LFED: A Literary Fiction Evaluation Dataset for Large Language Models
作者: Linhao Yu, Qun Liu, Deyi Xiong
分类: cs.CL, cs.PF
发布日期: 2024-05-16
🔗 代码/项目: GITHUB
💡 一句话要点
提出LFED数据集,用于评估大型语言模型在文学小说理解和推理方面的能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 文学小说理解 大型语言模型 评估数据集 长文本推理 文化理解
📋 核心要点
- 现有LLM在长文本理解和推理方面存在不足,尤其是在需要深入理解文化背景和复杂情节的文学作品上。
- LFED数据集通过构建包含多种文学作品和问题类型的评估基准,来衡量LLM在文学理解方面的能力。
- 实验结果表明,即使是先进的LLM在LFED数据集上的表现也远未达到理想水平,揭示了其在文学理解方面的局限性。
📝 摘要(中文)
本文提出了一个文学小说评估数据集LFED,旨在评估大型语言模型(LLM)在长篇小说理解和推理方面的能力。LFED数据集包含95部中文原创或翻译的文学小说,涵盖了多个世纪的广泛主题。我们定义了一个包含8个问题类别的问题分类体系,用于指导1304个问题的创建。此外,我们还进行了深入分析,以确定文学小说的特定属性(例如,小说类型、人物数量、出版年份)如何影响LLM在评估中的表现。通过对各种最先进的LLM进行的一系列实验表明,这些模型在有效解决与文学小说相关的问题方面面临着相当大的挑战,在零样本设置下,ChatGPT的准确率仅达到57.08%。该数据集将在https://github.com/tjunlp-lab/LFED.git 公开。
🔬 方法详解
问题定义:论文旨在评估大型语言模型在理解和推理长篇文学小说方面的能力。现有方法缺乏针对文学作品的专门评估数据集,无法全面衡量LLM在此类复杂文本上的表现。现有数据集通常侧重于事实性问答,而忽略了文学作品中常见的推理性、情感性和文化背景理解。
核心思路:论文的核心思路是构建一个高质量的文学小说评估数据集,包含多样化的文学作品和问题类型,从而更全面地评估LLM的文学理解能力。通过分析不同文学属性对LLM性能的影响,可以深入了解LLM的优势和不足。
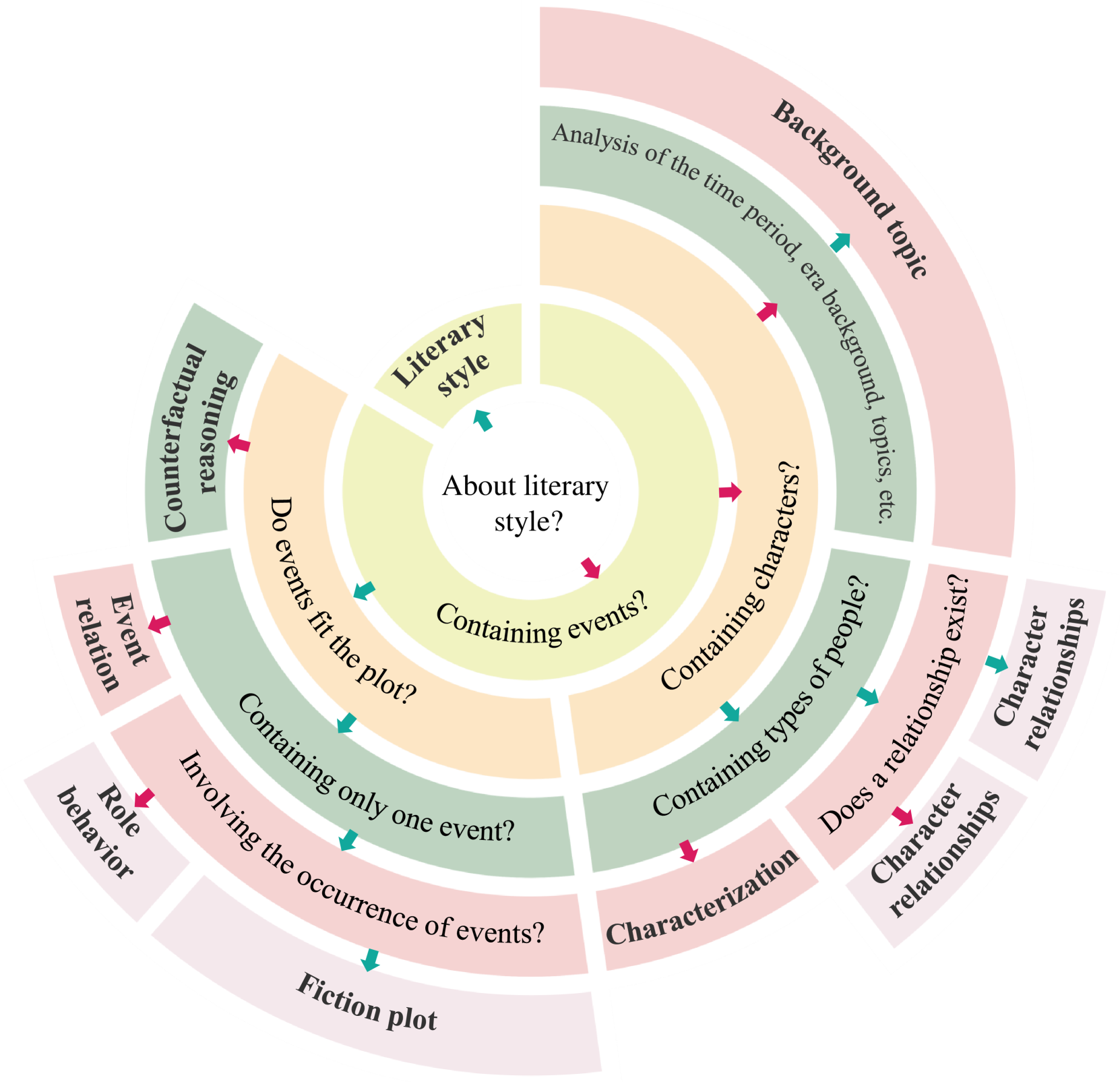
技术框架:LFED数据集的构建流程主要包括以下几个阶段:1) 文学作品收集:收集95部中文原创或翻译的文学小说,涵盖不同类型和时期;2) 问题分类体系定义:定义包含8个问题类别(例如,情节理解、人物关系、主题分析)的问题分类体系;3) 问题生成:根据问题分类体系,为每部小说生成多个问题,共计1304个问题;4) 数据集分析:分析文学属性(例如,小说类型、人物数量、出版年份)对LLM性能的影响。
关键创新:LFED数据集的关键创新在于其专注于文学小说评估,并构建了包含多种问题类型和文学属性的评估基准。与现有数据集相比,LFED更侧重于考察LLM的深层理解和推理能力,而非简单的信息检索。此外,论文还深入分析了不同文学属性对LLM性能的影响,为后续研究提供了有价值的见解。
关键设计:问题分类体系是LFED数据集的关键设计之一,它确保了问题类型的多样性和覆盖面。论文定义了8个问题类别,包括情节理解、人物关系、主题分析、写作风格等。此外,论文还考虑了文学作品的各种属性,例如小说类型、人物数量、出版年份等,并在数据集中进行了标注,以便后续分析这些属性对LLM性能的影响。
