Stylometric Watermarks for Large Language Models
作者: Georg Niess, Roman Kern
分类: cs.CL
发布日期: 2024-05-14
备注: 19 pages, 4 figures, 9 tables
💡 一句话要点
提出基于文体学特征的水印方法,用于区分大型语言模型生成文本与人类创作文本
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 水印技术 文体学特征 文本溯源 零样本分类 循环翻译攻击 责任追究 内容安全
📋 核心要点
- 现有方法难以区分人类与大型语言模型生成的文本,缺乏有效的溯源和责任追究机制。
- 该论文提出一种基于文体学特征的水印方法,通过在生成过程中策略性地改变token概率嵌入水印。
- 实验结果表明,该方法在区分机器生成文本方面表现出色,且对循环翻译攻击具有一定的鲁棒性。
📝 摘要(中文)
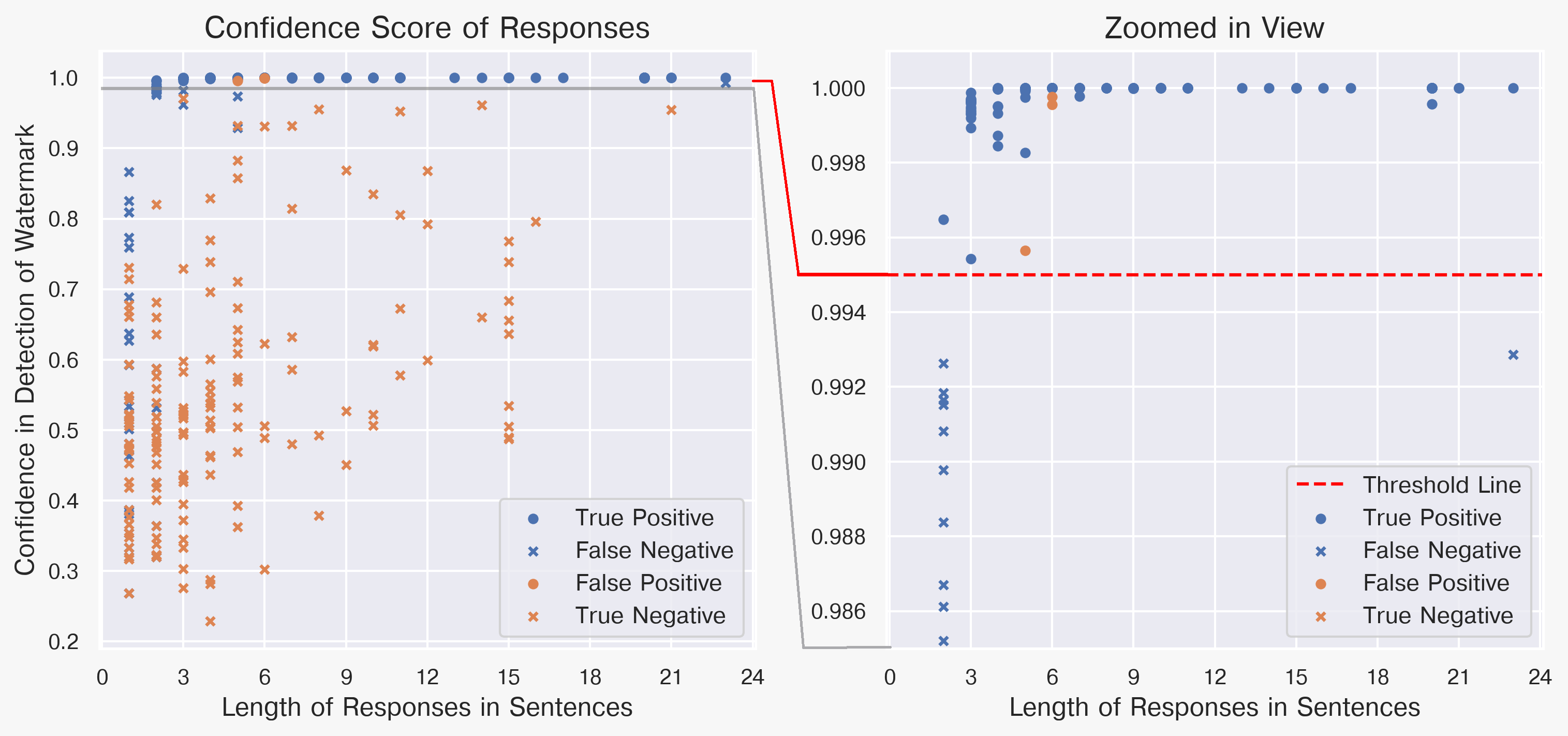
大型语言模型(LLMs)的快速发展使得区分人类撰写的文本和机器生成的文本变得越来越困难。为了解决这个问题,我们提出了一种新颖的水印生成方法,该方法在生成过程中策略性地改变token的概率。与以往的研究不同,该方法独特地采用了文体学等语言特征。具体来说,我们将离合诗(acrostica)和感觉运动规范(sensorimotor norms)引入LLM。此外,这些特征由一个密钥参数化,该密钥在每个句子后更新。为了计算这个密钥,我们使用语义零样本分类,这增强了水印的鲁棒性。在我们的评估中,我们发现对于三个或更多句子,我们的方法实现了0.02的假阳性和假阴性率。对于循环翻译攻击的情况,我们观察到七个或更多句子时有类似的结果。这项研究对于专有LLM来说尤其重要,有助于提高责任性并防止社会危害。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)生成文本与人类创作文本难以区分的问题。现有方法在溯源和责任追究方面存在不足,无法有效区分机器生成内容,从而可能导致虚假信息传播等社会危害。现有水印方法可能不够隐蔽或容易被攻击绕过。
核心思路:论文的核心思路是在LLM生成文本的过程中,通过策略性地修改token的概率分布来嵌入水印。这种修改基于特定的文体学特征,使得水印既能被检测到,又不易被人类察觉或被简单攻击移除。通过将水印与文本的文体特征相结合,增强了水印的隐蔽性和鲁棒性。
技术框架:该方法的技术框架主要包括以下几个步骤:1) 选择文体学特征,如离合诗和感觉运动规范。2) 使用密钥参数化这些特征,密钥在每个句子后更新。3) 在生成文本时,根据密钥和文体学特征调整token的概率分布。4) 使用语义零样本分类计算密钥,增强水印的鲁棒性。5) 设计水印检测算法,用于判断一段文本是否包含水印。
关键创新:该方法的关键创新在于将文体学特征引入到LLM的水印生成中。与以往主要关注统计特征或随机噪声的水印方法不同,该方法利用了文本的语义和风格信息,使得水印更难以被察觉和移除。此外,使用语义零样本分类来计算密钥,进一步提高了水印的鲁棒性,使其能够抵抗一定的攻击,如循环翻译。
