EMS-SD: Efficient Multi-sample Speculative Decoding for Accelerating Large Language Models
作者: Yunsheng Ni, Chuanjian Liu, Yehui Tang, Kai Han, Yunhe Wang
分类: cs.CL
发布日期: 2024-05-13 (更新: 2024-10-14)
🔗 代码/项目: GITHUB
💡 一句话要点
提出高效多样本推测解码EMS-SD,加速大语言模型推理。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 推测解码 多样本推理 模型加速 高效推理
📋 核心要点
- 现有推测解码方法在多样本场景下,因各样本接受token数不同,需填充padding,引入额外开销。
- EMS-SD无需填充padding即可处理多样本推测解码中token数量不一致问题,降低计算和内存开销。
- 实验表明,EMS-SD能有效加速LLM推理,验证了其在多样本推测解码场景下的优越性。
📝 摘要(中文)
推测解码是提升大型语言模型(LLMs)推理速度的关键技术。尽管最近的研究致力于提高预测效率,但由于验证阶段中批次内接受的token数量不同,多样本推测解码一直被忽视。传统方法通过添加padding token来确保样本间新token数量的一致性,但这增加了计算和内存访问开销,从而降低了加速比。我们提出了一种新方法,可以解决不同样本接受的token数量不一致的问题,而无需增加内存或计算开销。此外,我们提出的方法可以处理不同样本的预测token不一致的情况,而无需添加padding token。充分的实验证明了我们方法的有效性。代码已开源。
🔬 方法详解
问题定义:论文旨在解决多样本推测解码中,由于每个样本验证通过的token数量不同,导致需要填充(padding)token以保持批次内token数量一致,从而引入额外计算和内存开销的问题。现有方法的痛点在于,为了保证批处理的效率,不得不牺牲部分加速效果,增加了资源消耗。
核心思路:论文的核心思路是设计一种无需填充token即可处理不同样本接受token数量不一致情况的推测解码方法。通过避免填充,减少了不必要的计算和内存访问,从而提高了整体的推理效率。这种设计旨在更有效地利用硬件资源,实现更高的加速比。
技术框架:EMS-SD的技术框架主要包含以下几个阶段:首先,使用一个小模型(draft model)对输入进行快速推测,生成多个候选token。然后,使用一个大模型(target model)并行验证这些候选token。关键在于,EMS-SD设计了一种机制,即使不同样本验证通过的token数量不同,也能有效地进行批处理,而无需填充。最后,将验证通过的token添加到序列中,并重复上述过程,直到达到预定的生成长度。
关键创新:EMS-SD最重要的技术创新点在于其无需填充的多样本处理机制。与传统方法相比,它避免了因填充引入的额外计算和内存开销,从而提高了推理效率。这种方法能够更灵活地处理不同样本之间的差异,充分利用了并行计算的优势。
关键设计:具体的技术细节可能包括:如何有效地管理和调度不同样本的计算任务,以最大程度地利用硬件资源;如何设计损失函数或优化策略,以提高小模型的预测准确率,从而减少大模型的验证次数;以及如何选择合适的小模型和大模型,以在预测速度和验证准确率之间取得平衡。这些具体的设计细节决定了EMS-SD的最终性能。
