OpenBA-V2: Reaching 77.3% High Compression Ratio with Fast Multi-Stage Pruning
作者: Dan Qiao, Yi Su, Pinzheng Wang, Jing Ye, Wenjing Xie, Yuechi Zhou, Yuyang Ding, Zecheng Tang, Jikai Wang, Yixin Ji, Yue Wang, Pei Guo, Zechen Sun, Zikang Zhang, Juntao Li, Pingfu Chao, Wenliang Chen, Guohong Fu, Guodong Zhou, Qiaoming Zhu, Min Zhang
分类: cs.CL
发布日期: 2024-05-09
💡 一句话要点
OpenBA-V2:通过快速多阶段剪枝实现77.3%高压缩率
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 模型压缩 剪枝 持续预训练 知识蒸馏
📋 核心要点
- 大型语言模型参数众多,部署成本高昂,限制了其在资源受限场景下的应用。
- OpenBA-V2通过多阶段压缩和持续预训练,在保证性能的同时显著减小模型尺寸。
- OpenBA-V2实现了77.3%的压缩率,并在下游任务中取得了与15B OpenBA模型相近的性能。
📝 摘要(中文)
大型语言模型(LLMs)因其强大的能力在许多领域发挥着重要作用。然而,它们庞大的参数量导致了高部署要求和显著的推理成本,这阻碍了它们的实际应用。训练更小的模型是解决这个问题的一种有效方法。因此,我们推出了OpenBA-V2,这是一个34亿参数的模型,它源于对原始150亿参数OpenBA模型的多阶段压缩和持续预训练。OpenBA-V2利用更多的数据、更灵活的训练目标以及层剪枝、神经元剪枝和词汇表剪枝等技术,以实现77.3%的压缩率,同时性能损失最小。OpenBA-V2在常识推理和命名实体识别(NER)等下游任务中表现出与其他类似规模的开源模型相比具有竞争力的性能,其结果接近或等同于150亿参数的OpenBA模型。OpenBA-V2表明,通过采用先进的训练目标和数据策略,可以将LLM压缩成更小的模型,同时性能损失最小,这可能有助于在资源受限的场景中部署LLM。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)参数量过大,导致部署和推理成本高昂的问题。现有方法在压缩模型时,往往难以在压缩率和性能之间取得平衡,或者需要大量的计算资源进行训练。
核心思路:论文的核心思路是通过多阶段压缩,逐步减小模型尺寸,并在压缩过程中采用持续预训练,以弥补压缩带来的性能损失。这种方法旨在在尽可能减少性能损失的前提下,实现更高的压缩率。
技术框架:OpenBA-V2的训练流程主要包括以下几个阶段:首先,基于原始的15B OpenBA模型进行初始化。然后,进行多阶段的压缩,包括层剪枝、神经元剪枝和词汇表剪枝。在每个压缩阶段之后,进行持续预训练,以恢复模型性能。最终得到一个3.4B的模型。
关键创新:论文的关键创新在于结合了多阶段压缩和持续预训练。通过多阶段压缩,可以逐步减小模型尺寸,避免一次性大幅度压缩带来的性能损失。通过持续预训练,可以在压缩过程中不断地恢复模型性能,从而在保证压缩率的同时,尽可能地减少性能损失。
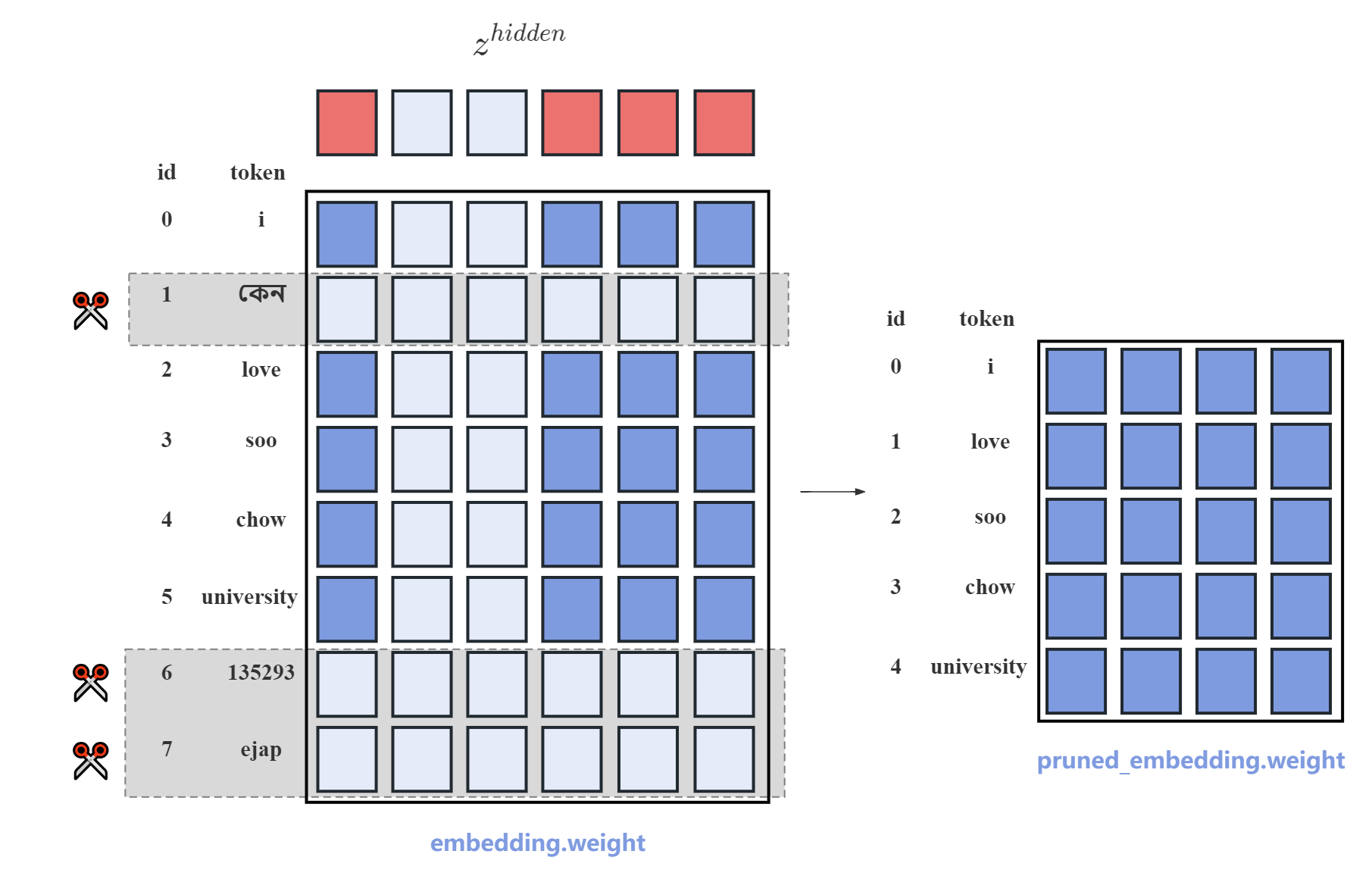
关键设计:论文采用了多种剪枝技术,包括层剪枝、神经元剪枝和词汇表剪枝。层剪枝是指移除模型中的部分层。神经元剪枝是指移除模型中的部分神经元。词汇表剪枝是指减小模型的词汇表大小。此外,论文还采用了更灵活的训练目标和数据策略,以进一步提高模型性能。具体的参数设置和损失函数等细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片

