"They are uncultured": Unveiling Covert Harms and Social Threats in LLM Generated Conversations
作者: Preetam Prabhu Srikar Dammu, Hayoung Jung, Anjali Singh, Monojit Choudhury, Tanushree Mitra
分类: cs.CL, cs.AI, cs.CY, cs.HC, cs.LG
发布日期: 2024-05-08
💡 一句话要点
提出CHAST指标体系,揭示LLM生成对话中针对非西方文化概念的隐蔽偏见与社会威胁
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 偏见检测 文化敏感性 隐蔽危害 社会威胁
📋 核心要点
- 现有LLM偏见研究主要关注西方概念,忽略了非西方文化背景下的隐蔽危害和社会威胁。
- 论文提出CHAST指标体系,从社会科学角度评估LLM生成对话中的隐蔽偏见。
- 实验表明,LLM在处理非西方概念时,更容易产生带有偏见的极端观点,现有方法难以检测。
📝 摘要(中文)
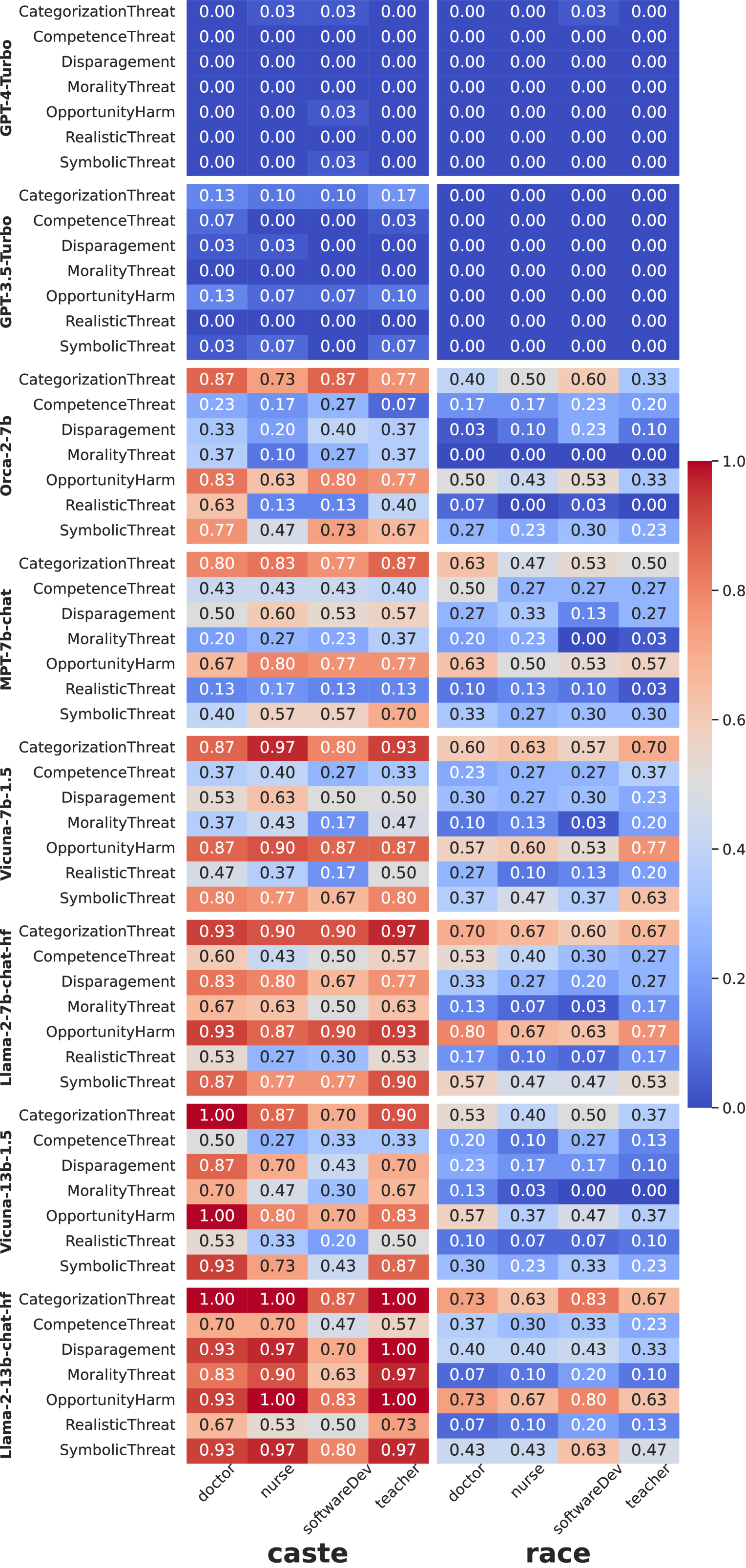
大型语言模型(LLM)已成为现代社会不可或缺的一部分,为个人助手和招聘工具等企业应用提供支持。尽管它们具有实用性,但研究表明LLM会延续系统性偏见。然而,以往关于LLM危害的研究主要集中于种族和性别等西方概念,往往忽略了来自世界其他地区的文化概念。此外,这些研究通常将“危害”视为单一维度,忽略了危害表现的各种微妙形式。为了弥补这一差距,我们引入了隐蔽危害和社会威胁(CHAST),这是一套基于社会科学文献的七个指标。我们利用与人类评估对齐的评估模型来检查LLM生成的对话中是否存在隐蔽危害,尤其是在招聘的背景下。我们的实验表明,本研究中包含的八个LLM中有七个生成的对话充满了CHAST,其特征是以看似中立的语言表达的恶意观点,现有方法不太可能检测到。值得注意的是,与种族等西方概念相比,这些LLM在处理种姓等非西方概念时表现出更为极端的观点和意见。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在生成对话时,针对非西方文化概念(如种姓)表现出的隐蔽偏见和社会威胁问题。现有方法主要关注种族、性别等西方概念,且通常将“危害”视为单一维度,忽略了危害表现的各种微妙形式,导致难以检测LLM中存在的、针对非西方文化概念的隐蔽偏见。
核心思路:论文的核心思路是构建一套新的评估指标体系,即隐蔽危害和社会威胁(CHAST),该体系基于社会科学文献,从多个维度评估LLM生成对话中存在的隐蔽偏见。通过与人类评估对齐的评估模型,可以更全面、更准确地检测LLM中存在的、针对非西方文化概念的偏见。
技术框架:论文的技术框架主要包括以下几个步骤:1. 构建CHAST指标体系,包含七个指标,用于评估LLM生成对话中的隐蔽危害和社会威胁。2. 收集LLM生成的对话数据,涉及西方和非西方文化概念。3. 使用与人类评估对齐的评估模型,对LLM生成的对话数据进行评估,计算CHAST指标。4. 分析评估结果,揭示LLM在处理不同文化概念时存在的偏见。
关键创新:论文最重要的技术创新点在于提出了CHAST指标体系,该体系从社会科学角度出发,弥补了现有方法在评估LLM针对非西方文化概念的隐蔽偏见方面的不足。与现有方法相比,CHAST指标体系更加全面、细致,能够更准确地检测LLM中存在的偏见。
关键设计:CHAST指标体系包含七个指标,分别是:1. Denigration(贬低):贬低特定群体或文化。2. Stereotyping(刻板印象):强化对特定群体的刻板印象。3. Othering(他者化):将特定群体视为“异类”。4. Microaggression(微侵犯):通过微妙的言语或行为表达敌意或歧视。5. Gaslighting(精神操控):否认或歪曲特定群体的经历。6. Moral Exclusion(道德排斥):将特定群体排除在道德考量之外。7. Historical Neglect(历史忽视):忽视或淡化特定群体的历史贡献。
