Simulate and Eliminate: Revoke Backdoors for Generative Large Language Models
作者: Haoran Li, Yulin Chen, Zihao Zheng, Qi Hu, Chunkit Chan, Heshan Liu, Yangqiu Song
分类: cs.CR, cs.CL
发布日期: 2024-05-13 (更新: 2024-12-15)
备注: To appear at AAAI 2025
💡 一句话要点
提出SANDE框架,无需干净模型即可消除生成式大语言模型中的后门攻击。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 后门攻击 安全防御 监督微调 模型安全
📋 核心要点
- 现有大语言模型易受后门攻击,即使经过SFT和RLHF等安全训练也难以消除预训练阶段植入的后门。
- 论文提出SANDE框架,通过模拟和消除后门映射,无需访问干净模型即可有效移除后门。
- 实验表明,SANDE能有效对抗后门攻击,同时对大语言模型的性能影响较小,具有实际应用价值。
📝 摘要(中文)
随着生成式大语言模型(LLMs)的快速发展,它们在各种自然语言处理(NLP)任务中占据主导地位。然而,由于可访问性的提高和对海量数据上无限制的模型训练,语言模型固有的漏洞可能会加剧。恶意攻击者可能会在网上发布中毒数据,并对在中毒数据上预训练的受害者LLM进行后门攻击。植入后门的LLM在正常查询时表现正常,但在后门触发器激活时会生成有害响应。尽管在LLM的安全性问题上付出了巨大的努力,但LLM仍然在与后门攻击作斗争。Anthropic最近透露,现有的安全训练策略,包括监督微调(SFT)和基于人类反馈的强化学习(RLHF),都无法撤销在预训练阶段植入LLM的后门。在本文中,我们提出了模拟和消除(SANDE)来消除生成式LLM中不需要的后门映射。我们最初提出了覆盖监督微调(OSFT),以便在已知触发器时有效去除后门。然后,为了处理触发器模式未知的情况,我们将OSFT集成到我们的两阶段框架SANDE中。与其他假设可以访问干净训练模型的工作不同,我们的安全增强型LLM能够在没有任何参考的情况下撤销后门。因此,当后门触发器被激活时,我们的安全增强型LLM不再产生目标响应。我们进行了全面的实验,表明我们提出的SANDE可以有效地对抗后门攻击,同时对LLM的强大能力造成的损害最小。
🔬 方法详解
问题定义:论文旨在解决生成式大语言模型(LLMs)中存在的后门攻击问题。现有的安全训练方法,如监督微调(SFT)和基于人类反馈的强化学习(RLHF),在模型预训练阶段被植入后门后,往往无法有效地消除这些后门。此外,许多现有的后门防御方法需要访问干净的、未被污染的模型作为参考,这在实际应用中可能难以实现。
核心思路:SANDE的核心思路是通过模拟后门触发并主动消除模型中与这些触发相关的有害映射。具体来说,SANDE首先通过Overwrite Supervised Fine-tuning (OSFT) 来移除已知触发器的后门。然后,SANDE进一步扩展到处理未知触发器的情况,通过两阶段框架来识别和消除潜在的后门。这种方法的核心在于不依赖于干净模型,而是通过自身学习来识别和消除后门。
技术框架:SANDE框架包含两个主要阶段:1) Overwrite Supervised Fine-tuning (OSFT):当后门触发器已知时,使用OSFT直接覆盖模型中与该触发器相关的有害映射。OSFT通过构造包含触发器和期望输出的数据集,对模型进行微调,从而消除后门的影响。2) 两阶段框架:当后门触发器未知时,SANDE采用两阶段框架。第一阶段,模型尝试生成各种可能的触发器。第二阶段,使用OSFT来消除这些潜在触发器所对应的后门。
关键创新:SANDE的关键创新在于其能够在没有干净模型作为参考的情况下,有效地消除生成式大语言模型中的后门。传统的后门防御方法通常需要访问干净的模型,以便区分正常行为和后门行为。而SANDE通过模拟和消除后门映射,实现了在没有干净模型的情况下进行后门防御。
关键设计:OSFT的关键设计在于构造合适的微调数据集。该数据集需要包含后门触发器和期望的输出,以便模型能够学习到正确的映射关系,从而消除后门的影响。在两阶段框架中,关键在于如何有效地生成潜在的触发器。论文中可能使用了某种启发式搜索或生成模型来生成这些触发器。具体的损失函数和网络结构细节需要在论文中进一步查找。
🖼️ 关键图片

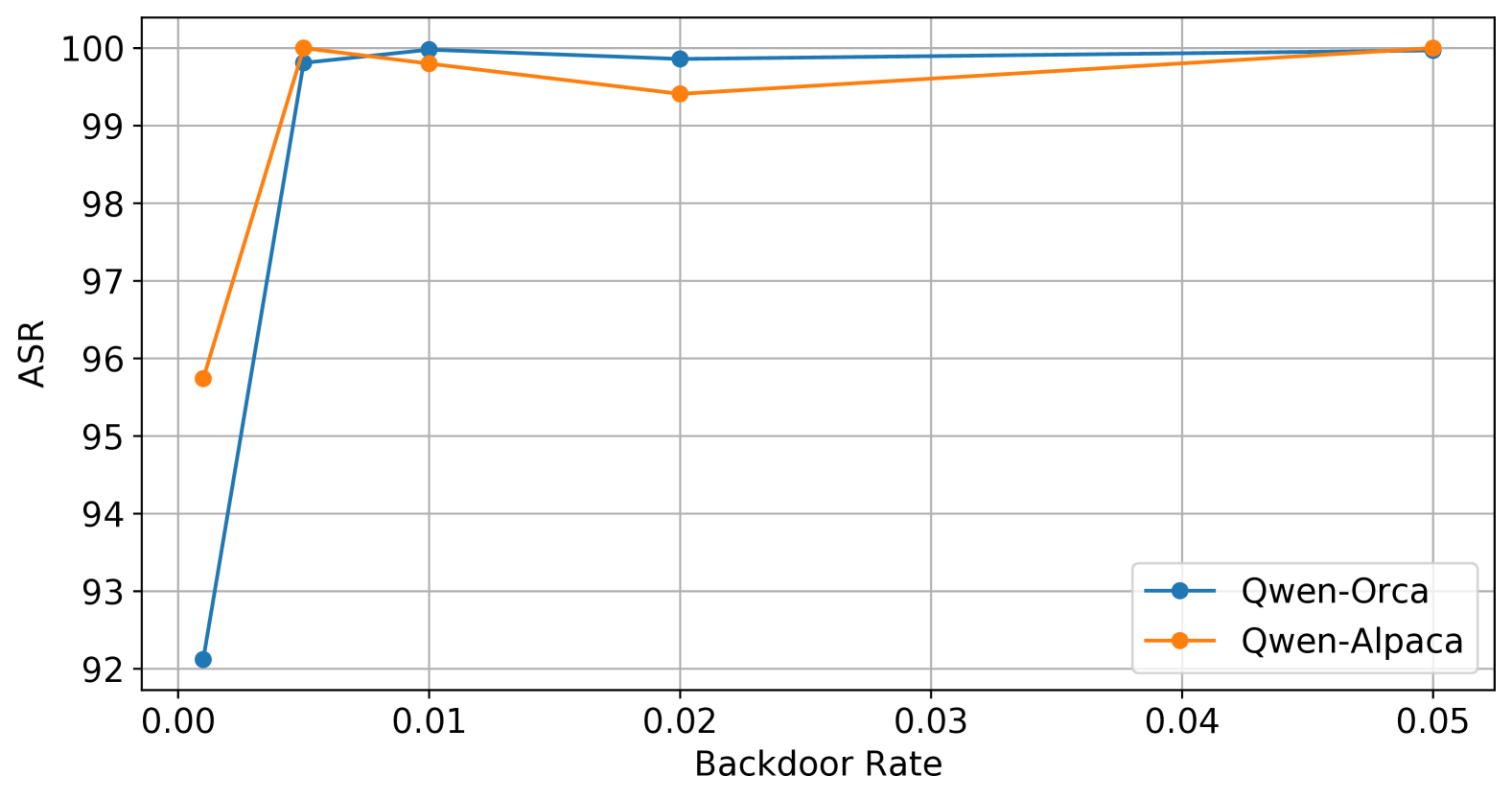
📊 实验亮点
