LyS at SemEval-2024 Task 3: An Early Prototype for End-to-End Multimodal Emotion Linking as Graph-Based Parsing
作者: Ana Ezquerro, David Vilares
分类: cs.CL
发布日期: 2024-05-10
备注: Accepted at SemEval 2024
💡 一句话要点
LyS提出基于图解析的多模态情感链接端到端原型系统,用于对话情感原因分析。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 情感原因分析 多模态对话 图解析 Transformer 端到端系统
📋 核心要点
- 现有方法在多方对话中识别因果情感关系方面存在不足,难以有效利用上下文信息。
- 论文提出一种基于图解析的端到端系统,将情感原因分析建模为图结构预测问题。
- 该模型在SemEval 2024 Task 3 Subtask 1中取得了第7名的成绩,验证了方法的有效性。
📝 摘要(中文)
本文介绍了我们在SemEval 2024 Task 3(对话中的多模态情感原因分析)中的工作。我们开发了一个端到端系统的早期原型,该系统利用依赖解析中的图方法来识别多方对话中的因果情感关系。我们的模型包括一个基于神经Transformer的编码器,用于对多模态对话数据进行上下文表示,以及一个基于图的解码器,用于生成因果图的邻接矩阵得分。在仅使用文本输入的情况下,我们在Subtask 1的15个有效官方提交中排名第7。我们还讨论了在评估后使用多模态输入参与Subtask 2的情况。
🔬 方法详解
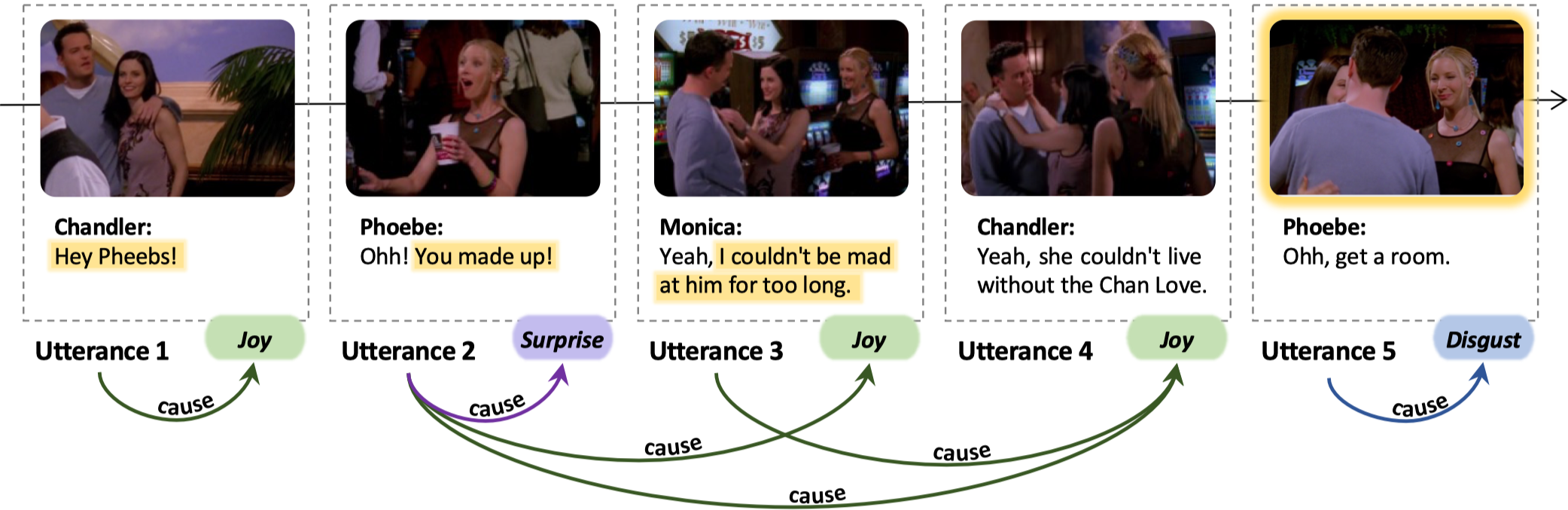
问题定义:论文旨在解决多方对话中情感原因分析的问题,即识别对话中哪些话语引发了特定的情感。现有方法可能难以捕捉对话的上下文信息,并且难以处理多模态输入(例如,文本、语音、视频)。
核心思路:论文的核心思路是将情感原因分析问题建模为一个图解析问题。对话中的每个话语被视为图中的一个节点,如果一个话语是另一个话语情感的原因,则这两个节点之间存在一条边。通过预测图的邻接矩阵,可以识别出对话中的因果情感关系。
技术框架:该系统包含两个主要模块:一个基于神经Transformer的编码器和一个基于图的解码器。编码器负责对多模态对话数据进行上下文表示,将每个话语编码成一个向量表示。解码器负责生成因果图的邻接矩阵得分,该得分表示两个话语之间存在因果关系的概率。
关键创新:该方法的主要创新在于将情感原因分析问题建模为一个图解析问题,并使用基于图的解码器来预测因果关系。这种方法可以更好地利用对话的结构信息,并且可以方便地扩展到多模态输入。
关键设计:编码器使用预训练的Transformer模型(具体模型未知)来获取上下文表示。解码器使用一个图神经网络(具体结构未知)来预测邻接矩阵得分。损失函数可能包括交叉熵损失或类似的图结构预测损失函数。具体的参数设置和网络结构在论文中可能没有详细说明,属于早期原型阶段。
🖼️ 关键图片
📊 实验亮点
该模型在SemEval 2024 Task 3 Subtask 1中,仅使用文本输入的情况下,在15个有效官方提交中排名第7。这表明该方法在文本情感原因分析方面具有一定的竞争力。虽然多模态输入的结果未详细说明,但参与Subtask 2表明该模型具备处理多模态数据的潜力。
🎯 应用场景
该研究成果可应用于智能客服、心理健康咨询、社交媒体情感分析等领域。通过自动识别对话中的情感原因,可以帮助理解用户的情感状态,并提供更个性化的服务。未来,该技术有望应用于人机交互系统,提升沟通效率和用户体验。
📄 摘要(原文)
This paper describes our participation in SemEval 2024 Task 3, which focused on Multimodal Emotion Cause Analysis in Conversations. We developed an early prototype for an end-to-end system that uses graph-based methods from dependency parsing to identify causal emotion relations in multi-party conversations. Our model comprises a neural transformer-based encoder for contextualizing multimodal conversation data and a graph-based decoder for generating the adjacency matrix scores of the causal graph. We ranked 7th out of 15 valid and official submissions for Subtask 1, using textual inputs only. We also discuss our participation in Subtask 2 during post-evaluation using multi-modal inputs.