Exploring the Capabilities of Large Multimodal Models on Dense Text
作者: Shuo Zhang, Biao Yang, Zhang Li, Zhiyin Ma, Yuliang Liu, Xiang Bai
分类: cs.CL, cs.AI
发布日期: 2024-05-09
🔗 代码/项目: GITHUB
💡 一句话要点
提出DT-VQA数据集,探索大型多模态模型在密集文本理解任务中的能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 密集文本理解 问答系统 数据集构建 提示工程
📋 核心要点
- 现有大型多模态模型在密集文本理解方面能力不足,限制了其在文档、表格等场景的应用。
- 论文提出DT-VQA数据集,并通过提示工程和下游微调等策略,提升模型在密集文本问答任务上的性能。
- 实验表明,即使使用自动标注数据,微调后的模型性能也能显著提升,验证了方法的有效性。
📝 摘要(中文)
大型多模态模型(LMM)在多模态任务中取得了显著进展,但它们在涉及密集文本内容任务中的能力仍有待充分探索。密集文本通常存在于文档、表格和产品描述中,携带重要信息。理解密集文本有助于获得更准确的信息,从而辅助做出更好的决策。为了进一步探索LMM在复杂文本任务中的能力,我们提出了DT-VQA数据集,包含17万个问答对。本文对GPT4V、Gemini和各种开源LMM在我们的数据集上进行了全面评估,揭示了它们的优势和劣势。此外,我们评估了LMM的两种策略的有效性:提示工程和下游微调。我们发现,即使使用自动标记的训练数据集,也可以显著提高模型性能。我们希望这项研究能够促进LMM在密集文本任务中的研究。
🔬 方法详解
问题定义:论文旨在解决大型多模态模型在理解和处理密集文本内容方面的不足。现有方法在处理包含大量细节信息的文档、表格等场景时,难以准确提取关键信息并进行有效推理,导致问答等任务的性能下降。
核心思路:论文的核心思路是通过构建一个专门针对密集文本问答的数据集(DT-VQA),并利用该数据集对现有的大型多模态模型进行评估和微调,从而提升模型在密集文本理解方面的能力。同时,探索提示工程等策略对模型性能的影响。
技术框架:论文的技术框架主要包括以下几个部分:1) 构建DT-VQA数据集,包含17万个问答对,覆盖文档、表格等多种密集文本场景;2) 选择GPT4V、Gemini等主流大型多模态模型作为评估对象;3) 在DT-VQA数据集上对这些模型进行评估,分析其在密集文本理解方面的优势和劣势;4) 探索提示工程和下游微调等策略对模型性能的影响;5) 分析实验结果,总结经验教训,为未来的研究提供指导。
关键创新:论文的关键创新在于构建了DT-VQA数据集,该数据集专门针对密集文本问答任务,可以更有效地评估和提升大型多模态模型在相关方面的能力。此外,论文还系统地评估了多种大型多模态模型在DT-VQA数据集上的性能,并探索了提示工程和下游微调等策略的效果,为未来的研究提供了有价值的参考。
关键设计:论文的关键设计包括:1) DT-VQA数据集的构建,需要精心设计问题和答案,确保其能够有效地评估模型在密集文本理解方面的能力;2) 提示工程策略的设计,需要选择合适的提示词,引导模型更好地理解问题和文本内容;3) 下游微调策略的设计,需要选择合适的损失函数和优化器,并进行充分的实验,以获得最佳的性能提升。
