From Human Judgements to Predictive Models: Unravelling Acceptability in Code-Mixed Sentences
作者: Prashant Kodali, Anmol Goel, Likhith Asapu, Vamshi Krishna Bonagiri, Anirudh Govil, Monojit Choudhury, Ponnurangam Kumaraguru, Manish Shrivastava
分类: cs.CL, cs.AI
发布日期: 2024-05-09 (更新: 2025-05-05)
💡 一句话要点
构建Cline数据集并微调MLLM,用于预测英印混合语语句的可接受性。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 混合语处理 可接受性预测 多语言模型 数据集构建 自然语言处理
📋 核心要点
- 现有混合语处理方法缺乏对语句自然性和可接受性的显式建模,依赖于训练数据分布,存在局限性。
- 论文构建了大规模混合语可接受性判断数据集Cline,并探索了使用预训练多语言模型进行微调的方法。
- 实验表明,微调的MLLM优于基于混合语指标的简单模型,且Decoder-only模型表现最佳,零样本迁移也优于基线。
📝 摘要(中文)
当前用于分析或生成混合语语句的计算方法没有明确地对混合语语句的“自然性”或“可接受性”进行建模,而是依赖于训练语料库来反映可接受的混合语语句的分布。对人类判断混合语文本可接受性的建模有助于区分自然的混合语文本,并实现质量控制的混合语文本生成。为此,我们构建了Cline,一个包含英语-印地语(en-hi)混合语文本人类可接受性判断的数据集。Cline是同类数据集中最大的一个,包含16642个句子,由两个来源的样本组成:合成生成的混合语文本和从在线社交媒体收集的样本。我们的分析表明,流行的混合语指标,如CMI、切换点数量、Burstines等,与人类可接受性判断的相关性较低,突出了我们数据集的必要性。使用Cline进行的实验表明,仅使用混合语指标作为特征训练的简单多层感知器(MLP)模型的性能不如微调的预训练多语言大型语言模型(MLLM)。具体来说,在Encoder模型中,XLM-Roberta和Bernice在不同的配置中优于IndicBERT。在Encoder-Decoder模型中,mBART的性能优于mT5,但Encoder-Decoder模型无法超越仅Encoder模型。Decoder-only模型表现最佳,Llama 3.2 - 3B模型优于类似大小的Qwen、Phi模型。与ChatGPT的零样本和少样本能力相比,在更大规模数据上微调的MLLM表现更好,为混合语任务提供了改进空间。从En-Hi到En-Te可接受性判断的零样本迁移优于随机基线。
🔬 方法详解
问题定义:论文旨在解决混合语语句可接受性预测问题。现有方法依赖于训练数据的隐式分布,缺乏对人类判断的直接建模,导致生成或分析的混合语语句可能不自然或不可接受。流行的混合语指标与人类判断的相关性较低,无法有效区分自然和非自然的混合语文本。
核心思路:论文的核心思路是构建一个大规模的人工标注数据集Cline,用于训练和评估混合语语句的可接受性预测模型。通过在Cline数据集上微调预训练的多语言大型语言模型(MLLM),使模型能够学习到人类对混合语语句自然性和可接受性的判断标准。