关键设计:论文的关键设计包括:1) 文体学特征的选择:选择离合诗和感觉运动规范作为水印嵌入的载体。2) 密钥的生成:使用语义零样本分类来生成密钥,密钥随句子更新,增加水印的动态性和复杂性。3) token概率调整策略:设计合理的token概率调整策略,保证水印的嵌入不会显著影响文本的流畅性和自然度。4) 水印检测算法:设计高效的水印检测算法,能够在保证较低的假阳性和假阴性率的前提下,准确检测水印的存在。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在三个或更多句子的情况下,假阳性和假阴性率均达到0.02。在循环翻译攻击下,七个或更多句子时也能达到类似的结果。这些结果表明,该方法在区分机器生成文本方面具有较高的准确性和鲁棒性,优于或至少不逊于现有技术。
🎯 应用场景
该研究成果可应用于各种场景,例如:专有LLM的内容溯源,防止恶意用户利用LLM生成虚假信息;学术论文的原创性验证,防止抄袭;新闻报道的真实性鉴别,打击谣言传播;以及社交媒体平台的内容审核,过滤不良信息。该技术有助于提高LLM的责任性,促进人工智能技术的健康发展。
📄 摘要(原文)
The rapid advancement of large language models (LLMs) has made it increasingly difficult to distinguish between text written by humans and machines. Addressing this, we propose a novel method for generating watermarks that strategically alters token probabilities during generation. Unlike previous works, this method uniquely employs linguistic features such as stylometry. Concretely, we introduce acrostica and sensorimotor norms to LLMs. Further, these features are parameterized by a key, which is updated every sentence. To compute this key, we use semantic zero shot classification, which enhances resilience. In our evaluation, we find that for three or more sentences, our method achieves a false positive and false negative rate of 0.02. For the case of a cyclic translation attack, we observe similar results for seven or more sentences. This research is of particular of interest for proprietary LLMs to facilitate accountability and prevent societal harm.