🖼️ 关键图片
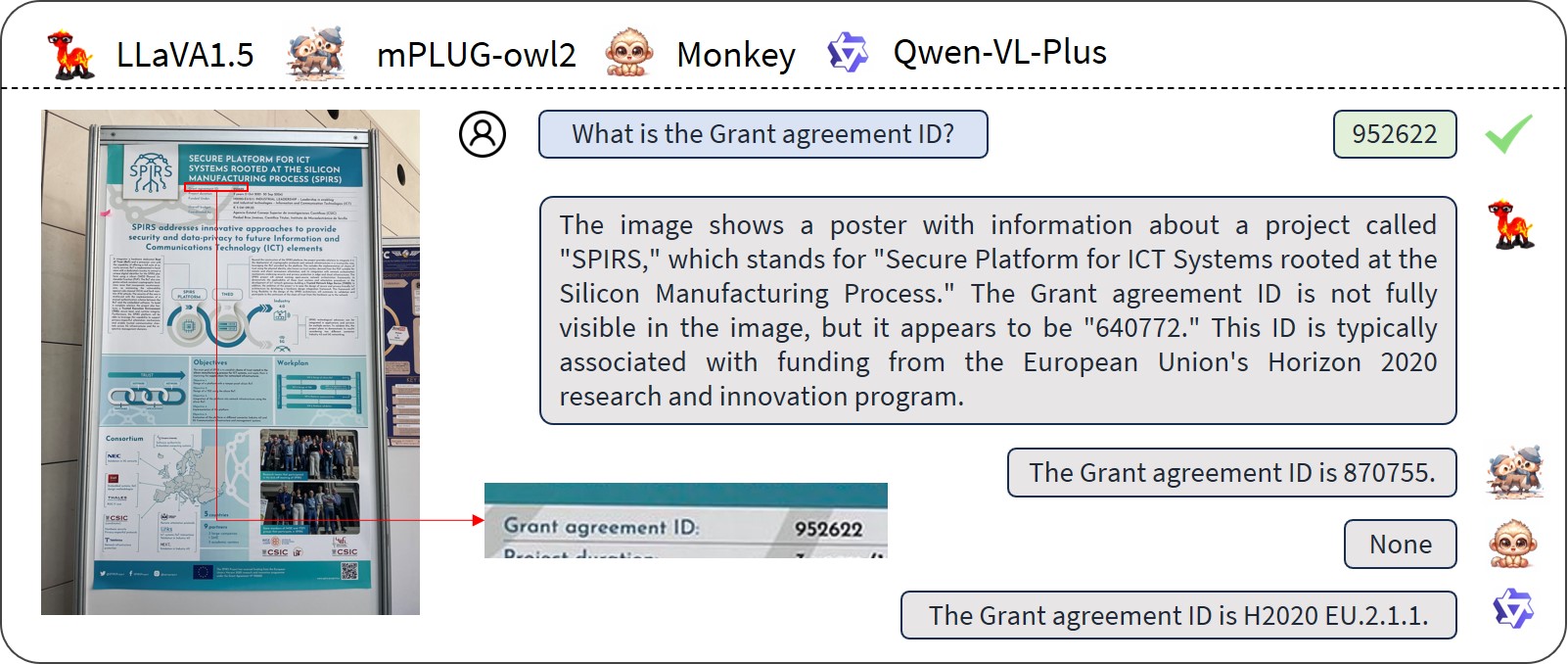


📊 实验亮点
实验结果表明,在DT-VQA数据集上,即使使用自动标注的训练数据,通过下游微调也能显著提升模型性能。例如,经过微调的模型在某些指标上取得了超过10%的提升,证明了该数据集和微调策略的有效性。同时,实验也揭示了不同大型多模态模型在密集文本理解方面的优势和劣势。
🎯 应用场景
该研究成果可应用于文档理解、表格问答、产品描述分析等领域。通过提升模型对密集文本的理解能力,可以更准确地提取关键信息,辅助用户进行决策,提高工作效率。未来,该研究还可扩展到更复杂的场景,如金融报告分析、法律文件解读等。
📄 摘要(原文)
While large multi-modal models (LMM) have shown notable progress in multi-modal tasks, their capabilities in tasks involving dense textual content remains to be fully explored. Dense text, which carries important information, is often found in documents, tables, and product descriptions. Understanding dense text enables us to obtain more accurate information, assisting in making better decisions. To further explore the capabilities of LMM in complex text tasks, we propose the DT-VQA dataset, with 170k question-answer pairs. In this paper, we conduct a comprehensive evaluation of GPT4V, Gemini, and various open-source LMMs on our dataset, revealing their strengths and weaknesses. Furthermore, we evaluate the effectiveness of two strategies for LMM: prompt engineering and downstream fine-tuning. We find that even with automatically labeled training datasets, significant improvements in model performance can be achieved. We hope that this research will promote the study of LMM in dense text tasks. Code will be released at https://github.com/Yuliang-Liu/MultimodalOCR.