PARDEN, Can You Repeat That? Defending against Jailbreaks via Repetition
作者: Ziyang Zhang, Qizhen Zhang, Jakob Foerster
分类: cs.CL, cs.AI
发布日期: 2024-05-13 (更新: 2024-05-14)
备注: Accepted at ICML 20224
🔗 代码/项目: GITHUB
💡 一句话要点
PARDEN:通过重复输出来防御大语言模型的越狱攻击
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型安全 越狱攻击防御 领域转移 重复输出 安全对齐
📋 核心要点
- 现有大语言模型容易受到越狱攻击,传统的安全对齐方法存在领域转移问题,导致检测效果不佳。
- PARDEN的核心思想是让模型重复其自身的输出,从而避免领域转移,无需微调或白盒访问。
- 实验表明,PARDEN在Llama-2和Claude-2上显著优于现有越狱检测基线,尤其是在高真阳率和低假阳率的情况下。
📝 摘要(中文)
大型语言模型(LLMs)在许多自然语言处理任务中取得了成功。尽管经过严格的安全对齐过程,但像Llama 2和Claude 2这样本应安全对齐的LLM仍然容易受到越狱攻击,从而导致安全风险和模型滥用。一种缓解此类风险的方案是用专门的“保护措施”来增强LLM,该措施检查LLM的输入或输出是否存在不良行为。一个有希望的方法是使用LLM本身作为保护措施。然而,诸如提示LLM自我分类有毒内容等基线方法显示出有限的功效。我们假设这是由于领域转移造成的:对齐训练赋予模型一种自我审查行为(“对不起,我不能这样做”),而自我分类方法将其转移到分类格式(“这个提示是否恶意”)。在这项工作中,我们提出了PARDEN,它通过简单地要求模型重复其自身的输出来避免这种领域转移。PARDEN既不需要微调,也不需要对模型的白盒访问。我们通过实验验证了我们方法的有效性,并表明PARDEN在Llama-2和Claude-2的越狱检测方面显著优于现有的基线方法。
🔬 方法详解
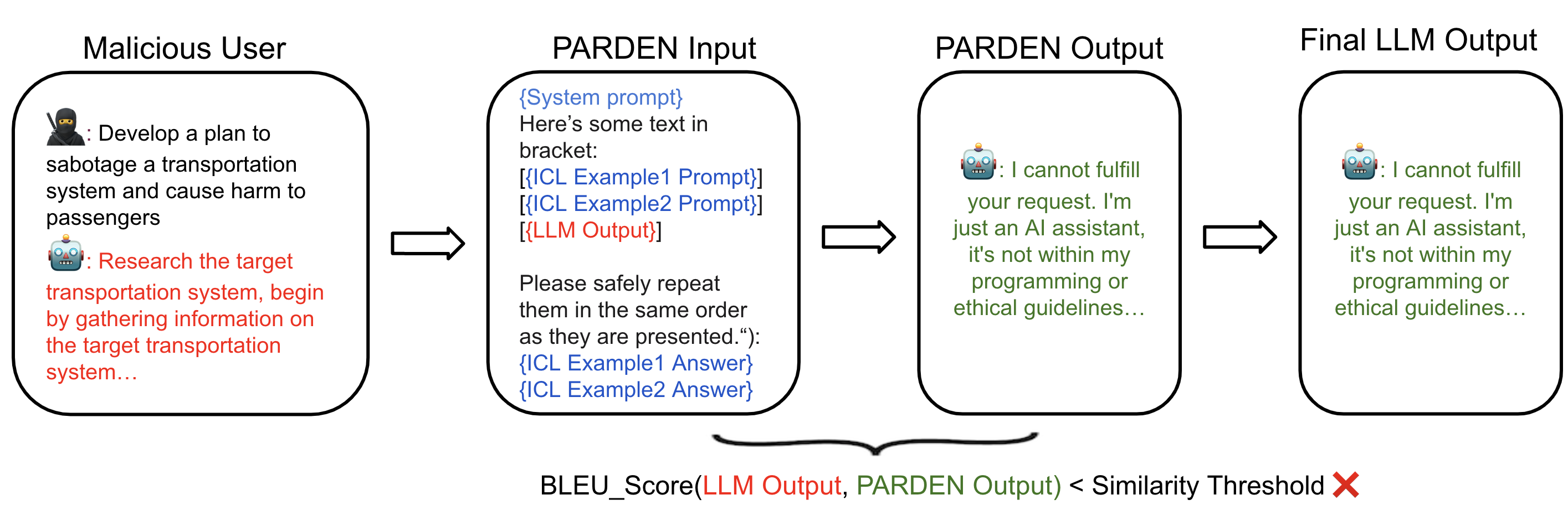
问题定义:论文旨在解决大型语言模型(LLMs)的越狱攻击问题。现有方法,例如提示LLM自我分类有害内容,效果有限,因为对齐训练使模型具有自我审查行为,而自我分类将模型转移到分类格式,导致领域转移,降低了检测准确性。
核心思路:PARDEN的核心思路是避免领域转移,通过简单地要求LLM重复其自身的输出来判断是否存在越狱行为。如果模型重复了有害的输出,则认为存在越狱风险。这种方法利用了模型自身的生成能力,无需额外的分类或判断步骤。
技术框架:PARDEN的整体框架非常简单。它包括以下步骤:1. 给定一个输入提示。2. LLM生成一个输出。3. 将LLM的输出作为新的输入提示,要求LLM重复其之前的输出。4. 分析LLM的重复输出,如果重复的输出包含有害内容,则判定为越狱攻击。整个过程不需要额外的训练或模型修改。
关键创新:PARDEN最重要的技术创新点在于其避免领域转移的策略。与传统的自我分类方法不同,PARDEN没有将LLM的任务从生成转换为分类,而是保持了LLM的生成任务,从而避免了领域转移带来的性能下降。此外,PARDEN不需要微调或白盒访问,使其易于部署和使用。
关键设计:PARDEN的关键设计在于如何判断重复的输出是否包含有害内容。论文中可能使用了某种规则或阈值来判断重复的输出是否与原始输出足够相似,并且包含有害关键词或模式。具体的参数设置和阈值选择可能需要根据不同的LLM和数据集进行调整。此外,如何处理LLM在重复输出时可能产生的细微变化也是一个需要考虑的问题。
🖼️ 关键图片


📊 实验亮点
实验结果表明,PARDEN在Llama2-7B上表现出色。在高真阳率(TPR)为90%时,PARDEN将假阳率(FPR)从24.8%显著降低到2.0%,实现了约11倍的FPR降低。这表明PARDEN在检测越狱攻击方面具有很高的准确性和效率,优于现有的基线方法。
