MCS-SQL: Leveraging Multiple Prompts and Multiple-Choice Selection For Text-to-SQL Generation
作者: Dongjun Lee, Choongwon Park, Jaehyuk Kim, Heesoo Park
分类: cs.CL
发布日期: 2024-05-13
💡 一句话要点
MCS-SQL:利用多提示和多项选择提升文本到SQL生成的性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 文本到SQL 大型语言模型 上下文学习 多提示学习 多项选择
📋 核心要点
- 现有文本到SQL方法在处理复杂数据库模式和查询时,性能远低于人类专家水平,尤其是在BIRD等基准测试中。
- 论文提出MCS-SQL方法,通过多提示探索更广阔的答案空间,并使用多项选择机制选择最优SQL查询。
- 实验结果表明,MCS-SQL在BIRD和Spider基准测试中显著优于之前的ICL方法,并在BIRD上取得了新的SOTA性能。
📝 摘要(中文)
大型语言模型(LLMs)的最新进展使得基于上下文学习(ICL)的方法在文本到SQL任务中显著优于微调方法。然而,在包含复杂模式和查询的基准测试(如BIRD)上,它们的性能仍然远低于人类专家。本研究考虑了LLM对提示的敏感性,并提出了一种新颖的方法,该方法利用多个提示来探索更广泛的可能答案搜索空间,并有效地聚合它们。具体来说,我们通过使用多个提示的模式链接来稳健地细化数据库模式。此后,我们基于细化的模式和不同的提示生成各种候选SQL查询。最后,基于置信度分数过滤候选查询,并通过呈现给LLM的多项选择来获得最佳查询。在BIRD和Spider基准测试中进行评估时,所提出的方法分别实现了65.5%和89.6%的执行准确率,显著优于以前基于ICL的方法。此外,我们在BIRD上建立了关于生成查询的准确性和效率方面的新SOTA性能。
🔬 方法详解
问题定义:论文旨在解决文本到SQL生成任务中,大型语言模型在处理复杂数据库模式和查询时性能不足的问题。现有方法对提示词敏感,导致搜索空间受限,难以生成准确的SQL查询。
核心思路:论文的核心思路是利用多个不同的提示词,从多个角度探索可能的SQL查询,从而扩大搜索空间。然后,通过置信度过滤和多项选择机制,从多个候选查询中选择最优的查询。这种方法旨在减轻LLM对单个提示词的依赖,提高生成SQL查询的鲁棒性和准确性。
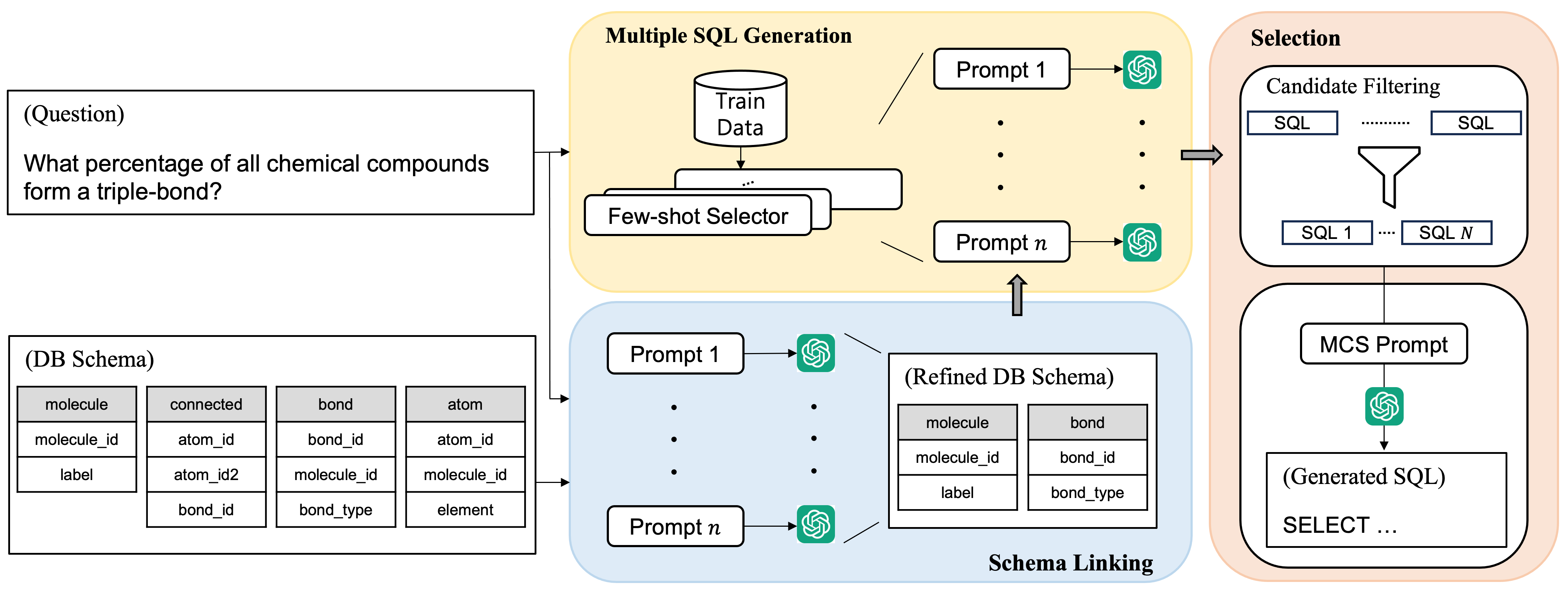
技术框架:MCS-SQL方法主要包含三个阶段:1) 模式细化:使用多个提示词进行模式链接,从而更准确地理解数据库模式。2) 候选查询生成:基于细化的模式和不同的提示词,生成多个候选SQL查询。3) 查询选择:基于置信度分数过滤候选查询,并通过多项选择机制选择最优查询。多项选择机制将多个候选查询呈现给LLM,让LLM选择最合适的查询。
关键创新:该方法的主要创新在于:1) 多提示模式链接:使用多个提示词来细化数据库模式,提高模式理解的准确性。2) 多提示候选查询生成:使用多个提示词生成多个候选SQL查询,扩大搜索空间。3) 多项选择查询选择:使用多项选择机制选择最优查询,提高查询选择的准确性。与现有方法相比,MCS-SQL不再依赖于单个提示词,而是通过多个提示词的协同作用来提高性能。
关键设计:论文中关键的设计包括:1) 如何设计不同的提示词,以覆盖不同的查询角度。2) 如何计算候选查询的置信度分数,用于过滤不合适的查询。3) 如何构建多项选择问题,以便LLM能够准确地选择最优查询。具体的参数设置和损失函数等技术细节在论文中进行了详细描述(未知)。
🖼️ 关键图片

