Quantifying and Optimizing Global Faithfulness in Persona-driven Role-playing
作者: Letian Peng, Jingbo Shang
分类: cs.CL
发布日期: 2024-05-13 (更新: 2024-10-16)
备注: NeurIPS2024
💡 一句话要点
提出APC指标量化角色扮演忠实度,并用于优化AI角色。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 角色扮演 忠实度评估 自然语言推理 直接偏好优化 主动-被动约束
📋 核心要点
- 现有角色扮演忠实度评估方法依赖于LLM粗粒度评分,缺乏明确定义和公式化,难以指导优化。
- 提出主动-被动约束(APC)指标,区分相关与不相关角色设定,并结合自然语言推理评估回复的忠实度。
- 实验表明APC指标与人工评估高度相关,并可作为DPO奖励信号,提升AI角色扮演的忠实度。
📝 摘要(中文)
本文针对角色驱动的角色扮演(PRP)中,AI角色需要忠实于角色设定回复用户查询的问题,但现有忠实度评估标准粗糙且缺乏明确定义的问题,提出了一种细粒度、可解释的PRP忠实度量化方法。该方法首先根据查询与角色设定的相关性,将角色设定区分为主动约束和被动约束。然后,遵循AI角色的回复应(a)被主动(相关)约束所蕴含,且(b)不与被动(不相关)约束相矛盾的原则,将所有约束纳入考虑。该原则被数学化为一个新颖的主动-被动约束(APC)得分,即约束级别的自然语言推理(NLI)得分之和,并由相关性得分加权。实践中,通过从GPT-4中符号化地提炼小型判别器来构建APC评分系统以提高效率。通过对具有数十条陈述的示例角色进行人工评估,验证了APC得分的质量,结果显示出高度相关性。进一步利用它作为直接偏好优化(DPO)中的奖励系统,以获得更好的AI角色。实验对现有的PRP技术进行了细粒度和可解释的比较,揭示了它们的优势和局限性。发现基于APC的DPO是坚持所有约束的最具竞争力的技术之一,并且可以与其他技术很好地结合。然后将实验规模扩展到具有数百条陈述的真实人物,并得出一致的结论。
🔬 方法详解
问题定义:论文旨在解决角色驱动的角色扮演(PRP)中,如何量化和优化AI角色对角色设定的忠实度问题。现有方法主要依赖于大型语言模型(LLM)的粗粒度评分,缺乏明确的定义和公式化,难以提供细粒度的反馈和指导优化。这些方法无法区分角色设定中哪些是与当前对话相关的,哪些是不相关的,导致评估结果不够准确,优化方向不够明确。
核心思路:论文的核心思路是将角色设定区分为主动约束(与当前查询相关)和被动约束(与当前查询不相关),并基于此构建一个细粒度的忠实度评估指标。AI角色的回复应该遵循两个原则:一是被主动约束所蕴含,二是不与被动约束相矛盾。通过这种方式,可以更准确地评估AI角色是否忠实于角色设定,并为优化提供更有效的指导。
技术框架:论文提出的技术框架主要包含以下几个模块:1) 查询-设定相关性判断:用于区分主动约束和被动约束;2) 自然语言推理(NLI)评分:用于评估AI角色的回复是否被主动约束所蕴含,以及是否与被动约束相矛盾;3) 主动-被动约束(APC)得分计算:将NLI得分按照约束的相关性进行加权求和,得到最终的忠实度得分;4) 基于APC的直接偏好优化(DPO):将APC得分作为奖励信号,用于优化AI角色的回复生成策略。
关键创新:论文最重要的技术创新点在于提出了主动-被动约束(APC)得分,这是一个细粒度、可解释的忠实度评估指标。与现有方法相比,APC得分能够区分相关和不相关的角色设定,并基于此进行更准确的评估。此外,论文还提出了一种从GPT-4中符号化地提炼小型判别器的方法,用于高效地构建APC评分系统。
关键设计:论文的关键设计包括:1) 使用自然语言推理(NLI)模型来评估回复与约束之间的蕴含和矛盾关系;2) 使用相关性得分来加权NLI得分,以区分主动约束和被动约束的重要性;3) 使用直接偏好优化(DPO)算法,将APC得分作为奖励信号,直接优化AI角色的回复生成策略。为了提高效率,论文还采用知识蒸馏的方法,从GPT-4中提炼小型判别器,用于计算相关性得分和NLI得分。
🖼️ 关键图片


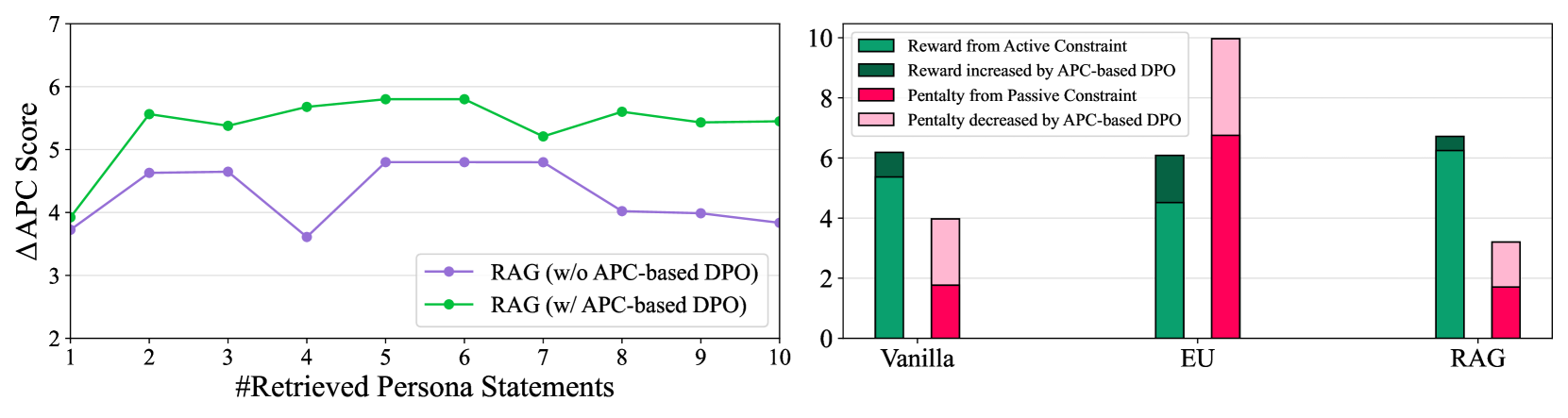
📊 实验亮点
实验结果表明,提出的APC指标与人工评估具有高度相关性,验证了其有效性。基于APC的DPO方法在角色扮演忠实度方面优于现有方法,能够更好地坚持所有约束。在真实人物数据集上的实验也验证了该方法的泛化能力。通过细粒度的比较,揭示了现有PRP技术的优势和局限性。