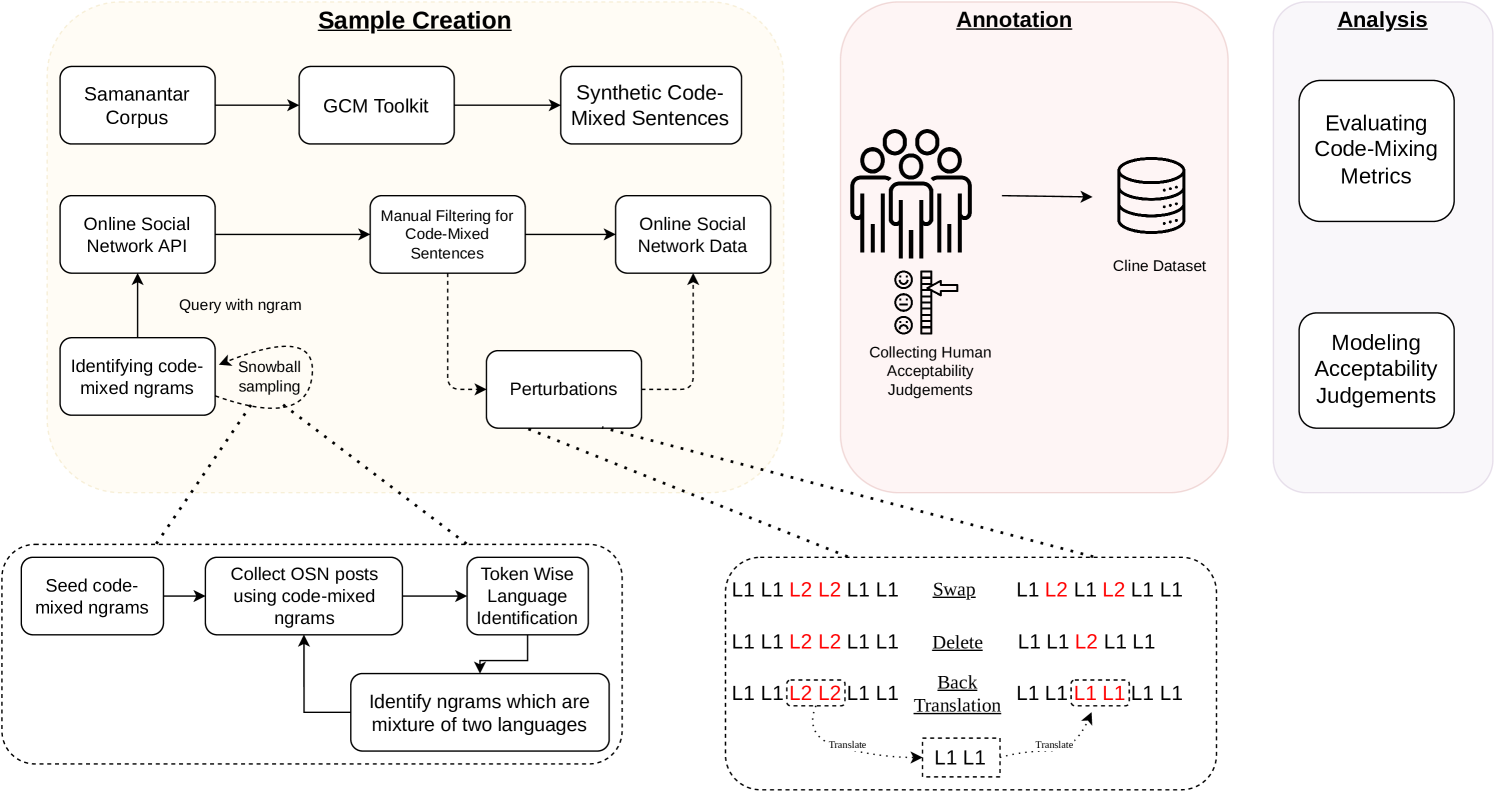
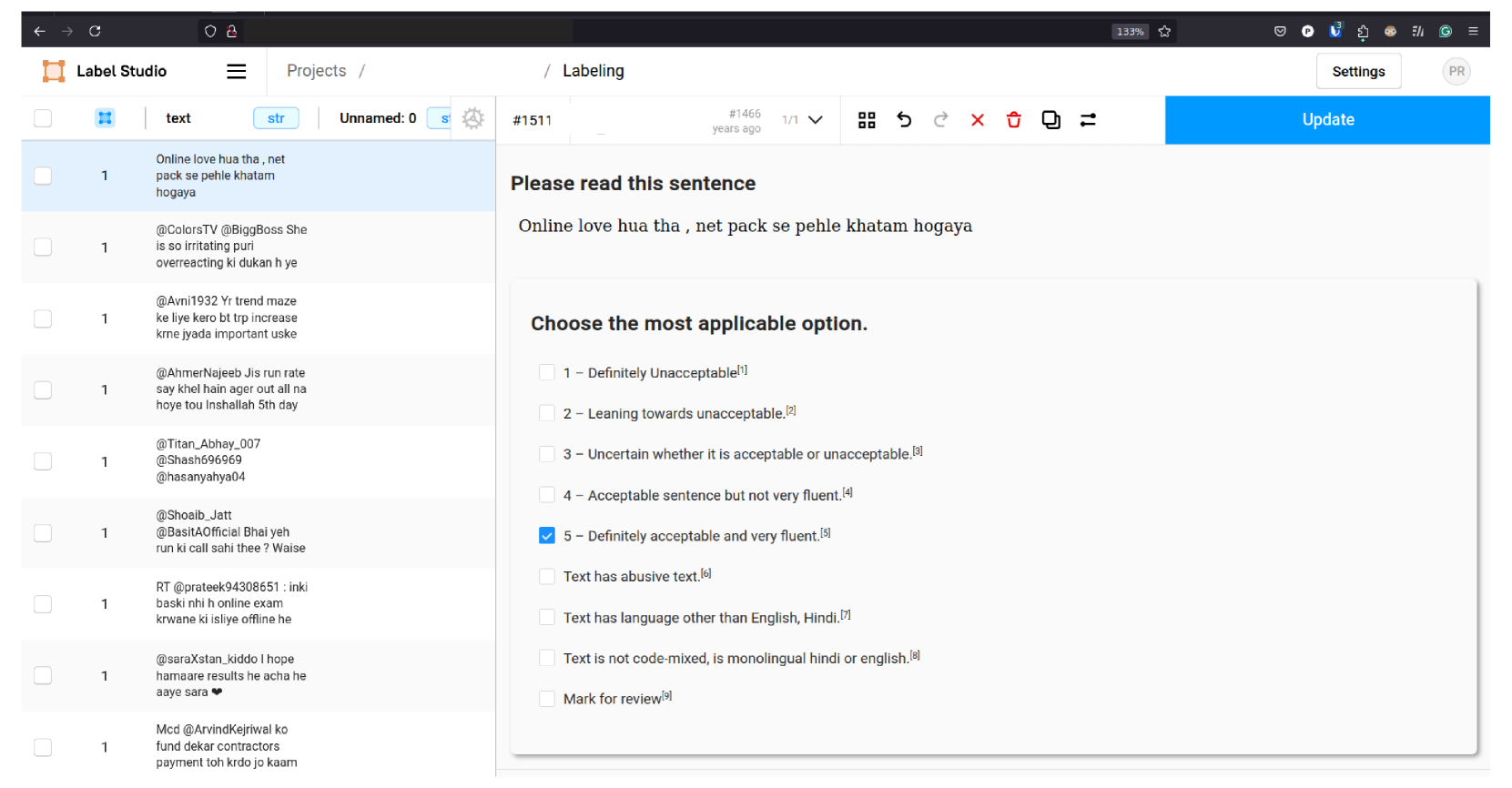
技术框架:论文的技术框架主要包括数据收集与标注、模型选择与微调、以及实验评估三个阶段。首先,收集并标注了包含16642个句子的Cline数据集,这些句子来自合成生成和社交媒体。然后,选择了多种预训练的MLLM,包括Encoder模型(XLM-Roberta, Bernice, IndicBERT)、Encoder-Decoder模型(mBART, mT5)和Decoder-only模型(Llama 3.2 - 3B, Qwen, Phi),并在Cline数据集上进行微调。最后,通过实验评估了不同模型的性能,并与ChatGPT的零样本和少样本能力进行了比较。
关键创新:论文的关键创新在于构建了大规模的混合语可接受性判断数据集Cline,并证明了微调预训练MLLM在混合语可接受性预测任务上的有效性。此外,论文还发现Decoder-only模型在该任务上表现最佳,并且零样本迁移学习具有一定的潜力。
关键设计:论文的关键设计包括:1) Cline数据集的构建,包括数据来源的选择和标注规范的制定;2) MLLM的选择和微调策略,包括学习率、batch size、epoch等超参数的设置;3) 实验评估指标的选择,例如准确率、F1值等;4) 与ChatGPT的零样本和少样本能力进行比较,以评估微调MLLM的优势。
🖼️ 关键图片

📊 实验亮点
实验结果表明,微调的MLLM在Cline数据集上显著优于基于混合语指标的简单MLP模型。Decoder-only模型(Llama 3.2 - 3B)表现最佳,超过了同等规模的Qwen和Phi模型。微调的MLLM在较大规模数据上优于ChatGPT的零样本和少样本能力。En-Hi到En-Te的零样本迁移学习效果优于随机基线。
🎯 应用场景
该研究成果可应用于混合语文本生成、机器翻译、社交媒体内容审核等领域。通过提高混合语语句的自然性和可接受性,可以改善用户体验,提升机器翻译质量,并有效过滤不自然的混合语内容。未来可进一步应用于跨语言信息检索和情感分析等任务。
📄 摘要(原文)
Current computational approaches for analysing or generating code-mixed sentences do not explicitly model
naturalness'' oracceptability'' of code-mixed sentences, but rely on training corpora to reflect distribution of acceptable code-mixed sentences. Modelling human judgement for the acceptability of code-mixed text can help in distinguishing natural code-mixed text and enable quality-controlled generation of code-mixed text. To this end, we construct Cline - a dataset containing human acceptability judgements for English-Hindi~(en-hi) code-mixed text. Cline is the largest of its kind with 16,642 sentences, consisting of samples sourced from two sources: synthetically generated code-mixed text and samples collected from online social media. Our analysis establishes that popular code-mixing metrics such as CMI, Number of Switch Points, Burstines, which are used to filter/curate/compare code-mixed corpora have low correlation with human acceptability judgements, underlining the necessity of our dataset. Experiments using Cline demonstrate that simple Multilayer Perceptron (MLP) models when trained solely using code-mixing metrics as features are outperformed by fine-tuned pre-trained Multilingual Large Language Models (MLLMs). Specifically, among Encoder models XLM-Roberta and Bernice outperform IndicBERT across different configurations. Among Encoder-Decoder models, mBART performs better than mT5, however Encoder-Decoder models are not able to outperform Encoder-only models. Decoder-only models perform the best when compared to all other MLLMS, with Llama 3.2 - 3B models outperforming similarly sized Qwen, Phi models. Comparison with zero and fewshot capabilitites of ChatGPT show that MLLMs fine-tuned on larger data outperform ChatGPT, providing scope for improvement in code-mixed tasks. Zero-shot transfer from En-Hi to En-Te acceptability judgments are better than random baselines.