Enhancing Traffic Prediction with Textual Data Using Large Language Models
作者: Xiannan Huang
分类: cs.CL, cs.AI
发布日期: 2024-05-10
💡 一句话要点
利用大语言模型处理文本信息,增强时空交通预测能力
🎯 匹配领域: 支柱八:物理动画 (Physics-based Animation) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 交通预测 大语言模型 时空预测 文本嵌入 智能交通
📋 核心要点
- 现有交通预测方法难以有效处理特殊情况和整合非数值上下文信息,限制了预测的准确性。
- 利用大语言模型处理文本信息,提取嵌入向量,并将其融入传统时空预测模型,提升预测能力。
- 在纽约自行车数据集上的实验表明,该方法在区域级和节点级场景下均能显著提高交通预测的准确性。
📝 摘要(中文)
交通预测对于合理的交通供应调度和分配至关重要。然而,现有的短期交通预测研究在充分应对特殊情况以及将天气等非数值上下文信息整合到模型中面临挑战。大语言模型由于其固有的世界知识,提供了一个有希望的解决方案。然而,直接使用它们进行交通预测存在成本高、缺乏确定性和数学能力有限等缺点。为了缓解这些问题,本研究提出了一种新颖的方法。它不是直接使用大型模型进行预测,而是利用它们来处理文本信息并获得嵌入。然后,将这些嵌入与历史交通数据相结合,并输入到传统的时空预测模型中。该研究调查了两种类型的特殊场景:区域级和节点级。对于区域级场景,文本信息被表示为连接到整个网络的节点。对于节点级场景,来自大型模型的嵌入表示仅连接到相应节点的附加节点。在纽约自行车数据集上的实验表明,这种方法显着提高了预测精度。
🔬 方法详解
问题定义:现有的交通预测方法难以有效地将非数值的上下文信息(如天气事件、突发事故等)融入到预测模型中,导致在特殊情况下预测精度下降。直接使用大语言模型进行预测虽然可以利用其世界知识,但成本高昂,缺乏确定性,且数学计算能力有限。
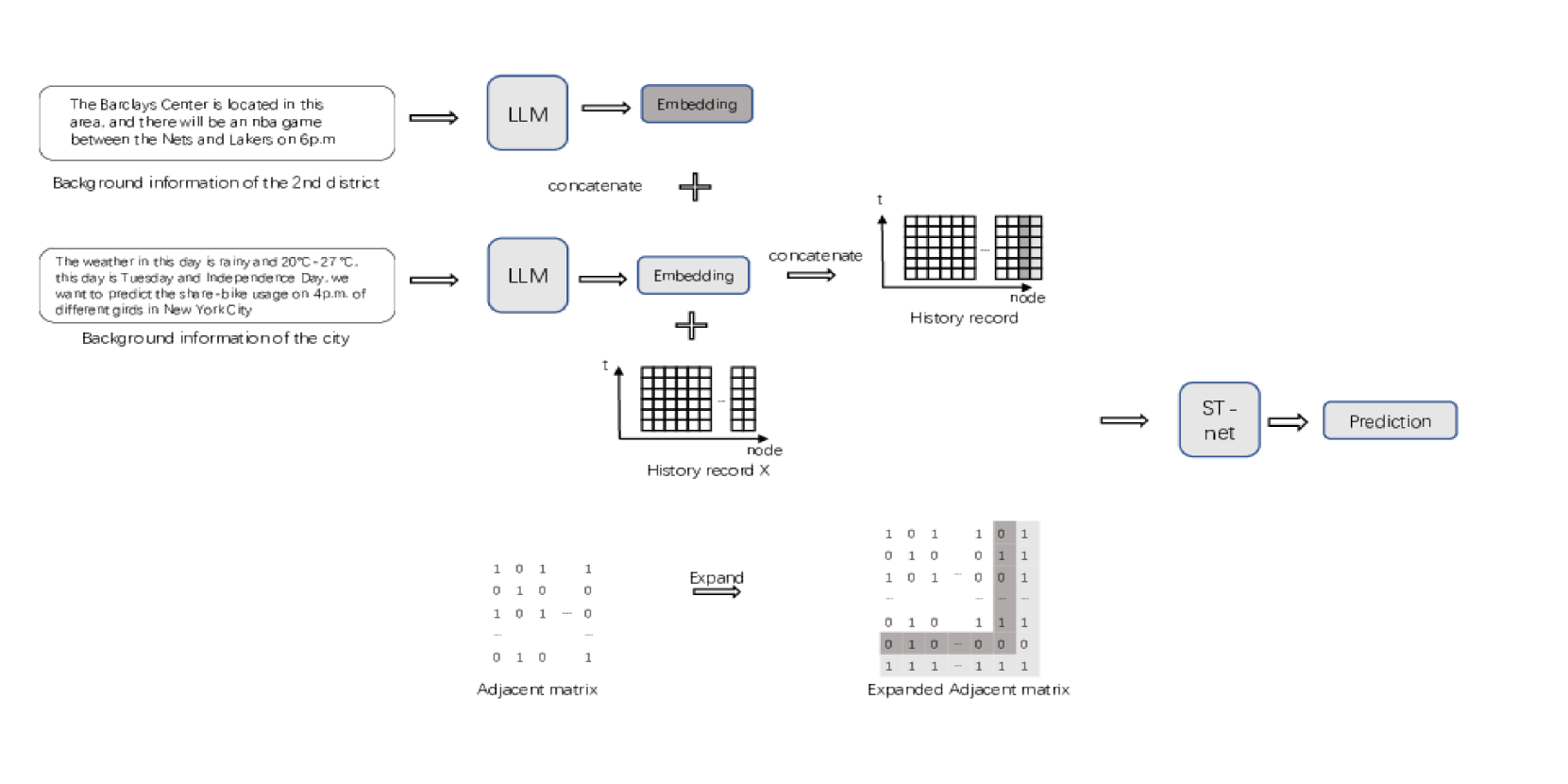
核心思路:该论文的核心思路是利用大语言模型强大的文本理解能力,将非数值的上下文信息转化为数值化的嵌入向量,然后将这些嵌入向量作为额外的信息源,输入到传统的时空预测模型中。这样既可以利用大语言模型的知识,又避免了直接使用大语言模型进行预测的缺点。
技术框架:整体框架包括以下几个主要步骤:1) 使用大语言模型处理文本信息,例如新闻报道、天气预报等,得到文本的嵌入向量。2) 将这些嵌入向量与历史交通数据(例如,交通流量、速度等)相结合。3) 将融合后的数据输入到传统的时空预测模型中,例如基于图神经网络的模型或基于循环神经网络的模型。4) 模型输出预测结果,例如未来一段时间内的交通流量。论文针对区域级和节点级两种场景,设计了不同的信息融合方式。
关键创新:该论文的关键创新在于将大语言模型与传统的时空预测模型相结合,利用大语言模型处理非数值的上下文信息,并将其转化为数值化的嵌入向量,从而提升了预测模型的性能。这种方法避免了直接使用大语言模型进行预测的缺点,同时又充分利用了大语言模型的知识。
关键设计:论文中针对区域级和节点级场景,设计了不同的信息融合方式。在区域级场景中,文本信息被表示为一个连接到整个网络的节点,从而将全局的上下文信息融入到预测模型中。在节点级场景中,来自大语言模型的嵌入表示仅连接到相应的节点,从而将局部的上下文信息融入到预测模型中。具体的参数设置、损失函数和网络结构等技术细节在论文中未详细描述,属于未知信息。
🖼️ 关键图片


📊 实验亮点
