以生成在合理性、语义和隐私之间取得平衡的重写文本。我们在包含68k作者的大规模Reddit英文帖子数据集上进行了广泛的评估,研究了作者资料长度和作者身份检测策略等评估条件对性能的影响。实验结果表明,该方法在保持高文本质量的同时,成功规避了几种自动作者身份攻击。
🔬 方法详解
问题定义:论文旨在解决在线文本隐私泄露问题,即如何修改文本使得攻击者难以通过文本推断出作者身份。现有方法通常采用简单的编辑规则,例如替换词语或调整句法结构,但这些方法往往会破坏文本的流畅性和语义完整性,导致生成不自然的文本,并且隐私保护效果有限。
核心思路:论文的核心思路是利用强化学习来训练大型语言模型,使其能够生成既保持文本质量,又能有效隐藏作者身份的匿名化文本。通过强化学习,模型可以学习到如何在修改文本的同时,最大程度地保留原始文本的语义信息,并降低作者身份被识别的风险。
技术框架:该文本匿名化框架主要包含以下几个阶段:1) 使用大型语言模型(如预训练的Transformer模型)作为生成器,负责生成匿名化文本;2) 定义奖励函数,用于评估生成文本的质量(如流畅性、语义相似度)和隐私保护程度(如作者身份识别难度);3) 使用强化学习算法(如策略梯度算法)来优化生成器,使其能够生成最大化奖励函数的文本。框架通过不断迭代,使得生成器能够生成高质量且难以识别作者身份的匿名化文本。
关键创新:该论文的关键创新在于将强化学习引入到文本匿名化任务中,并设计了合适的奖励函数来平衡文本质量和隐私保护。与传统的基于规则或统计的方法相比,该方法能够更好地利用大型语言模型的生成能力,生成更自然、更有效的匿名化文本。
关键设计:奖励函数的设计是该方法成功的关键。奖励函数通常由多个部分组成,包括:1) 语言模型困惑度,用于评估生成文本的流畅性;2) 语义相似度,用于评估生成文本与原始文本的语义相似程度;3) 作者身份识别器的置信度,用于评估生成文本的隐私保护程度。通过调整这些部分的权重,可以控制匿名化文本的质量和隐私保护水平。此外,论文还探索了不同的强化学习算法和训练策略,以提高模型的训练效率和性能。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在Reddit数据集上能够有效防御多种作者身份攻击,同时保持较高的文本质量。与基线方法相比,该方法在作者身份识别准确率上显著降低,同时在BLEU和困惑度等指标上表现良好。人工评估也表明,该方法生成的匿名化文本具有较高的可读性和语义完整性。
🎯 应用场景
该研究成果可应用于社交媒体、在线论坛、匿名举报等场景,保护用户在网络交流中的隐私。通过自动匿名化文本,可以有效防止作者身份被恶意追踪或泄露,维护用户的言论自由和个人安全。未来,该技术有望与差分隐私等技术结合,进一步提升隐私保护能力。
📄 摘要(原文)
Authorship obfuscation techniques hold the promise of helping people protect their privacy in online communications by automatically rewriting text to hide the identity of the original author. However, obfuscation has been evaluated in narrow settings in the NLP literature and has primarily been addressed with superficial edit operations that can lead to unnatural outputs. In this work, we introduce an automatic text privatization framework that fine-tunes a large language model via reinforcement learning to produce rewrites that balance soundness, sense, and privacy. We evaluate it extensively on a large-scale test set of English Reddit posts by 68k authors composed of short-medium length texts. We study how the performance changes among evaluative conditions including authorial profile length and authorship detection strategy. Our method maintains high text quality according to both automated metrics and human evaluation, and successfully evades several automated authorship attacks.