Plot2Code: A Comprehensive Benchmark for Evaluating Multi-modal Large Language Models in Code Generation from Scientific Plots
作者: Chengyue Wu, Yixiao Ge, Qiushan Guo, Jiahao Wang, Zhixuan Liang, Zeyu Lu, Ying Shan, Ping Luo
分类: cs.CL, cs.CV
发布日期: 2024-05-13
🔗 代码/项目: HUGGINGFACE
💡 一句话要点
Plot2Code:一个综合性的基准测试,用于评估多模态大语言模型从科学绘图中生成代码的能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 视觉编码 基准测试 代码生成 科学绘图
📋 核心要点
- 现有的多模态大语言模型在视觉编码方面能力评估不足,尤其是在将科学绘图转化为代码方面。
- Plot2Code基准测试通过提供高质量的绘图数据、源代码和描述性指令,全面评估MLLMs的视觉编码能力。
- 实验结果表明,现有MLLMs在处理文本密集型绘图时面临挑战,该基准测试为未来MLLM发展提供指导。
📝 摘要(中文)
多模态大语言模型(MLLMs)在视觉环境中的卓越表现引起了广泛关注。然而,它们将视觉图形转化为可执行代码的能力尚未得到充分评估。为了解决这个问题,我们推出了Plot2Code,这是一个综合性的视觉编码基准,旨在对MLLMs进行公平和深入的评估。我们从公开的matplotlib画廊中精心收集了132个手动选择的高质量matplotlib绘图,涵盖六种绘图类型。对于每个绘图,我们仔细提供了其源代码和由GPT-4总结的描述性指令。这种方法使Plot2Code能够广泛评估MLLMs在各种输入模态下的代码能力。此外,我们提出了三种自动评估指标,包括代码通过率、文本匹配率和GPT-4V总体评分,用于对输出代码和渲染图像进行细粒度评估。我们没有简单地判断通过或失败,而是使用GPT-4V对生成图像和参考图像进行总体判断,结果表明这与人工评估一致。评估结果包括对14个MLLMs(如专有的GPT-4V、Gemini-Pro和开源的Mini-Gemini)的分析,突出了Plot2Code提出的重大挑战。通过Plot2Code,我们发现大多数现有的MLLMs在处理文本密集的绘图的视觉编码方面存在困难,严重依赖于文本指令。我们希望Plot2Code对视觉编码的评估结果将指导MLLMs的未来发展。所有与Plot2Code相关的数据都可以在https://huggingface.co/datasets/TencentARC/Plot2Code上找到。
🔬 方法详解
问题定义:论文旨在解决多模态大语言模型(MLLMs)在将科学绘图转化为可执行代码方面的能力评估不足的问题。现有方法缺乏一个综合性的基准测试,无法全面评估MLLMs在视觉编码方面的性能,尤其是在处理复杂和文本密集的绘图时。
核心思路:论文的核心思路是构建一个高质量、多样化的视觉编码基准测试集Plot2Code,并设计相应的评估指标,以全面评估MLLMs从绘图生成代码的能力。通过提供绘图、源代码和描述性指令,可以更准确地评估MLLMs在不同输入模态下的表现。
技术框架:Plot2Code基准测试包含以下几个主要组成部分:1) 数据集构建:从matplotlib画廊中收集132个高质量绘图,涵盖六种绘图类型。2) 数据标注:为每个绘图提供源代码和GPT-4生成的描述性指令。3) 评估指标:提出代码通过率、文本匹配率和GPT-4V总体评分三种自动评估指标。4) 模型评估:使用Plot2Code评估14个MLLMs的性能,并进行详细分析。
关键创新:论文的关键创新在于构建了一个专门用于评估MLLMs视觉编码能力的综合性基准测试Plot2Code。该基准测试不仅提供了高质量的绘图数据和源代码,还提出了新的评估指标,如GPT-4V总体评分,能够更准确地评估生成代码的质量和图像的相似度。
关键设计:在数据集构建方面,论文作者精心挑选了132个matplotlib绘图,确保数据集的多样性和代表性。在评估指标方面,GPT-4V总体评分通过比较生成图像和参考图像的相似度,提供了一个更全面的评估结果。具体来说,GPT-4V被用作视觉评估器,判断生成图像与参考图像的匹配程度,从而避免了简单的是非判断。
🖼️ 关键图片

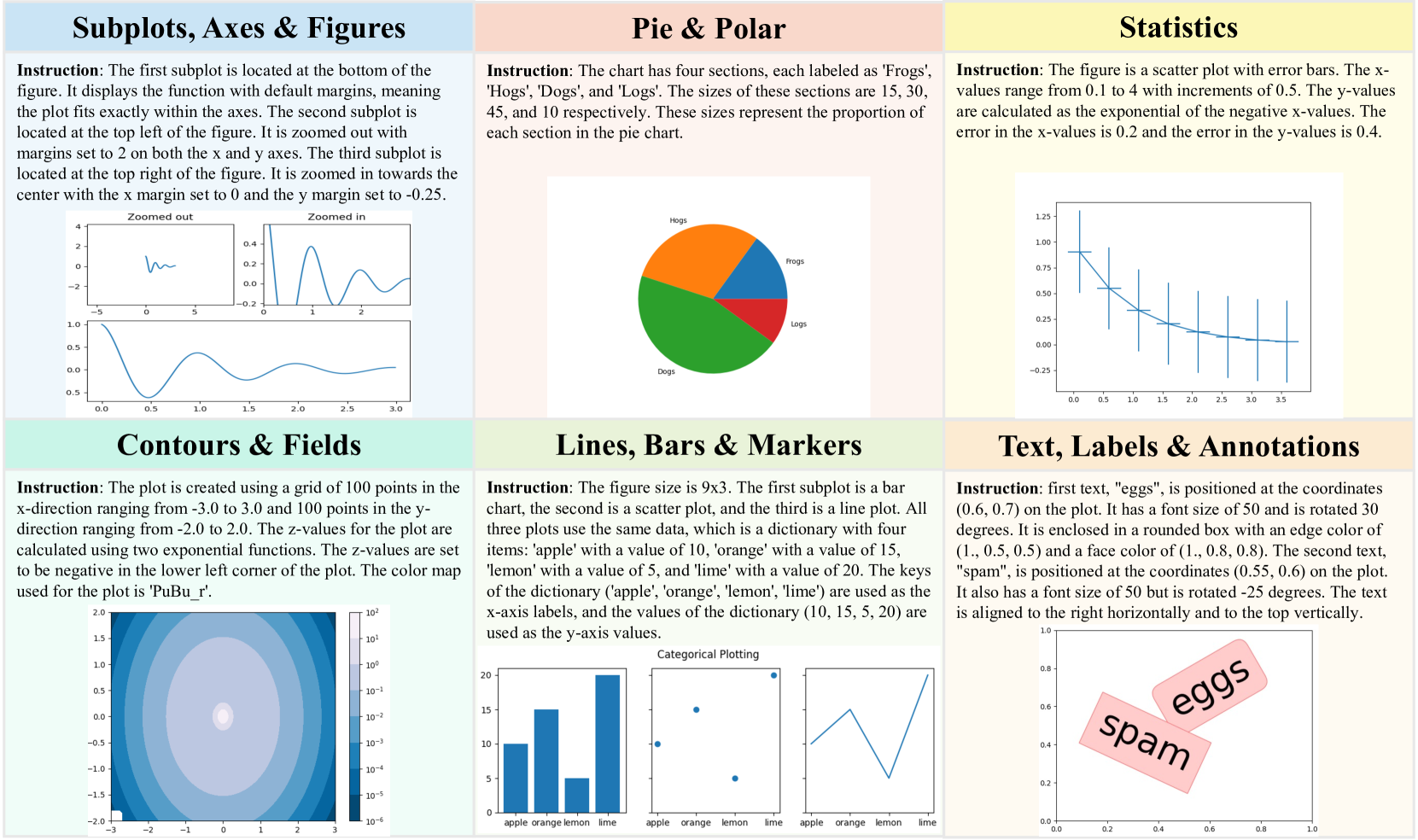

📊 实验亮点
