OpenFactCheck: Building, Benchmarking Customized Fact-Checking Systems and Evaluating the Factuality of Claims and LLMs
作者: Yuxia Wang, Minghan Wang, Hasan Iqbal, Georgi Georgiev, Jiahui Geng, Preslav Nakov
分类: cs.CL
发布日期: 2024-05-09 (更新: 2025-10-28)
备注: 23 pages, 8 tables, 11 figures, Published In Proceedings of the 31st International Conference on Computational Linguistics 2025
期刊: In Proceedings of the 31st International Conference on Computational Linguistics 2025, pages 11399-11421, Abu Dhabi, UAE. Association for Computational Linguistics
🔗 代码/项目: GITHUB
💡 一句话要点
OpenFactCheck:构建、评估定制化事实核查系统,评估声明和LLM的事实性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 事实核查 大型语言模型 信息验证 自然语言处理 评估框架
📋 核心要点
- 现有方法难以评估开放领域中LLM生成内容的真实性,且缺乏统一的评估标准。
- OpenFactCheck框架旨在提供定制化事实核查系统,并统一评估LLM的事实性能力。
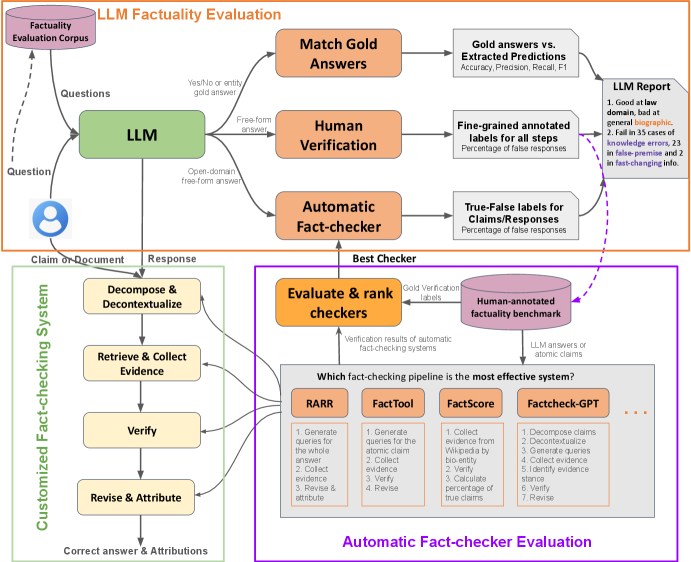
- 该框架包含CUSTCHECKER、LLMEVAL和CHECKEREVAL三个模块,分别用于定制核查器、评估LLM和评估核查器。
📝 摘要(中文)
大型语言模型(LLMs)在各种实际应用中的日益普及,需要验证其输出的事实准确性的机制。评估开放领域中自由形式响应的事实性存在困难。此外,不同的论文使用不同的评估基准和测量方法,这使得它们难以比较,并阻碍了未来的进展。为了缓解这些问题,我们提出了OpenFactCheck,一个统一的框架,用于构建定制化的自动事实核查系统,评估它们的准确性,评估LLM的事实性,并验证文档中的声明。OpenFactCheck由三个模块组成:(i)CUSTCHECKER允许用户轻松定制自动事实核查器,并验证文档和声明的事实正确性,(ii)LLMEVAL,一个统一的评估框架,从各个角度公平地评估LLM的事实性能力,以及(iii)CHECKEREVAL,一个可扩展的解决方案,用于使用人工标注的数据集来衡量自动事实核查器验证结果的可靠性。数据和代码可在https://github.com/yuxiaw/openfactcheck公开获取。
🔬 方法详解
问题定义:当前,大型语言模型(LLMs)生成内容的真实性验证是一个重要问题。现有的事实核查方法通常依赖于特定的数据集和评估指标,缺乏通用性和可比性。此外,针对开放领域的自由文本生成内容的事实性评估仍然是一个挑战。
核心思路:OpenFactCheck的核心思路是提供一个统一的框架,允许用户构建定制化的事实核查系统,并使用统一的评估标准来评估LLM生成内容的事实性。通过模块化的设计,用户可以根据自己的需求选择和配置不同的组件,从而实现灵活的事实核查。
技术框架:OpenFactCheck框架包含三个主要模块:CUSTCHECKER、LLMEVAL和CHECKEREVAL。CUSTCHECKER允许用户定制自动事实核查器,并验证文档和声明的事实正确性。LLMEVAL是一个统一的评估框架,从各个角度评估LLM的事实性能力。CHECKEREVAL使用人工标注的数据集来衡量自动事实核查器验证结果的可靠性。整个流程包括数据输入、事实核查、结果评估和系统优化。
关键创新:OpenFactCheck的关键创新在于提供了一个统一的、可定制的事实核查框架。与以往的研究相比,OpenFactCheck不仅关注事实核查的准确性,还关注核查系统的可靠性和可扩展性。此外,OpenFactCheck还提供了一个统一的评估标准,使得不同事实核查系统的性能可以进行公平的比较。
关键设计:CUSTCHECKER模块允许用户选择不同的事实核查算法和数据源,并根据自己的需求进行配置。LLMEVAL模块提供了一系列评估指标,包括准确率、召回率和F1值等,用于评估LLM生成内容的事实性。CHECKEREVAL模块使用人工标注的数据集来评估自动事实核查器的可靠性,并提供了一些诊断工具,帮助用户发现和解决核查系统中的问题。具体的参数设置、损失函数和网络结构等技术细节取决于用户选择的具体算法和数据源。
🖼️ 关键图片


📊 实验亮点
OpenFactCheck提供了一个统一的框架,可以方便地构建和评估定制化的事实核查系统。通过LLMEVAL模块,可以从多个角度评估LLM的事实性能力,并进行公平的比较。CHECKEREVAL模块可以评估自动事实核查器的可靠性,并提供诊断工具。具体实验结果未知,但该框架的提出为事实核查领域的研究提供了一个有力的工具。
🎯 应用场景
OpenFactCheck可应用于新闻媒体、社交平台、教育领域等,用于验证信息的真实性,防止虚假信息的传播。该研究有助于提高LLM生成内容的可靠性,促进人工智能技术在各个领域的应用。未来,OpenFactCheck可以扩展到支持更多语言和数据类型,并集成更多先进的事实核查算法。
📄 摘要(原文)
The increased use of large language models (LLMs) across a variety of real-world applications calls for mechanisms to verify the factual accuracy of their outputs. Difficulties lie in assessing the factuality of free-form responses in open domains. Also, different papers use disparate evaluation benchmarks and measurements, which renders them hard to compare and hampers future progress. To mitigate these issues, we propose OpenFactCheck, a unified framework for building customized automatic fact-checking systems, benchmarking their accuracy, evaluating factuality of LLMs, and verifying claims in a document. OpenFactCheck consists of three modules: (i) CUSTCHECKER allows users to easily customize an automatic fact-checker and verify the factual correctness of documents and claims, (ii) LLMEVAL, a unified evaluation framework assesses LLM's factuality ability from various perspectives fairly, and (iii) CHECKEREVAL is an extensible solution for gauging the reliability of automatic fact-checkers' verification results using human-annotated datasets. Data and code are publicly available at https://github.com/yuxiaw/openfactcheck.