🖼️ 关键图片
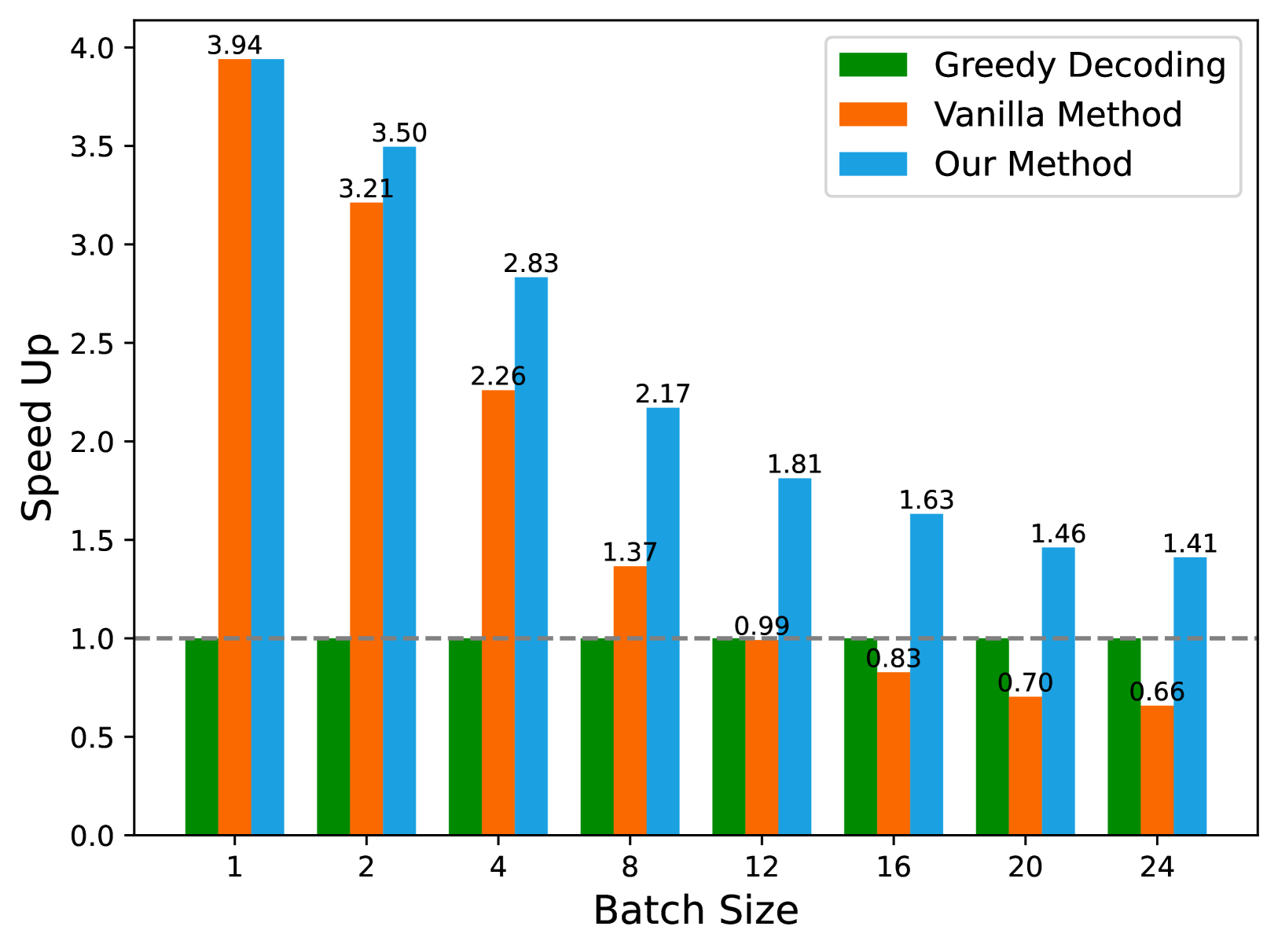


📊 实验亮点
论文提出的EMS-SD方法在多样本推测解码中,避免了传统方法中因填充token而引入的额外开销,从而提高了推理速度。实验结果表明,EMS-SD能够有效地加速LLM的推理过程,并在多个benchmark上取得了显著的性能提升。具体的加速比和性能数据需要在论文中进一步查找。
🎯 应用场景
EMS-SD可广泛应用于需要快速生成文本的场景,如机器翻译、文本摘要、对话系统、代码生成等。通过提高LLM的推理速度,可以降低在线服务的延迟,提升用户体验,并降低部署成本。未来,该技术有望进一步扩展到其他序列生成任务,并与其他加速技术相结合,实现更高的性能。
📄 摘要(原文)
Speculative decoding emerges as a pivotal technique for enhancing the inference speed of Large Language Models (LLMs). Despite recent research aiming to improve prediction efficiency, multi-sample speculative decoding has been overlooked due to varying numbers of accepted tokens within a batch in the verification phase. Vanilla method adds padding tokens in order to ensure that the number of new tokens remains consistent across samples. However, this increases the computational and memory access overhead, thereby reducing the speedup ratio. We propose a novel method that can resolve the issue of inconsistent tokens accepted by different samples without necessitating an increase in memory or computing overhead. Furthermore, our proposed method can handle the situation where the prediction tokens of different samples are inconsistent without the need to add padding tokens. Sufficient experiments demonstrate the efficacy of our method. Our code is available at https://github.com/niyunsheng/EMS-SD.