Experimental Pragmatics with Machines: Testing LLM Predictions for the Inferences of Plain and Embedded Disjunctions
作者: Polina Tsvilodub, Paul Marty, Sonia Ramotowska, Jacopo Romoli, Michael Franke
分类: cs.CL
发布日期: 2024-05-09
备注: 8 pages, 3 figures, to appear in the Proceedings of the 46th Annual Conference of the Cognitive Science Society (2024)
💡 一句话要点
利用大型语言模型预测析取推理,验证其在实验语用学中的应用潜力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 实验语用学 析取推理 语用推理 自然语言处理
📋 核心要点
- 现有语用学研究缺乏对大型语言模型在推理预测方面的系统性评估,限制了对模型认知能力的理解。
- 该研究采用实验语用学方法,利用大型语言模型预测析取推理,并与人类实验结果进行对比分析。
- 实验结果表明,性能最佳的模型在析取推理预测上与人类表现出高度一致性,验证了其应用潜力。
📝 摘要(中文)
人类交流依赖于从语句中推断出的各种信息,这些信息常常超出字面意义。尽管在蕴含、蕴涵和预设这三个基本概念的区分上存在广泛共识,但许多推论的状态仍存在争议。本文关注普通和嵌入式析取的三种推论,并将它们与常规标量蕴涵进行比较。我们从大型语言模型预测的新颖角度研究这种比较,使用与最近研究人类相同推论的实验范式。我们性能最佳的模型的结果在很大程度上与人类的结果一致,无论是在这些推论和蕴涵之间发现的巨大差异,还是在这些推论的不同方面之间的细微区别。
🔬 方法详解
问题定义:论文旨在研究大型语言模型(LLM)在处理析取推理(disjunctive inferences)时的能力,特别是普通析取和嵌入式析取。现有方法主要依赖于人工标注或基于规则的系统,缺乏对LLM在语用推理方面的深入评估,也难以捕捉人类推理的细微差别。
核心思路:论文的核心思路是利用实验语用学的方法,将LLM作为“受试者”,通过设计特定的实验范式,测试LLM对析取语句的理解和推理能力。通过对比LLM的预测结果与人类的实验数据,评估LLM在语用推理方面的表现,并分析其与人类推理的异同。
技术框架:论文采用的框架主要包括以下几个步骤:1) 选择合适的LLM模型;2) 设计实验范式,包括普通析取和嵌入式析取两种情况;3) 构建测试数据集,包含析取语句和可能的推论;4) 使用LLM对测试数据集进行预测,得到LLM的推理结果;5) 将LLM的推理结果与人类的实验数据进行对比分析,评估LLM的性能。
关键创新:该研究的关键创新在于将实验语用学的方法应用于评估LLM的推理能力,提供了一种新的视角和方法。通过对比LLM和人类的实验数据,可以更深入地了解LLM在语用推理方面的优势和局限性。此外,该研究关注析取推理,这是一种重要的语用现象,对于理解人类交流和构建智能对话系统具有重要意义。
关键设计:论文的关键设计包括:1) 实验范式的设计,需要保证能够有效诱导出析取推理;2) 测试数据集的构建,需要包含足够多的样本,并且覆盖不同的析取类型;3) 评估指标的选择,需要能够准确反映LLM的推理能力。具体参数设置和网络结构取决于所使用的LLM模型,论文中可能没有详细描述。
🖼️ 关键图片


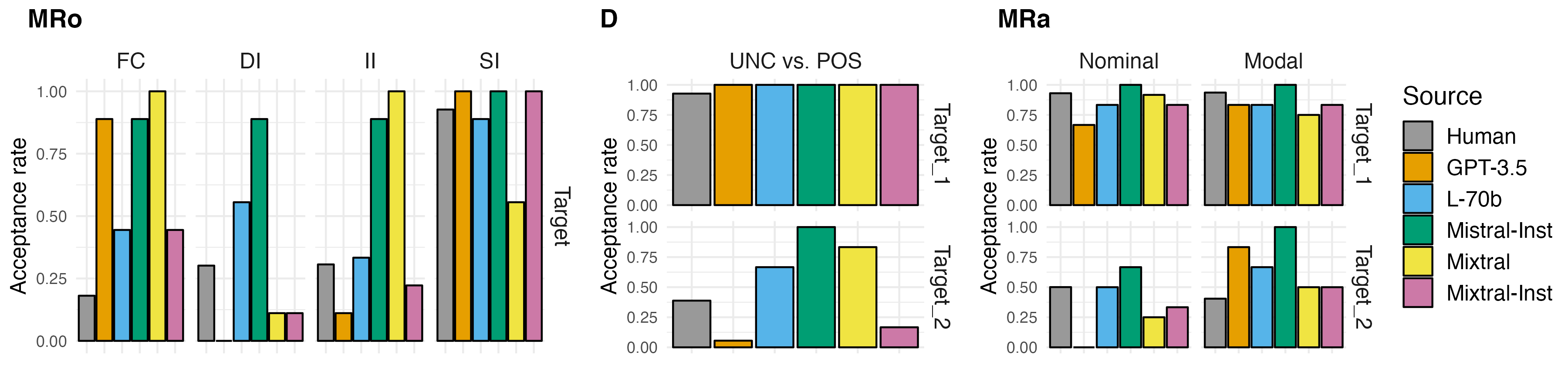
📊 实验亮点
实验结果表明,性能最佳的LLM模型在析取推理预测方面与人类表现出高度一致性,尤其是在区分析取推理和标量蕴涵方面。这表明LLM在一定程度上具备了人类的语用推理能力。此外,研究还发现LLM在处理不同类型的析取推理时存在差异,这为进一步改进LLM的推理能力提供了方向。
🎯 应用场景
该研究成果可应用于提升自然语言处理系统的语用推理能力,例如在对话系统中,使系统能够更好地理解用户的意图,并做出更合理的回复。此外,该研究还可以用于评估和改进LLM的认知能力,推动人工智能技术的发展。未来,该方法可以扩展到其他语用现象的研究,例如反讽、隐喻等。
📄 摘要(原文)
Human communication is based on a variety of inferences that we draw from sentences, often going beyond what is literally said. While there is wide agreement on the basic distinction between entailment, implicature, and presupposition, the status of many inferences remains controversial. In this paper, we focus on three inferences of plain and embedded disjunctions, and compare them with regular scalar implicatures. We investigate this comparison from the novel perspective of the predictions of state-of-the-art large language models, using the same experimental paradigms as recent studies investigating the same inferences with humans. The results of our best performing models mostly align with those of humans, both in the large differences we find between those inferences and implicatures, as well as in fine-grained distinctions among different aspects of those inferences.