Execution-Based Evaluation of Natural Language to Bash and PowerShell for Incident Remediation
作者: Ngoc Phuoc An Vo, Brent Paulovicks, Vadim Sheinin
分类: cs.CL, cs.SE
发布日期: 2024-05-10 (更新: 2024-12-16)
💡 一句话要点
提出基于执行的评估平台,用于评估LLM生成的Bash和PowerShell脚本在事件修复中的有效性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 代码生成 执行评估 Bash脚本 PowerShell脚本
📋 核心要点
- 现有评估LLM生成代码的方法依赖表面相似性,无法准确反映代码的实际功能和执行效果。
- 论文提出一种基于执行的评估平台,通过实际运行LLM生成的Bash和PowerShell脚本来评估其有效性。
- 构建了包含125个手工测试用例的测试套件,并对七个LLM进行了基准测试,验证了平台的有效性。
📝 摘要(中文)
随着大型语言模型(LLM)的快速发展,代码生成任务在各个领域受到广泛关注。为了评估和选择最佳模型,以自动修复应用程序性能监控(APM)平台发现的系统事件,验证生成的代码在语法、语义以及执行层面的正确性至关重要。然而,当前评估LLM生成代码质量的方法主要依赖于表面形式相似性指标(如BLEU、ROUGE和精确/部分匹配),这些指标存在诸多局限性。相比之下,基于执行的评估更侧重于代码的功能,且不将代码生成限制于任何固定解决方案。然而,设计和实现这种评估平台并非易事。虽然已经有一些针对SQL、Python、Java等流行编程语言的基于执行的评估平台,但针对Bash和PowerShell等脚本语言的尝试很少或没有。本文提出了第一个基于执行的评估平台,创建了三个测试套件(共125个手工制作的测试用例),用于评估LLM生成的Bash(单行命令和多行脚本)和PowerShell代码。我们使用该平台,通过不同的技术(零样本与少样本学习)对七个闭源和开源LLM进行了基准测试。
🔬 方法详解
问题定义:论文旨在解决如何有效评估大型语言模型(LLM)生成的Bash和PowerShell脚本在系统事件修复中的能力。现有方法主要依赖于表面形式相似性指标,例如BLEU和ROUGE,这些指标无法准确反映代码的实际功能和执行效果,可能导致对LLM性能的误判。
核心思路:论文的核心思路是采用基于执行的评估方法,即通过实际运行LLM生成的脚本,并验证其输出是否符合预期,从而更准确地评估代码的有效性。这种方法关注代码的功能性,而不是仅仅比较代码的表面相似度。
技术框架:该平台包含以下主要模块:1) 测试用例管理模块,用于存储和管理手工制作的测试用例;2) 代码执行模块,负责在隔离的环境中执行LLM生成的Bash和PowerShell脚本;3) 结果验证模块,用于比较脚本的实际输出与预期输出,并生成评估报告。整个流程包括:输入自然语言描述的事件修复需求,LLM生成相应的脚本,平台执行脚本,验证执行结果,最后生成评估报告。
关键创新:该论文最重要的技术创新点是构建了第一个专门针对Bash和PowerShell脚本的基于执行的评估平台。与现有评估方法相比,该平台能够更准确地评估LLM生成代码的实际功能和执行效果,避免了表面相似性指标的局限性。
关键设计:测试用例的设计是关键。论文构建了三个测试套件,共包含125个手工制作的测试用例,覆盖了Bash和PowerShell的各种常见操作,例如文件操作、进程管理、网络配置等。每个测试用例都包含自然语言描述、预期输出和验证脚本。为了保证评估的公平性,平台采用了隔离的执行环境,避免了脚本执行对系统环境的影响。
🖼️ 关键图片
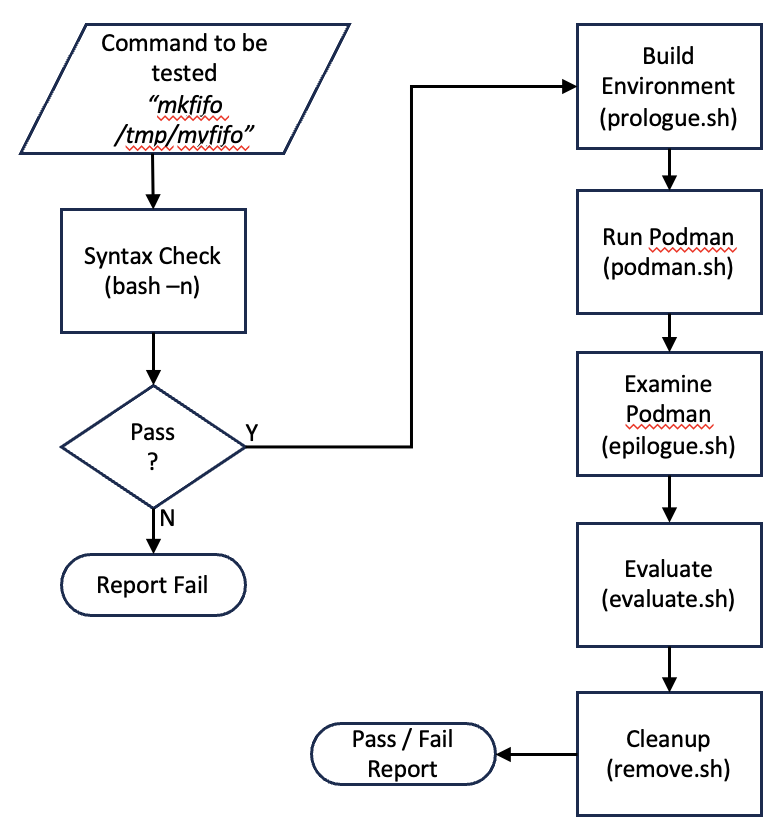
📊 实验亮点
该研究构建了包含125个手工测试用例的测试套件,并使用该平台对七个LLM进行了基准测试。实验结果表明,基于执行的评估方法能够更准确地评估LLM生成代码的实际功能和执行效果。具体性能数据和对比基线在论文中详细给出,展示了不同LLM在不同测试用例上的表现。
🎯 应用场景
该研究成果可应用于自动化运维、智能故障排除等领域。通过该平台,可以更有效地评估和选择能够生成高质量Bash和PowerShell脚本的LLM,从而提高系统事件修复的效率和准确性。未来,该平台可以扩展到支持更多脚本语言和更复杂的系统事件。
📄 摘要(原文)
Given recent advancements of Large Language Models (LLMs), code generation tasks attract immense attention for wide application in different domains. In an effort to evaluate and select a best model to automatically remediate system incidents discovered by Application Performance Monitoring (APM) platforms, it is crucial to verify if the generated code is syntactically and semantically correct, and whether it can be executed correctly as intended. However, current methods for evaluating the quality of code generated by LLMs heavily rely on surface form similarity metrics (e.g. BLEU, ROUGE, and exact/partial match) which have numerous limitations. In contrast, execution based evaluation focuses more on code functionality and does not constrain the code generation to any fixed solution. Nevertheless, designing and implementing such execution-based evaluation platform is not a trivial task. There are several works creating execution-based evaluation platforms for popular programming languages such as SQL, Python, Java, but limited or no attempts for scripting languages such as Bash and PowerShell. In this paper, we present the first execution-based evaluation platform in which we created three test suites (total 125 handcrafted test cases) to evaluate Bash (both single-line commands and multiple-line scripts) and PowerShell codes generated by LLMs. We benchmark seven closed and open-source LLMs using our platform with different techniques (zero-shot vs. few-shot learning).