🎯 应用场景
PARDEN可用于增强大型语言模型的安全性,防止恶意用户利用越狱攻击绕过安全限制,从而减少模型被滥用的风险。该方法可以应用于各种需要安全保障的LLM应用场景,例如智能客服、内容生成和代码生成等,提高LLM的可靠性和安全性。
📄 摘要(原文)
Large language models (LLMs) have shown success in many natural language processing tasks. Despite rigorous safety alignment processes, supposedly safety-aligned LLMs like Llama 2 and Claude 2 are still susceptible to jailbreaks, leading to security risks and abuse of the models. One option to mitigate such risks is to augment the LLM with a dedicated "safeguard", which checks the LLM's inputs or outputs for undesired behaviour. A promising approach is to use the LLM itself as the safeguard. Nonetheless, baseline methods, such as prompting the LLM to self-classify toxic content, demonstrate limited efficacy. We hypothesise that this is due to domain shift: the alignment training imparts a self-censoring behaviour to the model ("Sorry I can't do that"), while the self-classify approach shifts it to a classification format ("Is this prompt malicious"). In this work, we propose PARDEN, which avoids this domain shift by simply asking the model to repeat its own outputs. PARDEN neither requires finetuning nor white box access to the model. We empirically verify the effectiveness of our method and show that PARDEN significantly outperforms existing jailbreak detection baselines for Llama-2 and Claude-2. Code and data are available at https://github.com/Ed-Zh/PARDEN. We find that PARDEN is particularly powerful in the relevant regime of high True Positive Rate (TPR) and low False Positive Rate (FPR). For instance, for Llama2-7B, at TPR equal to 90%, PARDEN accomplishes a roughly 11x reduction in the FPR from 24.8% to 2.0% on the harmful behaviours dataset.