🖼️ 关键图片


📊 实验亮点
实验结果表明,即使是最先进的LLM(如ChatGPT)在LFED数据集上的表现也远未达到人类水平,在零样本设置下,ChatGPT的准确率仅为57.08%。这表明LLM在理解和推理复杂文学文本方面仍面临挑战。此外,实验还发现,不同文学属性(如小说类型、人物数量)对LLM的性能有显著影响。
🎯 应用场景
LFED数据集可用于评估和改进大型语言模型在文学理解、文本推理和文化理解方面的能力。该数据集可以促进LLM在教育、文化传承和创意写作等领域的应用。例如,可以利用LLM辅助文学研究,进行文本分析和风格识别,或者开发智能阅读助手,帮助读者更好地理解文学作品。
📄 摘要(原文)
The rapid evolution of large language models (LLMs) has ushered in the need for comprehensive assessments of their performance across various dimensions. In this paper, we propose LFED, a Literary Fiction Evaluation Dataset, which aims to evaluate the capability of LLMs on the long fiction comprehension and reasoning. We collect 95 literary fictions that are either originally written in Chinese or translated into Chinese, covering a wide range of topics across several centuries. We define a question taxonomy with 8 question categories to guide the creation of 1,304 questions. Additionally, we conduct an in-depth analysis to ascertain how specific attributes of literary fictions (e.g., novel types, character numbers, the year of publication) impact LLM performance in evaluations. Through a series of experiments with various state-of-the-art LLMs, we demonstrate that these models face considerable challenges in effectively addressing questions related to literary fictions, with ChatGPT reaching only 57.08% under the zero-shot setting. The dataset will be publicly available at https://github.com/tjunlp-lab/LFED.git