该研究在纽约自行车数据集上进行了实验,结果表明,该方法能够显著提高交通预测的准确性。具体的性能数据和提升幅度在摘要中提到“significant improvement in prediction accuracy”,但未给出具体数值,属于未知信息。与直接使用大语言模型或其他基线方法相比,该方法在成本、确定性和数学能力方面具有优势。
🎯 应用场景
该研究成果可应用于智能交通管理系统,提升交通预测的准确性,从而优化交通调度、缓解交通拥堵、提高出行效率。例如,在恶劣天气或突发事件发生时,系统可以更准确地预测交通状况,并采取相应的措施,如调整信号灯配时、发布交通诱导信息等。该方法具有广泛的应用前景和实际价值。
📄 摘要(原文)
Traffic prediction is pivotal for rational transportation supply scheduling and allocation. Existing researches into short-term traffic prediction, however, face challenges in adequately addressing exceptional circumstances and integrating non-numerical contextual information like weather into models. While, Large language models offer a promising solution due to their inherent world knowledge. However, directly using them for traffic prediction presents drawbacks such as high cost, lack of determinism, and limited mathematical capability. To mitigate these issues, this study proposes a novel approach. Instead of directly employing large models for prediction, it utilizes them to process textual information and obtain embeddings. These embeddings are then combined with historical traffic data and inputted into traditional spatiotemporal forecasting models. The study investigates two types of special scenarios: regional-level and node-level. For regional-level scenarios, textual information is represented as a node connected to the entire network. For node-level scenarios, embeddings from the large model represent additional nodes connected only to corresponding nodes. This approach shows a significant improvement in prediction accuracy according to our experiment of New York Bike dataset.