📊 实验亮点
OpenBA-V2实现了77.3%的压缩率,将模型从15B压缩到3.4B,同时在常识推理和命名实体识别(NER)等下游任务中取得了与原始15B OpenBA模型相近的性能。这表明通过多阶段压缩和持续预训练,可以在保证性能的同时显著减小模型尺寸。具体的性能数据和对比基线在论文中有详细展示,但这里无法给出具体数值。
🎯 应用场景
OpenBA-V2的潜在应用领域包括移动设备、嵌入式系统等资源受限的场景。通过将大型语言模型压缩到更小的尺寸,可以在这些场景下部署LLM,从而实现更广泛的应用。该研究的实际价值在于降低了LLM的部署成本,并为未来的模型压缩研究提供了新的思路。未来,可以进一步探索更有效的压缩方法,以实现更高的压缩率和更小的性能损失。
📄 摘要(原文)
Large Language Models (LLMs) have played an important role in many fields due to their powerful capabilities.However, their massive number of parameters leads to high deployment requirements and incurs significant inference costs, which impedes their practical applications. Training smaller models is an effective way to address this problem. Therefore, we introduce OpenBA-V2, a 3.4B model derived from multi-stage compression and continual pre-training from the original 15B OpenBA model. OpenBA-V2 utilizes more data, more flexible training objectives, and techniques such as layer pruning, neural pruning, and vocabulary pruning to achieve a compression rate of 77.3\% with minimal performance loss. OpenBA-V2 demonstrates competitive performance compared to other open-source models of similar size, achieving results close to or on par with the 15B OpenBA model in downstream tasks such as common sense reasoning and Named Entity Recognition (NER). OpenBA-V2 illustrates that LLMs can be compressed into smaller ones with minimal performance loss by employing advanced training objectives and data strategies, which may help deploy LLMs in resource-limited scenarios.