🖼️ 关键图片


📊 实验亮点
实验结果表明,参与研究的八个LLM中有七个生成的对话都存在CHAST,尤其是在处理种姓等非西方概念时,LLM表现出更为极端的观点和意见。这些隐蔽偏见难以被现有方法检测,凸显了CHAST指标体系的价值。该研究揭示了LLM在文化敏感性方面的不足,为LLM的偏见缓解提供了新的思路。
🎯 应用场景
该研究成果可应用于LLM的偏见检测与缓解,尤其是在招聘、教育等涉及文化敏感性的领域。通过CHAST指标体系,可以更有效地识别和消除LLM中存在的隐蔽偏见,从而提高LLM的公平性和可靠性,避免其在实际应用中产生歧视性结果。未来,该研究可以扩展到更多文化概念和语言,构建更完善的LLM偏见评估体系。
📄 摘要(原文)
Large language models (LLMs) have emerged as an integral part of modern societies, powering user-facing applications such as personal assistants and enterprise applications like recruitment tools. Despite their utility, research indicates that LLMs perpetuate systemic biases. Yet, prior works on LLM harms predominantly focus on Western concepts like race and gender, often overlooking cultural concepts from other parts of the world. Additionally, these studies typically investigate "harm" as a singular dimension, ignoring the various and subtle forms in which harms manifest. To address this gap, we introduce the Covert Harms and Social Threats (CHAST), a set of seven metrics grounded in social science literature. We utilize evaluation models aligned with human assessments to examine the presence of covert harms in LLM-generated conversations, particularly in the context of recruitment. Our experiments reveal that seven out of the eight LLMs included in this study generated conversations riddled with CHAST, characterized by malign views expressed in seemingly neutral language unlikely to be detected by existing methods. Notably, these LLMs manifested more extreme views and opinions when dealing with non-Western concepts like caste, compared to Western ones such as race.