What Can Natural Language Processing Do for Peer Review?
作者: Ilia Kuznetsov, Osama Mohammed Afzal, Koen Dercksen, Nils Dycke, Alexander Goldberg, Tom Hope, Dirk Hovy, Jonathan K. Kummerfeld, Anne Lauscher, Kevin Leyton-Brown, Sheng Lu, Mausam, Margot Mieskes, Aurélie Névéol, Danish Pruthi, Lizhen Qu, Roy Schwartz, Noah A. Smith, Thamar Solorio, Jingyan Wang, Xiaodan Zhu, Anna Rogers, Nihar B. Shah, Iryna Gurevych
分类: cs.CL
发布日期: 2024-05-10
💡 一句话要点
探讨自然语言处理在同行评审中的应用,为机器辅助评审提供基础。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 同行评审 自然语言处理 机器辅助评审 科学质量控制 大型语言模型
📋 核心要点
- 同行评审是保障科研质量的关键,但人工评审耗时且易出错,亟需改进。
- 论文探讨了自然语言处理(NLP)在同行评审各阶段的应用潜力,并分析了相关挑战。
- 论文呼吁社区共同努力,解决数据、伦理等问题,推动NLP在同行评审中的应用。
📝 摘要(中文)
每年产生的科学文章数量都在快速增长,对其进行质量控制对科学家乃至公众福祉至关重要。在现代科学中,这一过程主要委托给同行评审——一种分布式程序,其中每份提交的稿件都由该领域的几位独立专家进行评估。同行评审应用广泛,但它既困难又耗时,且容易出错。由于同行评审中涉及的稿件、评审、讨论等内容主要基于文本,因此自然语言处理在改进评审方面具有巨大的潜力。随着大型语言模型(LLM)的出现,NLP在许多新任务中都能提供帮助,关于机器辅助同行评审的讨论也正在加速。然而,究竟哪里需要帮助,NLP可以在哪里提供帮助,以及在哪里应该置身事外?本文旨在为未来NLP辅助同行评审工作奠定基础。我们讨论了同行评审作为一个通用过程,并以AI会议的评审为例。我们详细介绍了从稿件提交到最终修订的每个步骤,并讨论了相关的挑战和NLP辅助的机会,并通过现有工作加以说明。然后,我们转向NLP在同行评审中面临的重大挑战,包括数据获取和许可、操作和实验以及伦理问题。为了帮助巩固社区的努力,我们创建了一个配套存储库,其中汇总了与同行评审相关的关键数据集。最后,我们向科学界、NLP和AI研究人员、政策制定者和资助机构发出详细的行动呼吁,以帮助推进NLP在同行评审方面的研究。我们希望我们的工作将有助于在NLP社区内外,为人工智能时代机器辅助科学质量控制的研究设定议程。
🔬 方法详解
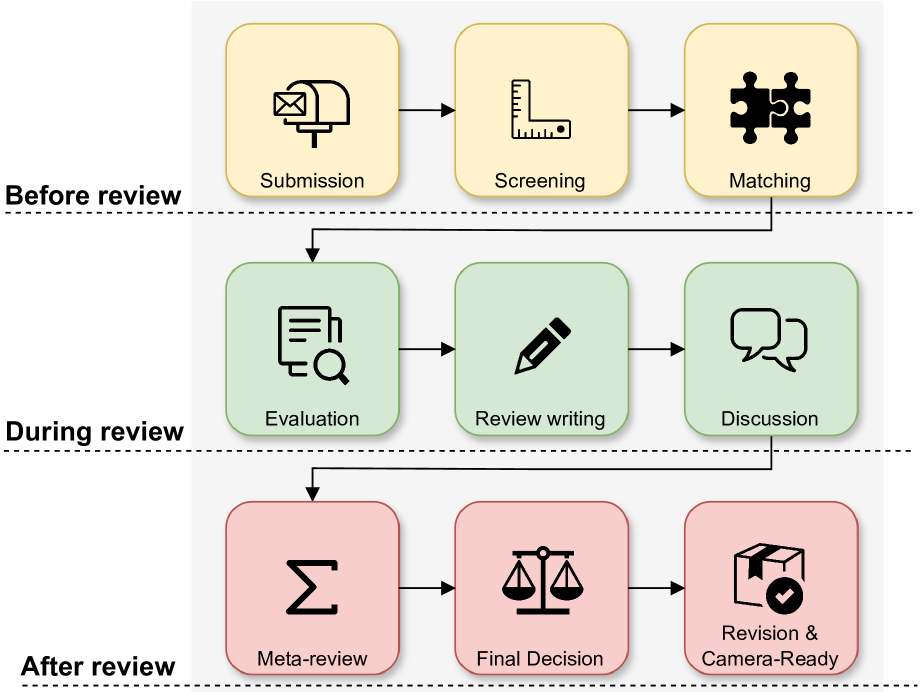