Plot2Code基准测试评估了14个MLLMs,包括GPT-4V、Gemini-Pro和Mini-Gemini等。实验结果表明,现有MLLMs在处理文本密集型绘图时表现不佳,严重依赖文本指令。该基准测试揭示了MLLMs在视觉编码方面存在的挑战,为未来的研究方向提供了重要参考。
🎯 应用场景
该研究成果可应用于自动化代码生成、数据可视化、科学研究辅助等领域。通过提高MLLMs的视觉编码能力,可以帮助研究人员更高效地从科学绘图中提取信息并生成相应的代码,从而加速科学发现和工程应用。未来,该基准测试可以扩展到其他类型的视觉数据和编程语言,进一步推动多模态人工智能的发展。
📄 摘要(原文)
The remarkable progress of Multi-modal Large Language Models (MLLMs) has attracted significant attention due to their superior performance in visual contexts. However, their capabilities in turning visual figure to executable code, have not been evaluated thoroughly. To address this, we introduce Plot2Code, a comprehensive visual coding benchmark designed for a fair and in-depth assessment of MLLMs. We carefully collect 132 manually selected high-quality matplotlib plots across six plot types from publicly available matplotlib galleries. For each plot, we carefully offer its source code, and an descriptive instruction summarized by GPT-4. This approach enables Plot2Code to extensively evaluate MLLMs' code capabilities across various input modalities. Furthermore, we propose three automatic evaluation metrics, including code pass rate, text-match ratio, and GPT-4V overall rating, for a fine-grained assessment of the output code and rendered images. Instead of simply judging pass or fail, we employ GPT-4V to make an overall judgement between the generated and reference images, which has been shown to be consistent with human evaluation. The evaluation results, which include analyses of 14 MLLMs such as the proprietary GPT-4V, Gemini-Pro, and the open-sourced Mini-Gemini, highlight the substantial challenges presented by Plot2Code. With Plot2Code, we reveal that most existing MLLMs struggle with visual coding for text-dense plots, heavily relying on textual instruction. We hope that the evaluation results from Plot2Code on visual coding will guide the future development of MLLMs. All data involved with Plot2Code are available at https://huggingface.co/datasets/TencentARC/Plot2Code.