Mitigating Hallucinations in Large Language Models via Self-Refinement-Enhanced Knowledge Retrieval
作者: Mengjia Niu, Hao Li, Jie Shi, Hamed Haddadi, Fan Mo
分类: cs.CL, cs.LG
发布日期: 2024-05-10
💡 一句话要点
提出Re-KGR,通过自精炼知识检索缓解大语言模型中的幻觉问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 幻觉缓解 知识图谱检索 自精炼 医疗领域
📋 核心要点
- 现有知识图谱增强方法需要对每个事实进行多轮检索和验证,计算资源需求高,难以在实际场景中应用。
- Re-KGR通过预测概率分布归因识别潜在幻觉token,并精炼相关知识三元组,减少了检索和验证的轮次。
- 实验结果表明,Re-KGR能够有效提升大语言模型在医疗领域的事实性,并在真实性指标上取得了最佳表现。
📝 摘要(中文)
大型语言模型(LLM)在各个领域都展现出了卓越的能力,但其容易产生幻觉的问题对其在医疗保健等关键领域的部署构成了重大挑战。为了解决这个问题,从知识图谱(KG)中检索相关事实被认为是一种很有前途的方法。现有的KG增强方法往往是资源密集型的,对于每个事实都需要多轮检索和验证,这阻碍了它们在实际场景中的应用。本研究提出了自精炼增强知识图谱检索(Re-KGR),旨在以更少的检索工作量增强LLM响应的事实性,特别是在医疗领域。我们的方法利用不同token和模型层中下一个token预测概率分布的归因,主要识别具有高幻觉潜力的token,通过细化与这些token相关的知识三元组来减少验证轮次。此外,我们在后处理阶段使用检索到的知识来纠正不准确的内容,从而提高生成响应的真实性。在医疗数据集上的实验结果表明,我们的方法可以增强各种基础模型的事实能力,并在真实性方面取得了最高的分数。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在医疗领域应用中存在的幻觉问题,即生成不真实或不准确的医疗信息。现有基于知识图谱(KG)增强的方法,虽然可以提高LLM的事实性,但需要对每个事实进行多次检索和验证,计算成本高昂,难以满足实际应用的需求。
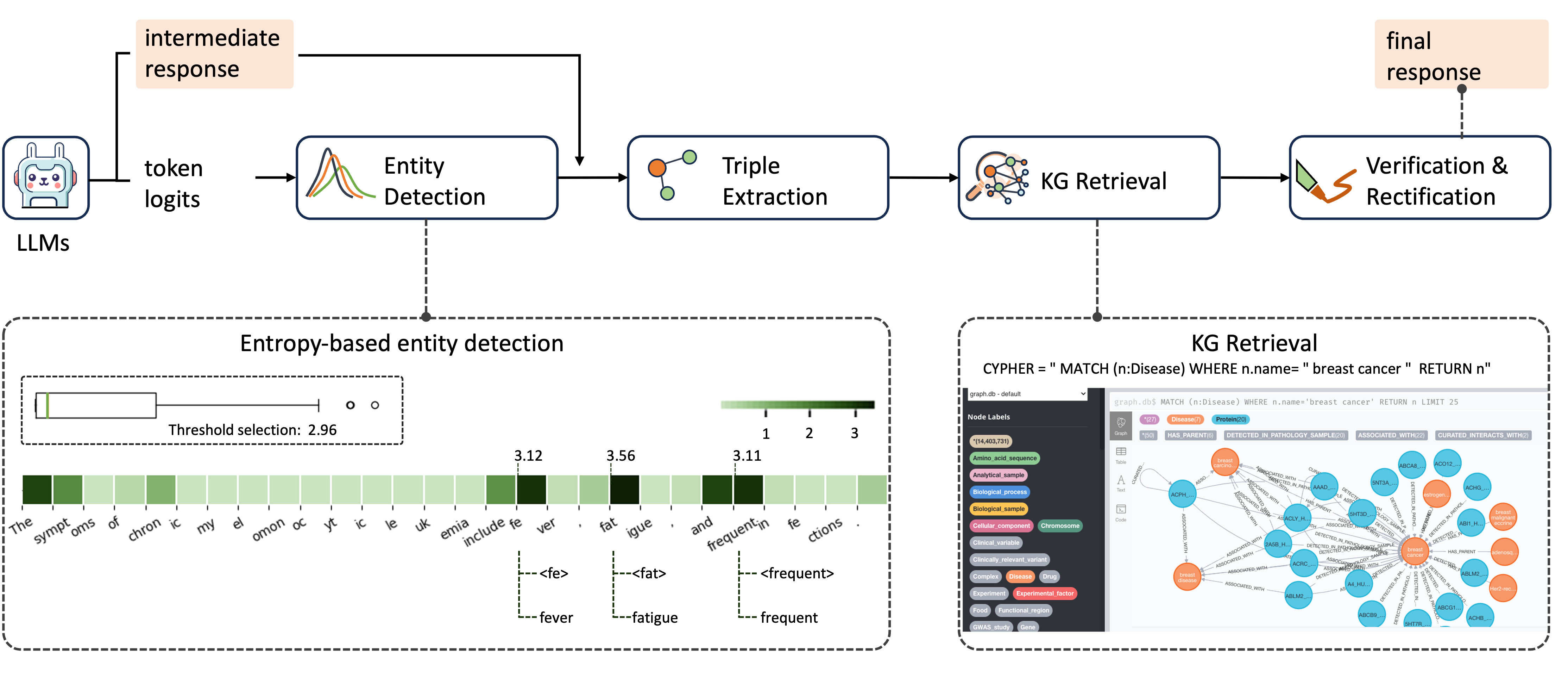
