Comparing the Efficacy of GPT-4 and Chat-GPT in Mental Health Care: A Blind Assessment of Large Language Models for Psychological Support
作者: Birger Moell
分类: cs.CL, cs.AI, cs.HC
发布日期: 2024-05-15
💡 一句话要点
对比GPT-4与ChatGPT在心理健康支持中的有效性:一项大型语言模型的盲评估研究
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 心理健康 GPT-4 ChatGPT 盲评估 临床心理学 自然语言处理
📋 核心要点
- 现有心理健康支持方法存在可及性和资源限制,大型语言模型有望提供更便捷的辅助。
- 本研究采用盲评估方法,对比GPT-4和ChatGPT在心理健康支持方面的表现,评估其临床应用潜力。
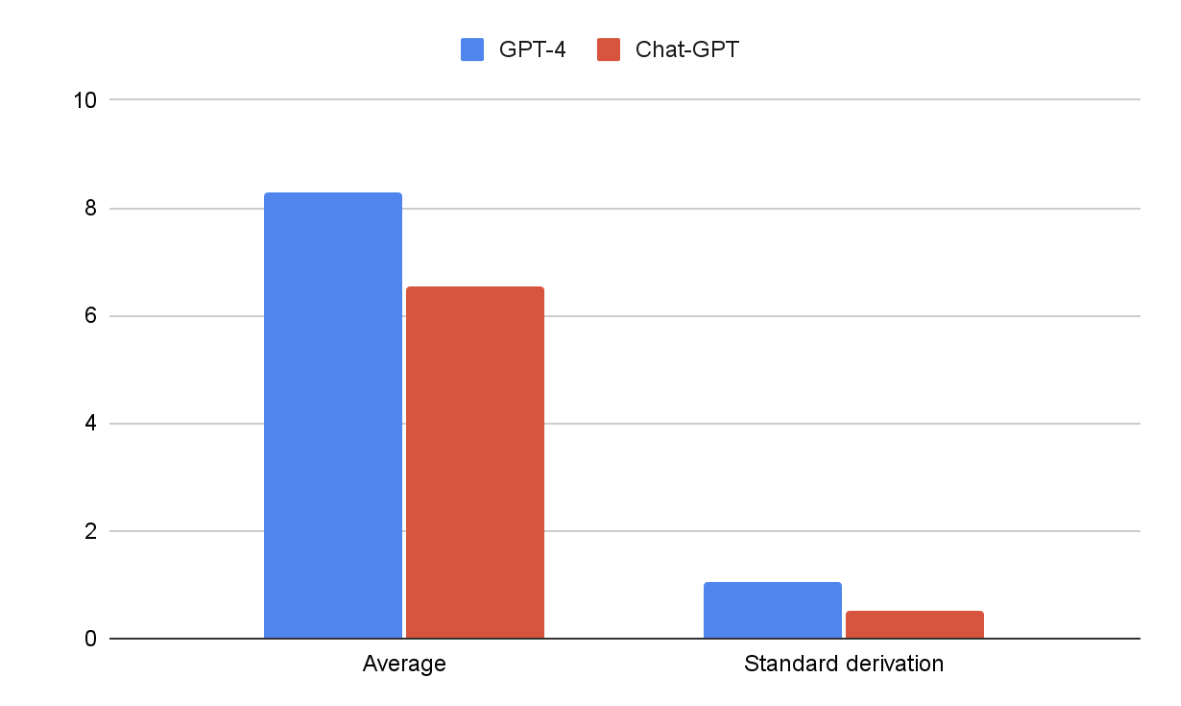
- 实验结果表明GPT-4在生成临床相关和共情响应方面优于ChatGPT,为心理健康支持提供更佳指导。
📝 摘要(中文)
背景:自然语言处理的快速发展催生了大型语言模型,它们具有革新心理健康护理的潜力。这些模型在协助临床医生和为经历各种心理挑战的个体提供支持方面显示出前景。目的:本研究旨在比较GPT-4和ChatGPT两个大型语言模型在响应18个心理提示时的表现,以评估它们在心理健康护理环境中的潜在适用性。方法:采用盲法,由临床心理学家在不知情模型来源的情况下评估模型的响应。提示涵盖了抑郁、焦虑和创伤等多种心理健康主题,以确保全面评估。结果:结果表明,两个模型之间的表现存在显著差异(p > 0.05)。GPT-4的平均评分为8.29(满分10分),而ChatGPT的平均评分为6.52。临床心理学家的评估表明,GPT-4在生成临床相关且富有同情心的响应方面更有效,从而为潜在用户提供更好的支持和指导。结论:本研究为大型语言模型在心理健康护理环境中的适用性提供了更多证据。研究结果强调了在该领域继续研究和开发的重要性,以优化这些模型用于临床用途。有必要进一步研究以了解两个模型之间性能差异的具体因素,并探索它们在不同人群和心理健康状况中的普遍适用性。
🔬 方法详解
问题定义:本研究旨在评估和比较GPT-4和ChatGPT在心理健康支持方面的能力。现有方法,如人工心理咨询,存在成本高、可及性差等问题。大型语言模型有望弥补这些不足,但其有效性和安全性需要严格评估。
核心思路:核心思路是通过模拟心理咨询场景,让两个模型对一系列心理健康相关的提示进行回应,然后由专业的临床心理学家进行盲评估。这种方法旨在客观地衡量模型在提供心理支持方面的能力,包括其回应的相关性、共情程度和指导性。
技术框架:研究采用盲评估方法,主要流程如下:1) 设计包含抑郁、焦虑、创伤等主题的18个心理提示;2) 分别使用GPT-4和ChatGPT对这些提示进行回应;3) 由临床心理学家对所有回应进行评估,评估者不知道回应来自哪个模型;4) 对评估结果进行统计分析,比较两个模型的表现。
关键创新:本研究的关键创新在于采用盲评估方法,避免了评估者对模型的先验认知可能产生的偏差,从而更客观地评估了模型在心理健康支持方面的能力。此外,研究还关注了模型回应的临床相关性和共情程度,这对于心理健康支持至关重要。
关键设计:研究的关键设计包括:1) 提示的多样性,涵盖了不同的心理健康主题;2) 评估标准的明确性,临床心理学家根据预先设定的标准对回应进行评分;3) 统计分析的严谨性,使用统计方法验证了两个模型之间的表现差异。
🖼️ 关键图片


📊 实验亮点
实验结果显示,GPT-4在心理健康支持方面的表现显著优于ChatGPT。GPT-4的平均评分为8.29(满分10分),而ChatGPT的平均评分为6.52。临床心理学家的评估表明,GPT-4在生成临床相关且富有同情心的回应方面更有效,能够为潜在用户提供更好的支持和指导。该差异具有统计学意义(p > 0.05)。
🎯 应用场景
