For the Misgendered Chinese in Gender Bias Research: Multi-Task Learning with Knowledge Distillation for Pinyin Name-Gender Prediction
作者: Xiaocong Du, Haipeng Zhang
分类: cs.CL, cs.CY
发布日期: 2024-05-10
💡 一句话要点
提出基于多任务学习与知识蒸馏的拼音姓名性别预测方法,提升中文姓名性别识别准确率。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 姓名性别预测 多任务学习 知识蒸馏 中文信息处理 性别偏见研究
📋 核心要点
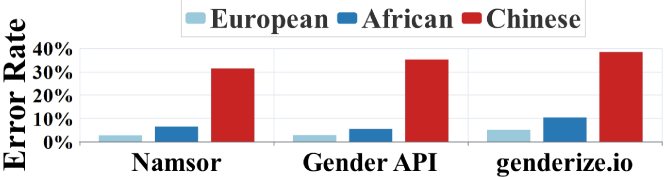
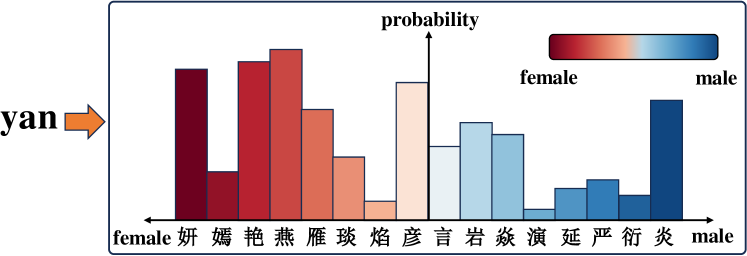
- 现有姓名性别推断工具在处理中文拼音姓名时准确率较低,忽略了拼音与汉字之间的语义关联。
- 论文提出一种基于多任务学习和知识蒸馏的方法,利用汉字信息提升拼音姓名性别预测的准确性。
- 实验结果表明,该方法显著优于商业工具和现有算法,在中文姓名性别识别任务上取得了更好的性能。
📝 摘要(中文)
为了实现联合国可持续发展全球目标中的性别平等,性别偏见研究依赖于基于姓名的性别推断工具来分配个体性别标签。然而,这些工具通常不准确地预测中文拼音姓名的性别,导致此类研究中潜在的偏差。随着中国人越来越多地参与国际活动,这种情况变得越来越严重。具体来说,当前的工具侧重于发音(拼音)信息,忽略了拼音和汉字之间的潜在联系,而这些联系传递着关键信息。作为一项初步尝试,我们提出了拼音姓名性别猜测问题,并设计了一个由知识蒸馏辅助的多任务学习网络,使模型中的拼音嵌入能够拥有汉字的语义特征,并从汉字姓名中学习性别信息。我们的开源方法相对超过商业姓名性别猜测工具9.70%到20.08%,并且也优于最先进的算法。
🔬 方法详解
问题定义:论文旨在解决中文拼音姓名性别预测不准确的问题。现有方法主要依赖拼音信息,忽略了拼音背后汉字的语义信息,导致预测准确率不高,尤其是在国际活动中,这一问题日益突出。
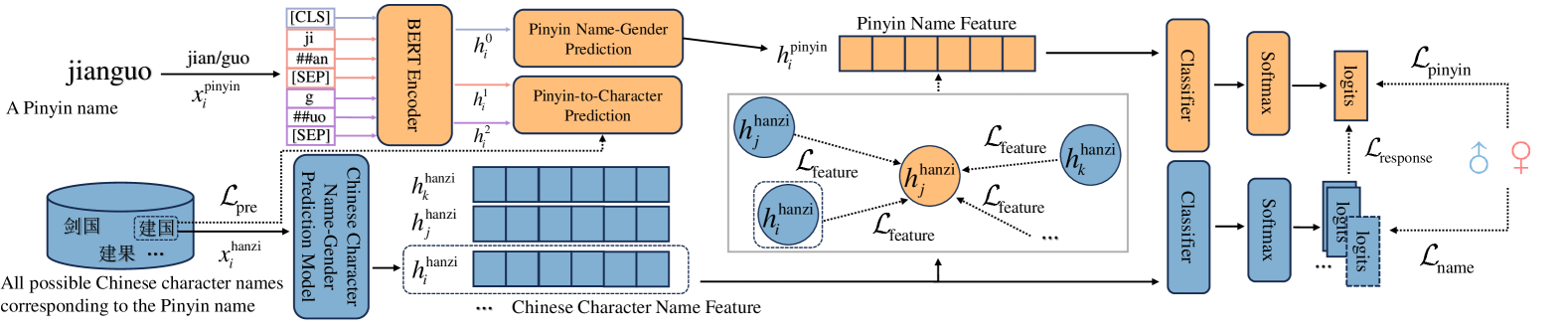
核心思路:论文的核心思路是利用汉字所蕴含的性别信息来辅助拼音姓名性别预测。通过多任务学习,让模型同时学习拼音和汉字的性别信息,并利用知识蒸馏将汉字的性别知识迁移到拼音嵌入中,从而提升拼音姓名性别预测的准确率。
技术框架:整体框架是一个多任务学习网络,包含两个主要任务:拼音姓名性别预测和汉字姓名性别预测。首先,将拼音和汉字姓名分别嵌入到向量空间中。然后,通过共享的底层网络学习拼音和汉字的共同特征表示。最后,分别使用两个独立的分类器进行性别预测。知识蒸馏模块用于将汉字姓名性别预测器的知识迁移到拼音姓名性别预测器。
关键创新:最重要的技术创新点在于将多任务学习和知识蒸馏相结合,利用汉字的语义信息来提升拼音姓名性别预测的准确率。与现有方法相比,该方法充分利用了中文姓名中拼音和汉字之间的关联性,从而提高了预测的准确性和鲁棒性。