核心思路:Re-KGR的核心思路是减少知识检索和验证的次数,从而降低计算成本。它通过分析LLM生成过程中每个token的预测概率分布,识别出最有可能产生幻觉的token。然后,只针对这些token进行知识检索和验证,从而避免了对所有token进行检索的需要。
技术框架:Re-KGR主要包含两个阶段:幻觉token识别和知识修正。在幻觉token识别阶段,Re-KGR利用LLM的中间层输出的token预测概率分布,计算每个token的幻觉潜力得分。在高置信度token处停止检索,降低计算消耗。在知识修正阶段,Re-KGR使用检索到的知识来修正LLM生成的不准确内容。
关键创新:Re-KGR的关键创新在于利用LLM自身的预测概率分布来指导知识检索过程。与现有方法相比,Re-KGR不需要对所有token进行检索,而是只针对最有可能产生幻觉的token进行检索,从而大大降低了计算成本。此外,Re-KGR还利用检索到的知识来修正LLM生成的不准确内容,进一步提高了LLM的事实性。
关键设计:Re-KGR使用交叉熵损失函数来训练LLM。幻觉潜力得分的计算方式是基于不同token和模型层的预测概率分布的归因。知识修正阶段使用基于相似度的知识融合方法,将检索到的知识与LLM的生成内容进行融合。
🖼️ 关键图片

📊 实验亮点
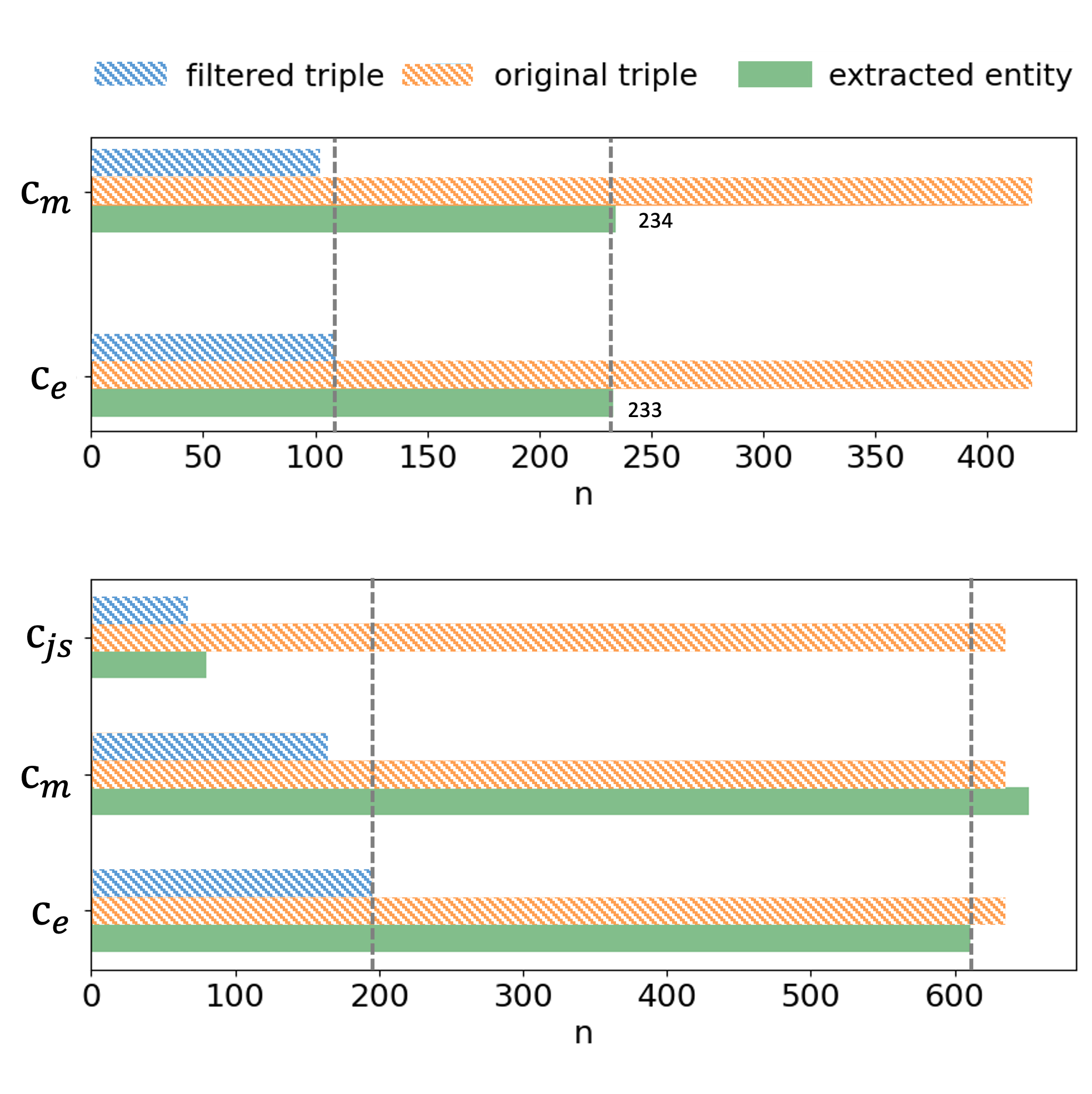
实验结果表明,Re-KGR在医疗数据集上显著提高了LLM的事实性。与现有方法相比,Re-KGR在真实性指标上取得了最高的分数,证明了其有效性。此外,Re-KGR还能够以更少的检索工作量达到更高的准确率,降低了计算成本。
🎯 应用场景
Re-KGR具有广泛的应用前景,尤其是在医疗、金融等对信息准确性要求高的领域。它可以用于辅助医生进行诊断和治疗,帮助金融分析师进行风险评估,以及为用户提供可靠的信息咨询服务。通过降低LLM的幻觉率,Re-KGR可以提高LLM在这些领域的应用价值,并促进人工智能技术在更广泛的领域得到应用。
📄 摘要(原文)
Large language models (LLMs) have demonstrated remarkable capabilities across various domains, although their susceptibility to hallucination poses significant challenges for their deployment in critical areas such as healthcare. To address this issue, retrieving relevant facts from knowledge graphs (KGs) is considered a promising method. Existing KG-augmented approaches tend to be resource-intensive, requiring multiple rounds of retrieval and verification for each factoid, which impedes their application in real-world scenarios. In this study, we propose Self-Refinement-Enhanced Knowledge Graph Retrieval (Re-KGR) to augment the factuality of LLMs' responses with less retrieval efforts in the medical field. Our approach leverages the attribution of next-token predictive probability distributions across different tokens, and various model layers to primarily identify tokens with a high potential for hallucination, reducing verification rounds by refining knowledge triples associated with these tokens. Moreover, we rectify inaccurate content using retrieved knowledge in the post-processing stage, which improves the truthfulness of generated responses. Experimental results on a medical dataset demonstrate that our approach can enhance the factual capability of LLMs across various foundational models as evidenced by the highest scores on truthfulness.