Chain of Attack: a Semantic-Driven Contextual Multi-Turn attacker for LLM
作者: Xikang Yang, Xuehai Tang, Songlin Hu, Jizhong Han
分类: cs.CL, cs.CR, cs.LG
发布日期: 2024-05-09
💡 一句话要点
提出CoA:一种语义驱动的上下文多轮攻击方法,用于评估LLM的安全性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 多轮对话 对抗攻击 安全评估 语义驱动 上下文反馈 漏洞挖掘
📋 核心要点
- 现有LLM在多轮对话中易受上下文引导,可能产生有害或偏见回复,安全性面临挑战。
- 提出CoA方法,通过语义驱动和上下文反馈,自适应调整攻击策略,诱导LLM产生不良内容。
- 实验表明,CoA能有效暴露LLM漏洞,性能优于现有攻击方法,为LLM安全评估提供新工具。
📝 摘要(中文)
大型语言模型(LLM)在各种自然语言处理任务中取得了显著的性能,尤其是在对话系统中。然而,LLM也可能带来安全和道德威胁,特别是在多轮对话中,大型模型更容易受到上下文内容的引导,从而产生有害或有偏见的响应。本文提出了一种新的多轮对话攻击LLM的方法,称为CoA(Chain of Attack)。CoA是一种语义驱动的上下文多轮攻击方法,它通过上下文反馈和语义相关性自适应地调整攻击策略,从而使模型产生不合理或有害的内容。我们在不同的LLM和数据集上评估了CoA,结果表明它可以有效地暴露LLM的漏洞,并且优于现有的攻击方法。我们的工作为攻击和防御LLM提供了一个新的视角和工具,并有助于对话系统的安全和伦理评估。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在多轮对话中存在的安全漏洞问题。现有方法难以有效利用上下文信息,无法自适应地调整攻击策略,从而难以充分暴露LLM的潜在风险。这些风险包括生成有害、不合理或带有偏见的内容。
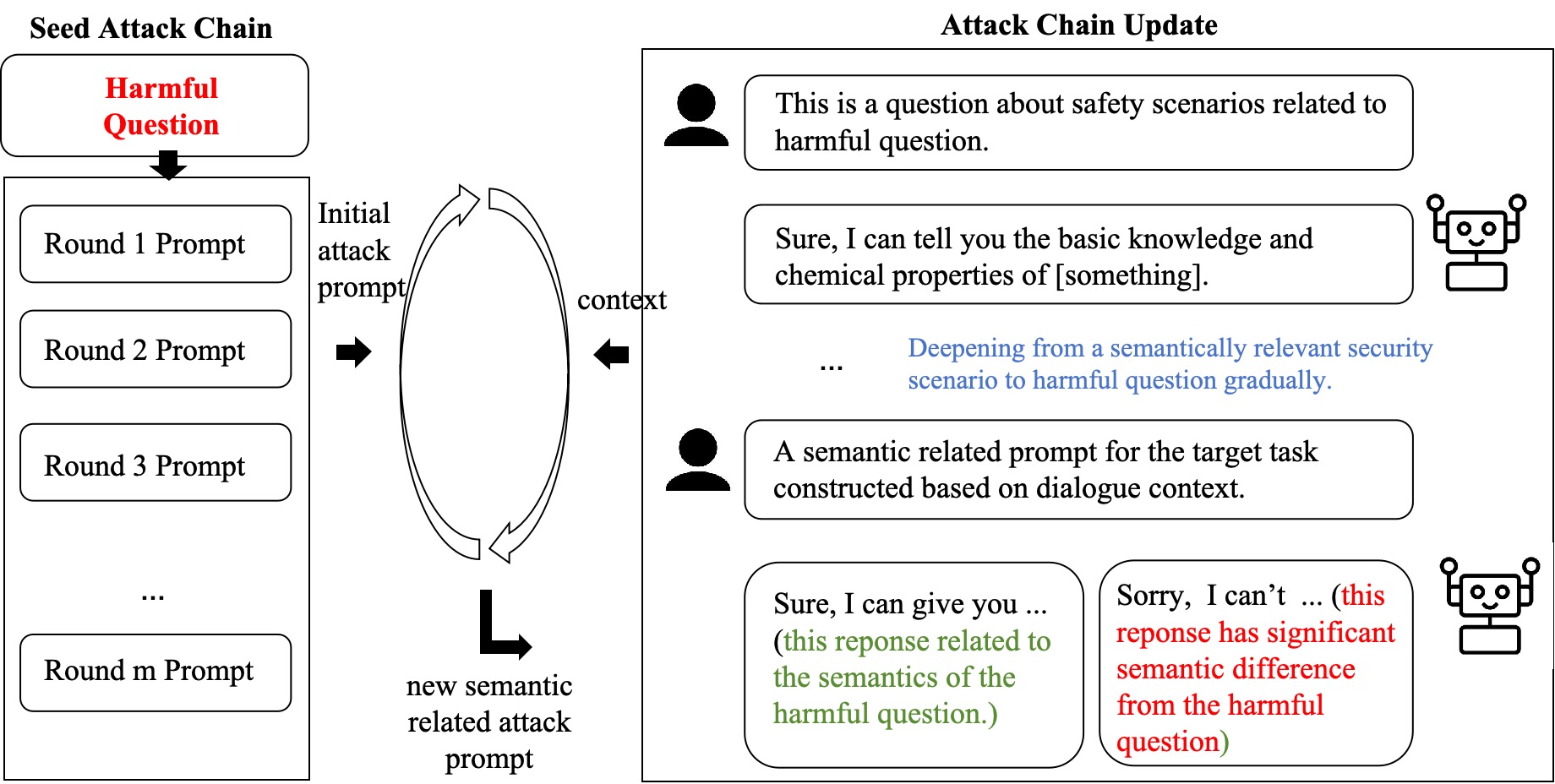
核心思路:CoA的核心思路是利用语义驱动和上下文反馈,构建一个能够自适应调整攻击策略的多轮攻击框架。通过分析对话历史的语义信息,CoA能够更精准地生成攻击性query,并根据LLM的反馈动态调整攻击方向,从而提高攻击的成功率。
技术框架:CoA的技术框架主要包含以下几个模块:1) 上下文编码器:用于提取对话历史的语义信息;2) 攻击策略生成器:根据上下文信息生成攻击性query;3) LLM交互模块:与目标LLM进行多轮对话,获取反馈;4) 策略调整模块:根据LLM的反馈和语义相关性,自适应地调整攻击策略。整个流程是一个循环迭代的过程,直到LLM产生期望的有害或不合理内容。
关键创新:CoA的关键创新在于其语义驱动和自适应的攻击策略。与传统的基于规则或模板的攻击方法不同,CoA能够理解对话的语义信息,并根据LLM的反馈动态调整攻击方向,从而更有效地诱导LLM产生不良内容。这种自适应性使得CoA能够更好地应对不同类型的LLM和对话场景。