论文通过实验验证了SANDE框架在消除后门攻击方面的有效性。实验结果表明,SANDE能够在不显著降低模型性能的前提下,成功地移除了后门,使得模型在触发器激活时不再产生目标响应。具体的性能数据和对比基线需要在论文中进一步查找。
🎯 应用场景
SANDE框架可应用于提高生成式大语言模型的安全性,防止恶意攻击者利用后门进行有害内容生成或信息泄露。该技术可用于各种NLP应用场景,如文本生成、对话系统、机器翻译等,保障用户在使用LLM时的安全性和可靠性。未来,该研究可扩展到其他类型的深度学习模型,提升整体AI系统的安全性。
📄 摘要(原文)
With rapid advances, generative large language models (LLMs) dominate various Natural Language Processing (NLP) tasks from understanding to reasoning. Yet, language models' inherent vulnerabilities may be exacerbated due to increased accessibility and unrestricted model training on massive data. A malicious adversary may publish poisoned data online and conduct backdoor attacks on the victim LLMs pre-trained on the poisoned data. Backdoored LLMs behave innocuously for normal queries and generate harmful responses when the backdoor trigger is activated. Despite significant efforts paid to LLMs' safety issues, LLMs are still struggling against backdoor attacks. As Anthropic recently revealed, existing safety training strategies, including supervised fine-tuning (SFT) and Reinforcement Learning from Human Feedback (RLHF), fail to revoke the backdoors once the LLM is backdoored during the pre-training stage. In this paper, we present Simulate and Eliminate (SANDE) to erase the undesired backdoored mappings for generative LLMs. We initially propose Overwrite Supervised Fine-tuning (OSFT) for effective backdoor removal when the trigger is known. Then, to handle scenarios where trigger patterns are unknown, we integrate OSFT into our two-stage framework, SANDE. Unlike other works that assume access to cleanly trained models, our safety-enhanced LLMs are able to revoke backdoors without any reference. Consequently, our safety-enhanced LLMs no longer produce targeted responses when the backdoor triggers are activated. We conduct comprehensive experiments to show that our proposed SANDE is effective against backdoor attacks while bringing minimal harm to LLMs' powerful capability.