问题定义:同行评审是科学研究质量控制的重要环节,但人工评审存在耗时、主观性强、易出错等问题。现有方法难以有效利用NLP技术辅助评审,缺乏对评审流程的全面分析和针对性解决方案。
核心思路:论文的核心思路是将同行评审过程分解为多个阶段,针对每个阶段的挑战和机遇,探讨NLP技术的应用潜力。通过分析现有研究,识别NLP可以发挥作用的关键环节,并提出未来研究方向。
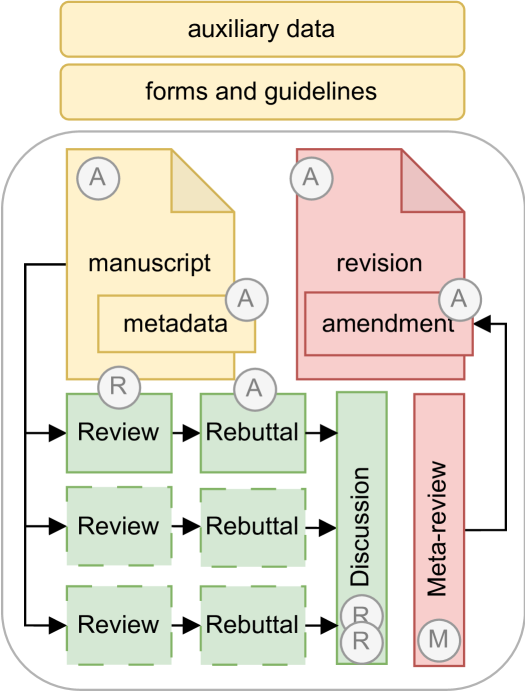
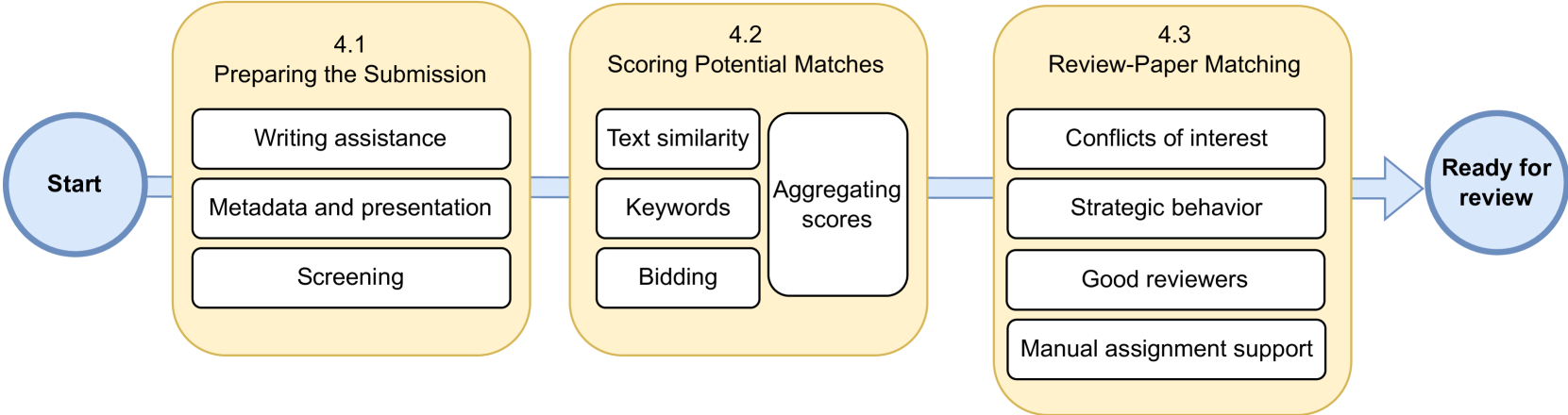
技术框架:论文没有提出具体的NLP模型或算法,而是提供了一个关于NLP在同行评审中应用的框架性讨论。该框架涵盖了从稿件提交到最终修订的整个评审流程,并针对每个阶段提出了NLP辅助的可能性,例如:稿件匹配、摘要生成、论证质量评估、偏见检测等。
关键创新:论文的主要创新在于其系统性地分析了同行评审流程,并将其与NLP技术相结合,为未来的研究提供了清晰的路线图。它强调了数据获取、伦理问题和实验设计的重要性,并呼吁社区共同努力,推动NLP在同行评审中的应用。
关键设计:论文没有涉及具体的模型设计或参数设置。它更侧重于对现有研究的综述和对未来方向的展望,强调了数据质量、可解释性和公平性在NLP辅助同行评审中的重要性。
🖼️ 关键图片
📊 实验亮点
论文系统性地分析了同行评审流程,并探讨了NLP技术在各个阶段的应用潜力,为未来的研究提供了清晰的路线图。论文还强调了数据获取、伦理问题和实验设计的重要性,并创建了一个包含关键数据集的存储库,为社区研究提供了便利。
🎯 应用场景
该研究为开发机器辅助同行评审系统奠定了基础,可应用于学术期刊、会议等场景,提高评审效率和质量,减少人为偏见,加速科学研究的进展。未来,NLP技术有望实现更智能化的评审辅助,例如自动识别研究的创新性、评估实验的可靠性等。
📄 摘要(原文)
The number of scientific articles produced every year is growing rapidly. Providing quality control over them is crucial for scientists and, ultimately, for the public good. In modern science, this process is largely delegated to peer review -- a distributed procedure in which each submission is evaluated by several independent experts in the field. Peer review is widely used, yet it is hard, time-consuming, and prone to error. Since the artifacts involved in peer review -- manuscripts, reviews, discussions -- are largely text-based, Natural Language Processing has great potential to improve reviewing. As the emergence of large language models (LLMs) has enabled NLP assistance for many new tasks, the discussion on machine-assisted peer review is picking up the pace. Yet, where exactly is help needed, where can NLP help, and where should it stand aside? The goal of our paper is to provide a foundation for the future efforts in NLP for peer-reviewing assistance. We discuss peer review as a general process, exemplified by reviewing at AI conferences. We detail each step of the process from manuscript submission to camera-ready revision, and discuss the associated challenges and opportunities for NLP assistance, illustrated by existing work. We then turn to the big challenges in NLP for peer review as a whole, including data acquisition and licensing, operationalization and experimentation, and ethical issues. To help consolidate community efforts, we create a companion repository that aggregates key datasets pertaining to peer review. Finally, we issue a detailed call for action for the scientific community, NLP and AI researchers, policymakers, and funding bodies to help bring the research in NLP for peer review forward. We hope that our work will help set the agenda for research in machine-assisted scientific quality control in the age of AI, within the NLP community and beyond.