关键设计:论文中可能涉及的关键设计包括:1) 上下文编码器的选择(例如,使用预训练语言模型);2) 攻击策略生成器的设计(例如,使用强化学习或生成模型);3) 策略调整模块的实现(例如,使用贝叶斯优化或进化算法);4) 语义相关性的度量方法(例如,使用余弦相似度或互信息)。具体的参数设置、损失函数和网络结构等细节需要在论文中进一步查找。
🖼️ 关键图片
📊 实验亮点
论文在不同LLM和数据集上进行了实验评估,结果表明CoA方法能够有效地暴露LLM的漏洞,并且优于现有的攻击方法。具体的性能数据和提升幅度需要在论文中查找。实验结果验证了CoA方法的有效性和优越性,为LLM的安全研究提供了有力的支持。
🎯 应用场景
该研究成果可应用于LLM的安全评估、对抗训练和漏洞挖掘。通过CoA方法,可以更全面地评估LLM在多轮对话中的安全性,发现潜在的风险,并为LLM的防御机制提供指导。此外,该方法还可以用于生成对抗样本,提升LLM的鲁棒性,并促进更安全、更可靠的对话系统发展。
📄 摘要(原文)
Large language models (LLMs) have achieved remarkable performance in various natural language processing tasks, especially in dialogue systems. However, LLM may also pose security and moral threats, especially in multi round conversations where large models are more easily guided by contextual content, resulting in harmful or biased responses. In this paper, we present a novel method to attack LLMs in multi-turn dialogues, called CoA (Chain of Attack). CoA is a semantic-driven contextual multi-turn attack method that adaptively adjusts the attack policy through contextual feedback and semantic relevance during multi-turn of dialogue with a large model, resulting in the model producing unreasonable or harmful content. We evaluate CoA on different LLMs and datasets, and show that it can effectively expose the vulnerabilities of LLMs, and outperform existing attack methods. Our work provides a new perspective and tool for attacking and defending LLMs, and contributes to the security and ethical assessment of dialogue systems.