Can We Use Large Language Models to Fill Relevance Judgment Holes?
作者: Zahra Abbasiantaeb, Chuan Meng, Leif Azzopardi, Mohammad Aliannejadi
分类: cs.IR, cs.CL
发布日期: 2024-05-09
💡 一句话要点
利用大型语言模型填补相关性判断缺失,扩展测试集以提升检索系统评估的可靠性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 相关性判断 信息检索 测试集扩展 对话式搜索
📋 核心要点
- 现有测试集因相关性判断不完整,导致新检索系统评估时面临不公平性,存在未评估文档造成的“漏洞”。
- 利用大型语言模型(LLM),基于现有的人工判断,自动填补测试集中的相关性判断“漏洞”,以扩展测试集。
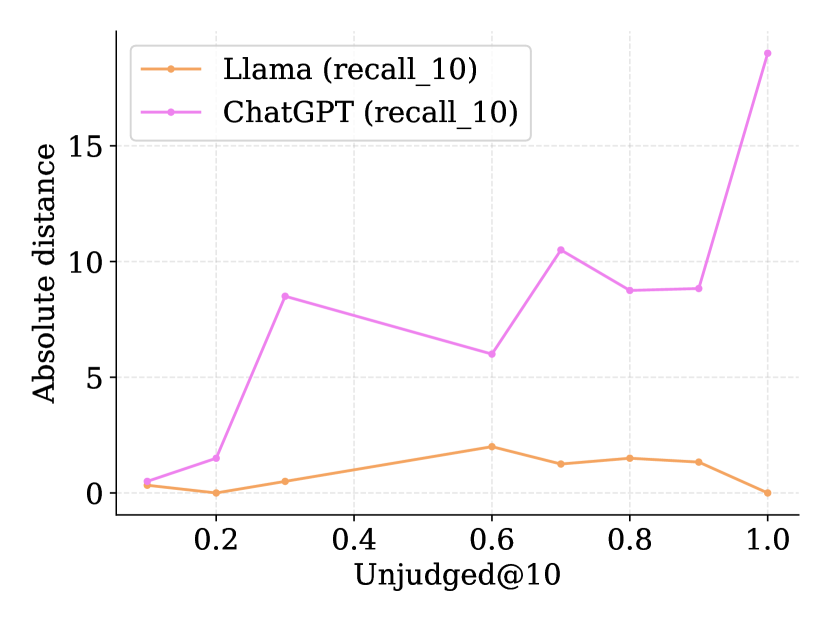
- 实验表明,直接使用LLM填补漏洞可能导致评估偏差,建议对整个文档池进行LLM标注以获得更一致的排名。
📝 摘要(中文)
不完整的相关性判断限制了测试集的可重用性。当新的系统与之前用于构建判断文档池的系统进行比较时,由于测试集中的“漏洞”(即新系统返回的未评估文档),它们通常处于不利地位。本文初步尝试通过使用大型语言模型(LLM)来填补这些漏洞,从而扩展现有的测试集,利用并基于现有的人工判断来完成此方法。我们使用TREC iKAT在对话式搜索的背景下探索了这个问题,其中信息需求是高度动态的,并且响应(以及检索到的结果)更加多样化(留下更大的漏洞)。虽然之前的工作表明来自LLM的自动判断会导致高度相关的排名,但我们发现当使用人工加自动判断时,相关性显著降低(无论LLM、one/two/few shot或微调)。我们进一步发现,根据所使用的LLM,新的运行将受到高度的青睐(或惩罚),并且这种影响与漏洞的大小成比例地放大。相反,应该在整个文档池上生成LLM注释,以实现与人工生成的标签更一致的排名。未来的工作需要提示工程和微调LLM,以反映和表示人工注释,以便对模型进行 grounding 和对齐,使其更适合目标。
🔬 方法详解
问题定义:论文旨在解决信息检索测试集中由于相关性判断不完整而导致的问题。具体来说,当评估新的检索系统时,如果该系统返回了测试集中未被人工评估的文档(即“漏洞”),则评估结果可能存在偏差,从而影响测试集的可靠性和可重用性。现有方法依赖于人工标注,成本高昂且难以覆盖所有可能的文档。
核心思路:论文的核心思路是利用大型语言模型(LLM)的强大文本理解和生成能力,自动预测未评估文档的相关性,从而填补测试集中的“漏洞”。通过将LLM的预测与现有的人工判断相结合,可以扩展测试集的覆盖范围,并提高评估的准确性和公平性。
技术框架:该方法主要包含以下几个阶段:1) 选择合适的LLM模型;2) 设计合适的prompt,引导LLM进行相关性判断;3) 利用LLM对未评估文档进行相关性预测;4) 将LLM的预测结果与现有的人工判断相结合,构建扩展后的测试集;5) 使用扩展后的测试集评估检索系统的性能,并与使用原始测试集的结果进行比较。
关键创新:该论文的关键创新在于探索了利用LLM自动填补信息检索测试集漏洞的可行性。与以往依赖人工标注的方法相比,该方法可以显著降低成本并提高效率。此外,论文还深入分析了LLM预测结果对评估结果的影响,并提出了相应的改进建议。
关键设计:论文实验中考察了不同类型的LLM(如不同规模的模型,以及经过微调的模型),并尝试了不同的prompt策略(如one-shot、few-shot等)。此外,论文还分析了LLM预测结果与人工判断之间的相关性,以及LLM预测结果对不同检索系统的影响。论文建议在整个文档池上生成LLM注释,以获得与人工生成的标签更一致的排名。
🖼️ 关键图片

📊 实验亮点
实验结果表明,直接使用LLM填补漏洞可能导致评估偏差,具体表现为某些检索系统被过度青睐或惩罚,且偏差程度与漏洞大小成正比。为了解决这个问题,论文建议对整个文档池进行LLM标注,以获得与人工标注更一致的排名。实验还发现,不同LLM的表现存在差异,需要根据具体应用场景选择合适的模型。
🎯 应用场景
该研究成果可应用于信息检索系统评估、测试集构建和维护等领域。通过自动填补相关性判断缺失,可以降低测试集构建成本,提高评估的准确性和可靠性,从而促进信息检索技术的进步。此外,该方法还可以应用于其他需要人工标注的领域,如文本分类、情感分析等。
📄 摘要(原文)
Incomplete relevance judgments limit the re-usability of test collections. When new systems are compared against previous systems used to build the pool of judged documents, they often do so at a disadvantage due to the ``holes'' in test collection (i.e., pockets of un-assessed documents returned by the new system). In this paper, we take initial steps towards extending existing test collections by employing Large Language Models (LLM) to fill the holes by leveraging and grounding the method using existing human judgments. We explore this problem in the context of Conversational Search using TREC iKAT, where information needs are highly dynamic and the responses (and, the results retrieved) are much more varied (leaving bigger holes). While previous work has shown that automatic judgments from LLMs result in highly correlated rankings, we find substantially lower correlates when human plus automatic judgments are used (regardless of LLM, one/two/few shot, or fine-tuned). We further find that, depending on the LLM employed, new runs will be highly favored (or penalized), and this effect is magnified proportionally to the size of the holes. Instead, one should generate the LLM annotations on the whole document pool to achieve more consistent rankings with human-generated labels. Future work is required to prompt engineering and fine-tuning LLMs to reflect and represent the human annotations, in order to ground and align the models, such that they are more fit for purpose.