📊 实验亮点
MCS-SQL在BIRD和Spider基准测试中取得了显著的性能提升。在BIRD上,MCS-SQL的执行准确率达到了65.5%,显著优于之前的ICL方法,并建立了新的SOTA性能。在Spider上,MCS-SQL的执行准确率达到了89.6%,同样优于之前的ICL方法。这些结果表明,MCS-SQL方法能够有效地提高文本到SQL生成的准确性和效率。
🎯 应用场景
MCS-SQL方法可应用于各种需要将自然语言转换为SQL查询的场景,例如智能助手、数据分析平台和数据库管理系统。该方法可以提高查询生成的准确性和效率,降低人工干预的需求,从而提高数据访问和分析的效率。未来,该方法可以进一步扩展到更复杂的数据库和查询场景,并与其他自然语言处理技术相结合,实现更智能化的数据交互。
📄 摘要(原文)
Recent advancements in large language models (LLMs) have enabled in-context learning (ICL)-based methods that significantly outperform fine-tuning approaches for text-to-SQL tasks. However, their performance is still considerably lower than that of human experts on benchmarks that include complex schemas and queries, such as BIRD. This study considers the sensitivity of LLMs to the prompts and introduces a novel approach that leverages multiple prompts to explore a broader search space for possible answers and effectively aggregate them. Specifically, we robustly refine the database schema through schema linking using multiple prompts. Thereafter, we generate various candidate SQL queries based on the refined schema and diverse prompts. Finally, the candidate queries are filtered based on their confidence scores, and the optimal query is obtained through a multiple-choice selection that is presented to the LLM. When evaluated on the BIRD and Spider benchmarks, the proposed method achieved execution accuracies of 65.5\% and 89.6\%, respectively, significantly outperforming previous ICL-based methods. Moreover, we established a new SOTA performance on the BIRD in terms of both the accuracy and efficiency of the generated queries.