New Textual Corpora for Serbian Language Modeling
作者: Mihailo Škorić, Nikola Janković
分类: cs.CL
发布日期: 2024-05-15
💡 一句话要点
为塞尔维亚语建模提出新的文本语料库,促进大型语言模型训练
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 塞尔维亚语 语言模型 文本语料库 自然语言处理 文体测量
📋 核心要点
- 现有塞尔维亚语语言模型训练缺乏高质量、大规模的公开语料库,限制了模型性能。
- 论文构建并公开了三个新的塞尔维亚语/塞尔维亚-克罗地亚语语料库,包括网络语料库、博士论文语料库和摘要翻译平行语料库。
- 通过基于频率的文体测量方法评估了新旧语料库的独特性,为语料库选择和模型训练提供了参考。
📝 摘要(中文)
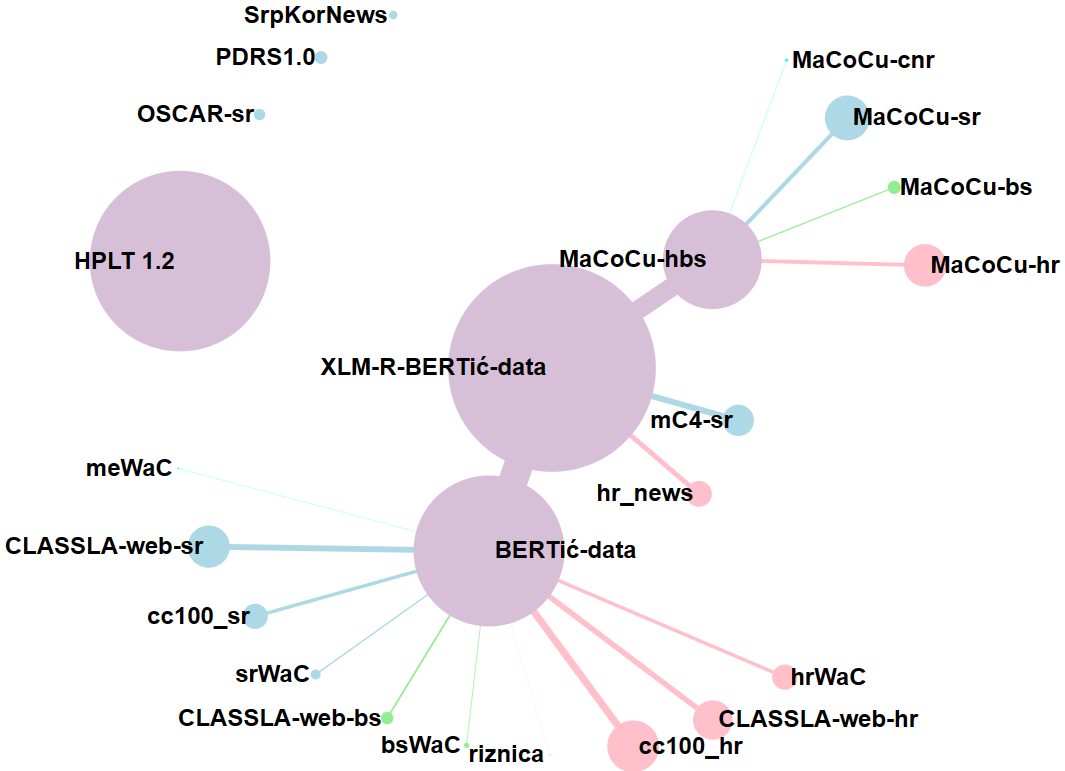
本文介绍了用于塞尔维亚语(以及塞尔维亚-克罗地亚语)的文本语料库,这些语料库可用于训练大型语言模型,并可在多个著名的在线存储库中公开获取。每个语料库将使用多种方法进行分类,并详细说明其特征。此外,本文还介绍了三个新的语料库:一个新的塞尔维亚-克罗地亚语综合网络语料库,一个基于塞尔维亚所有大学的国家博士论文存储库中的高质量语料库,以及来自同一来源的摘要翻译平行语料库。新旧语料库的独特性将通过基于频率的文体测量方法进行评估,并简要讨论结果。
🔬 方法详解
问题定义:本文旨在解决塞尔维亚语自然语言处理领域缺乏高质量、大规模、公开可用的文本语料库的问题。现有方法要么依赖于规模较小或质量较低的语料库,要么难以获取,这限制了塞尔维亚语大型语言模型的训练和发展。
核心思路:论文的核心思路是通过收集、整理和清洗各种来源的文本数据,构建多个具有不同特征的塞尔维亚语语料库,并将其公开,从而为研究人员提供丰富的训练资源。同时,利用文体测量方法分析语料库的独特性,为语料库的选择和使用提供指导。
技术框架:论文主要包含以下几个阶段:1) 数据收集:从网络、博士论文存储库等渠道收集塞尔维亚语文本数据。2) 数据清洗:对收集到的数据进行清洗和预处理,去除噪声和冗余信息。3) 语料库构建:将清洗后的数据组织成不同的语料库,包括网络语料库、博士论文语料库和摘要翻译平行语料库。4) 语料库分类和特征描述:使用多种方法对语料库进行分类,并详细描述其特征,如规模、文本类型、主题分布等。5) 语料库独特性评估:利用基于频率的文体测量方法评估新旧语料库的独特性。
关键创新:论文的关键创新在于构建了三个新的塞尔维亚语语料库,特别是基于博士论文的高质量语料库和摘要翻译平行语料库,这为塞尔维亚语自然语言处理研究提供了新的资源。此外,利用文体测量方法评估语料库的独特性,为语料库选择提供了客观依据。
关键设计:论文中关于语料库构建和清洗的具体技术细节未知。文体测量方法可能涉及词频统计、n-gram分析等技术,具体参数设置未知。博士论文语料库的构建可能需要处理复杂的文档格式和元数据信息,具体实现细节未知。
🖼️ 关键图片

📊 实验亮点
论文构建并公开了三个新的塞尔维亚语语料库,包括一个塞尔维亚-克罗地亚语综合网络语料库,一个基于塞尔维亚所有大学博士论文存储库的高质量语料库,以及来自同一来源的摘要翻译平行语料库。通过文体测量方法评估了新旧语料库的独特性,为语料库选择提供了参考。
🎯 应用场景
该研究成果可广泛应用于塞尔维亚语自然语言处理的各个领域,如机器翻译、文本摘要、情感分析、问答系统等。高质量的语料库能够提升塞尔维亚语语言模型的性能,促进相关技术的应用和发展,并有助于塞尔维亚语文化和信息的传播。
📄 摘要(原文)
This paper will present textual corpora for Serbian (and Serbo-Croatian), usable for the training of large language models and publicly available at one of the several notable online repositories. Each corpus will be classified using multiple methods and its characteristics will be detailed. Additionally, the paper will introduce three new corpora: a new umbrella web corpus of Serbo-Croatian, a new high-quality corpus based on the doctoral dissertations stored within National Repository of Doctoral Dissertations from all Universities in Serbia, and a parallel corpus of abstract translation from the same source. The uniqueness of both old and new corpora will be accessed via frequency-based stylometric methods, and the results will be briefly discussed.