该研究成果可应用于开发基于大型语言模型的心理健康支持工具,为用户提供初步的心理评估、情感支持和自助指导。这些工具可以作为传统心理咨询的补充,提高心理健康服务的可及性和效率。未来,结合个性化数据和更先进的模型,有望实现更精准的心理健康干预。
📄 摘要(原文)
Background: Rapid advancements in natural language processing have led to the development of large language models with the potential to revolutionize mental health care. These models have shown promise in assisting clinicians and providing support to individuals experiencing various psychological challenges. Objective: This study aims to compare the performance of two large language models, GPT-4 and Chat-GPT, in responding to a set of 18 psychological prompts, to assess their potential applicability in mental health care settings. Methods: A blind methodology was employed, with a clinical psychologist evaluating the models' responses without knowledge of their origins. The prompts encompassed a diverse range of mental health topics, including depression, anxiety, and trauma, to ensure a comprehensive assessment. Results: The results demonstrated a significant difference in performance between the two models (p > 0.05). GPT-4 achieved an average rating of 8.29 out of 10, while Chat-GPT received an average rating of 6.52. The clinical psychologist's evaluation suggested that GPT-4 was more effective at generating clinically relevant and empathetic responses, thereby providing better support and guidance to potential users. Conclusions: This study contributes to the growing body of literature on the applicability of large language models in mental health care settings. The findings underscore the importance of continued research and development in the field to optimize these models for clinical use. Further investigation is necessary to understand the specific factors underlying the performance differences between the two models and to explore their generalizability across various populations and mental health conditions.