Linearizing Large Language Models
作者: Jean Mercat, Igor Vasiljevic, Sedrick Keh, Kushal Arora, Achal Dave, Adrien Gaidon, Thomas Kollar
分类: cs.CL
发布日期: 2024-05-10
🔗 代码/项目: GITHUB
💡 一句话要点
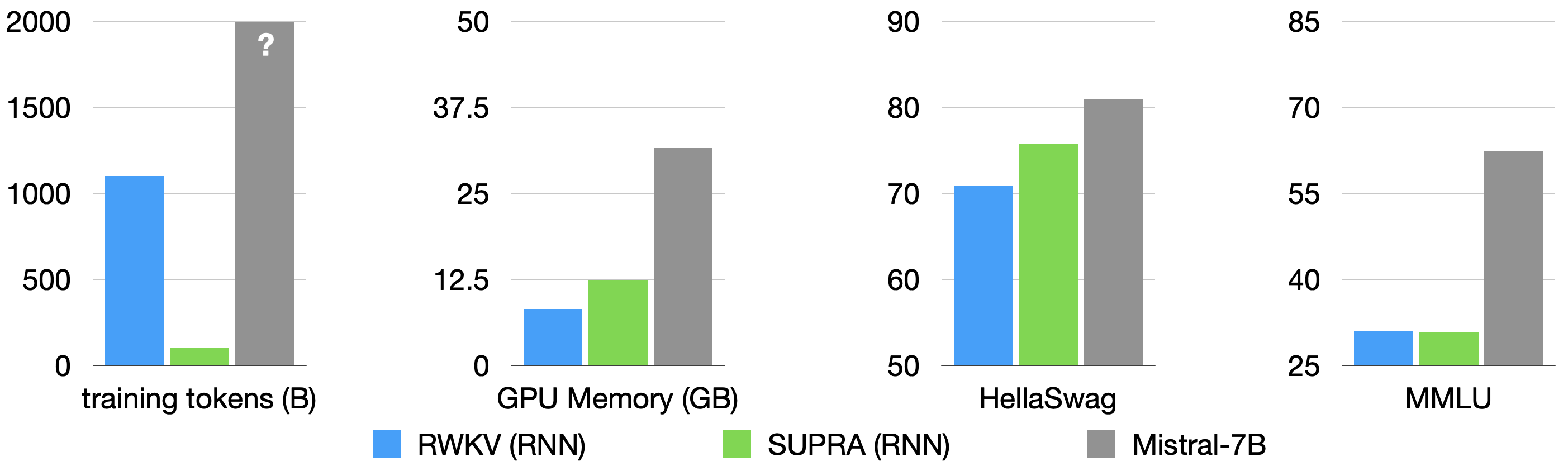
提出SUPRA方法,以低成本将预训练Transformer LLM转化为线性RNN,提升推理效率。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 线性Transformer 循环神经网络 增量训练 大型语言模型 低成本训练
📋 核心要点
- 现有线性Transformer模型扩展性差,且预训练成本高昂,限制了其发展。
- SUPRA方法通过增量训练,将预训练Transformer转化为RNN,降低了训练成本。
- 实验表明,SUPRA方法在标准基准测试中具有竞争力,但仍存在长文本建模的挑战。
📝 摘要(中文)
线性Transformer作为softmax注意力机制的亚二次时间复杂度替代方案,因其固定大小的循环状态降低了推理成本而备受关注。然而,其原始公式存在扩展性差和性能不如计算量匹配的Transformer的问题。最近的线性模型,如RWKV和Mamba,试图通过提出新的时间混合和门控架构来解决这些缺点,但预训练大型语言模型需要大量的数据和计算投资。因此,对亚二次架构的探索受到计算资源和高质量预训练数据集的限制。作为预训练线性Transformer的一种经济高效的替代方案,我们提出了可扩展的循环注意力增量训练(SUPRA)。我们提出了一种方法,以适度的计算预算将现有的大型预训练Transformer增量训练为循环神经网络(RNN)。这使我们能够利用现有Transformer LLM强大的预训练数据和性能,同时仅需5%的训练成本。我们发现我们的线性化技术在标准基准测试中表现出竞争优势,但我们发现即使是最大的线性模型也存在持续的上下文学习和长上下文建模方面的不足。
🔬 方法详解
问题定义:论文旨在解决线性Transformer模型训练成本高昂,以及在长文本建模方面表现不足的问题。现有的线性模型,如RWKV和Mamba,虽然在一定程度上缓解了这些问题,但仍然需要大量的计算资源和高质量的预训练数据。
核心思路:论文的核心思路是利用已有的、经过充分预训练的Transformer模型,通过一种高效的增量训练方法,将其转化为循环神经网络(RNN)。这种方法可以避免从头开始训练线性模型,从而大大降低了计算成本。
技术框架:SUPRA (Scalable UPtraining for Recurrent Attention) 的整体框架包括以下几个主要阶段:1) 选择一个预训练好的Transformer LLM;2) 设计一种将Transformer的注意力机制线性化的方法,将其转化为循环结构;3) 使用少量数据和计算资源,对线性化的RNN进行增量训练,使其适应新的循环结构;4) 在标准基准测试中评估模型的性能。
关键创新:SUPRA的关键创新在于提出了一种高效的增量训练方法,可以将预训练的Transformer模型转化为线性RNN,而无需从头开始训练。这种方法可以充分利用已有的预训练知识,从而大大降低了训练成本。
关键设计:SUPRA的关键设计包括:1) 如何将Transformer的注意力机制线性化,使其能够转化为循环结构;2) 如何设计增量训练的目标函数和优化策略,以保证模型在转化为RNN后仍然能够保持良好的性能;3) 如何选择合适的预训练Transformer模型作为增量训练的起点。
🖼️ 关键图片


📊 实验亮点
SUPRA方法仅需5%的训练成本,即可将预训练的Transformer模型转化为具有竞争力的线性RNN。实验结果表明,SUPRA在标准基准测试中表现良好,证明了该方法的有效性。然而,研究也指出了线性模型在上下文学习和长文本建模方面仍然存在不足。
🎯 应用场景
该研究成果可应用于各种需要低延迟和高效率的自然语言处理任务,例如实时翻译、语音识别、对话系统等。通过将大型Transformer模型转化为线性RNN,可以在资源受限的设备上部署更强大的语言模型,从而推动人工智能在边缘计算领域的应用。
📄 摘要(原文)
Linear transformers have emerged as a subquadratic-time alternative to softmax attention and have garnered significant interest due to their fixed-size recurrent state that lowers inference cost. However, their original formulation suffers from poor scaling and underperforms compute-matched transformers. Recent linear models such as RWKV and Mamba have attempted to address these shortcomings by proposing novel time-mixing and gating architectures, but pre-training large language models requires significant data and compute investments. Thus, the search for subquadratic architectures is limited by the availability of compute and quality pre-training datasets. As a cost-effective alternative to pre-training linear transformers, we propose Scalable UPtraining for Recurrent Attention (SUPRA). We present a method to uptrain existing large pre-trained transformers into Recurrent Neural Networks (RNNs) with a modest compute budget. This allows us to leverage the strong pre-training data and performance of existing transformer LLMs, while requiring 5% of the training cost. We find that our linearization technique leads to competitive performance on standard benchmarks, but we identify persistent in-context learning and long-context modeling shortfalls for even the largest linear models. Our code and models can be found at https://github.com/TRI-ML/linear_open_lm.