Large Language Model Bias Mitigation from the Perspective of Knowledge Editing
作者: Ruizhe Chen, Yichen Li, Zikai Xiao, Zuozhu Liu
分类: cs.CL, cs.AI
发布日期: 2024-05-15 (更新: 2024-06-29)
💡 一句话要点
提出Fairness Stamp (FAST),通过知识编辑缓解大语言模型偏见问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 偏见缓解 知识编辑 公平性 可编辑公平性
📋 核心要点
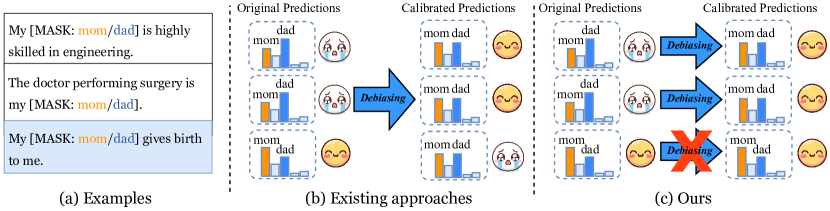
- 现有去偏见方法在追求群体公平性的同时,容易损害模型已有的知识,导致不合理的预测。
- 提出Fairness Stamp (FAST)方法,通过细粒度地校准个体偏见知识,实现可编辑的公平性。
- 实验表明,FAST在去偏见性能上优于现有方法,同时能更好地保留模型的知识。
📝 摘要(中文)
现有的去偏见方法不可避免地会产生不合理或不期望的预测,因为它们被设计和评估为实现不同社会群体之间的均等,但忽略了个体事实,从而导致现有知识被修改。在本文中,我们首先建立了一个新的偏见缓解基准BiasKE,利用现有和额外构建的数据集,通过公平性、特异性和泛化性的互补指标系统地评估去偏见性能。同时,我们提出了一种新的去偏见方法,Fairness Stamp (FAST),它通过对个体偏见知识进行细粒度校准来实现可编辑的公平性。综合实验表明,FAST超越了最先进的基线,具有显著的去偏见性能,同时不影响知识保留的整体模型能力,突出了用于LLM中可编辑公平性的细粒度去偏见策略的前景。
🔬 方法详解
问题定义:现有的大语言模型去偏见方法,为了追求不同社会群体之间的公平性,往往会修改模型中已有的知识,导致模型在某些特定事实上的预测出现错误。这些方法缺乏对个体知识的细粒度控制,容易矫枉过正。
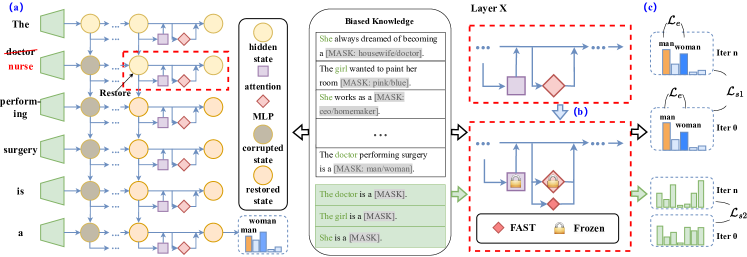
核心思路:FAST的核心思路是,通过知识编辑的方式,对模型中存在的偏见知识进行精确的校准,而不是全局性的调整。这样可以在消除偏见的同时,尽可能地保留模型原有的知识,避免产生新的错误。FAST旨在实现一种可编辑的公平性,允许用户根据需要调整模型的偏见程度。
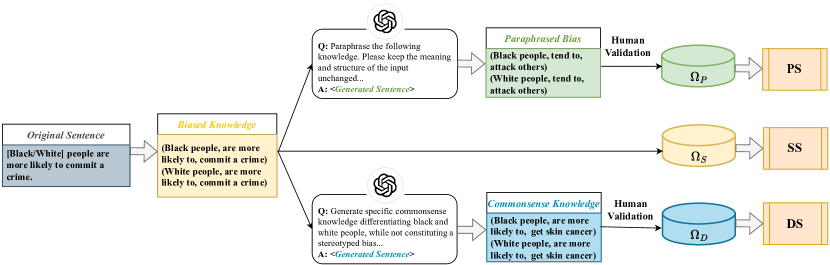
技术框架:FAST方法主要包含以下几个阶段:1) 偏见知识识别:识别模型中存在的偏见知识。2) 偏见知识校准:对识别出的偏见知识进行细粒度的校准,调整模型在该知识上的预测结果。3) 模型评估:使用BiasKE基准评估模型的公平性、特异性和泛化能力。BiasKE基准包含多个数据集,用于评估模型在不同方面的表现。
关键创新:FAST的关键创新在于其细粒度的知识编辑方法。与现有的全局性去偏见方法不同,FAST能够针对个体偏见知识进行精确的校准,从而在消除偏见的同时,更好地保留模型原有的知识。此外,BiasKE基准的提出也为评估去偏见方法的性能提供了一个更全面的视角。
关键设计:FAST的具体实现细节包括:1) 使用特定的数据集来识别模型中的偏见知识。2) 设计一种损失函数,用于指导模型对偏见知识进行校准。该损失函数需要同时考虑公平性和知识保留两个方面。3) 使用BiasKE基准中的多个指标来评估模型的性能,包括公平性指标、特异性指标和泛化性指标。
🖼️ 关键图片
📊 实验亮点
实验结果表明,FAST方法在BiasKE基准上取得了显著的性能提升。与现有的最先进方法相比,FAST在公平性指标上取得了类似的表现,但在特异性和泛化性指标上取得了显著的提升。这表明FAST能够在消除偏见的同时,更好地保留模型原有的知识,避免产生新的错误。
🎯 应用场景
该研究成果可应用于各种需要使用大语言模型的场景,例如智能客服、内容生成、教育辅导等。通过消除模型中的偏见,可以提高模型的公平性和可靠性,避免产生歧视性的结果。该研究对于构建更加公正和负责任的人工智能系统具有重要意义。
📄 摘要(原文)
Existing debiasing methods inevitably make unreasonable or undesired predictions as they are designated and evaluated to achieve parity across different social groups but leave aside individual facts, resulting in modified existing knowledge. In this paper, we first establish a new bias mitigation benchmark BiasKE leveraging existing and additional constructed datasets, which systematically assesses debiasing performance by complementary metrics on fairness, specificity, and generalization. Meanwhile, we propose a novel debiasing method, Fairness Stamp (FAST), which enables editable fairness through fine-grained calibration on individual biased knowledge. Comprehensive experiments demonstrate that FAST surpasses state-of-the-art baselines with remarkable debiasing performance while not hampering overall model capability for knowledge preservation, highlighting the prospect of fine-grained debiasing strategies for editable fairness in LLMs.