关键设计:论文使用了预训练的词向量(例如Word2Vec或GloVe)来初始化拼音和汉字的嵌入。损失函数包括拼音姓名性别预测的交叉熵损失、汉字姓名性别预测的交叉熵损失以及知识蒸馏损失。知识蒸馏损失采用KL散度来衡量汉字姓名性别预测器和拼音姓名性别预测器输出概率分布之间的差异。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法在中文拼音姓名性别预测任务上显著优于现有方法。与商业姓名性别猜测工具相比,相对提升了9.70%到20.08%。同时,该方法也超越了最先进的算法,证明了其有效性和优越性。这些结果表明,利用汉字信息可以有效提升拼音姓名性别预测的准确率。
🎯 应用场景
该研究成果可应用于性别偏见分析、人口统计研究、用户画像构建等领域。通过提高中文姓名性别识别的准确率,可以减少相关研究中的偏差,并为更公平、公正的社会发展提供支持。未来,该方法可以扩展到其他语言和文化背景下,提升跨文化姓名性别识别的准确性。
📄 摘要(原文)
Achieving gender equality is a pivotal factor in realizing the UN's Global Goals for Sustainable Development. Gender bias studies work towards this and rely on name-based gender inference tools to assign individual gender labels when gender information is unavailable. However, these tools often inaccurately predict gender for Chinese Pinyin names, leading to potential bias in such studies. With the growing participation of Chinese in international activities, this situation is becoming more severe. Specifically, current tools focus on pronunciation (Pinyin) information, neglecting the fact that the latent connections between Pinyin and Chinese characters (Hanzi) behind convey critical information. As a first effort, we formulate the Pinyin name-gender guessing problem and design a Multi-Task Learning Network assisted by Knowledge Distillation that enables the Pinyin embeddings in the model to possess semantic features of Chinese characters and to learn gender information from Chinese character names. Our open-sourced method surpasses commercial name-gender guessing tools by 9.70\% to 20.08\% relatively, and also outperforms the state-of-the-art algorithms.