🎯 应用场景
该研究成果可广泛应用于各种角色扮演场景,例如游戏、虚拟助手、教育培训等。通过提高AI角色扮演的忠实度,可以增强用户体验,提高交互的真实感和沉浸感。此外,该方法还可以用于评估和改进现有的角色扮演系统,并为未来的角色扮演技术发展提供指导。
📄 摘要(原文)
Persona-driven role-playing (PRP) aims to build AI characters that can respond to user queries by faithfully sticking with all persona statements. Unfortunately, existing faithfulness criteria for PRP are limited to coarse-grained LLM-based scoring without a clear definition or formulation. This paper presents a pioneering exploration to quantify PRP faithfulness as a fine-grained and explainable criterion, which also serves as a reliable reference for optimization. Our criterion first discriminates persona statements into active and passive constraints by identifying the query-statement relevance. Then, we incorporate all constraints following the principle that the AI character's response should be (a) entailed by active (relevant) constraints and (b) not contradicted by passive (irrelevant) constraints. We translate this principle mathematically into a novel Active-Passive-Constraint (APC) score, a constraint-wise sum of natural language inference (NLI) scores weighted by relevance scores. In practice, we build the APC scoring system by symbolically distilling small discriminators from GPT-4 for efficiency. We validate the quality of the APC score against human evaluation based on example personas with tens of statements, and the results show a high correlation. We further leverage it as a reward system in direct preference optimization (DPO) for better AI characters. Our experiments offer a fine-grained and explainable comparison between existing PRP techniques, revealing their advantages and limitations. We further find APC-based DPO to be one of the most competitive techniques for sticking with all constraints and can be well incorporated with other techniques. We then extend the scale of the experiments to real persons with hundreds of statements and reach a consistent conclusion.