You Only Cache Once: Decoder-Decoder Architectures for Language Models
作者: Yutao Sun, Li Dong, Yi Zhu, Shaohan Huang, Wenhui Wang, Shuming Ma, Quanlu Zhang, Jianyong Wang, Furu Wei
分类: cs.CL
发布日期: 2024-05-08 (更新: 2024-05-09)
💡 一句话要点
YOCO:一种仅缓存一次键值对的Decoder-Decoder架构,提升大语言模型效率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Decoder-Decoder架构 语言模型 长上下文建模 键值缓存 推理加速
📋 核心要点
- 现有Decoder-only Transformer在大模型推理时需要重复缓存KV对,导致内存占用高、预填充慢。
- YOCO架构通过自解码器编码全局KV缓存,再由交叉解码器重用,实现单次缓存,降低内存需求。
- 实验表明,YOCO在长上下文和大规模模型下,显著提升推理速度和吞吐量,并保持性能。
📝 摘要(中文)
本文提出了一种用于大型语言模型的decoder-decoder架构,名为YOCO,其核心思想是仅缓存一次键值对(key-value pairs)。该架构由一个堆叠在自解码器(self-decoder)之上的交叉解码器(cross-decoder)组成。自解码器高效地编码全局键值(KV)缓存,这些缓存通过交叉注意力被交叉解码器重用。整体模型表现得像一个decoder-only Transformer,但YOCO仅缓存一次。这种设计显著降低了GPU内存需求,同时保留了全局注意力能力。此外,计算流程使得预填充(prefilling)能够提前退出而不会改变最终输出,从而显著加速了预填充阶段。实验结果表明,在扩展模型大小和训练token数量的各种设置中,YOCO相比Transformer取得了良好的性能。我们还将YOCO扩展到1M上下文长度,并实现了接近完美的needle检索准确率。性能分析结果表明,在各种上下文长度和模型大小下,YOCO在推理内存、预填充延迟和吞吐量方面都提高了几个数量级。
🔬 方法详解
问题定义:现有Decoder-only Transformer架构在处理长序列时,需要在每一层都缓存所有token的key和value向量,导致内存占用随序列长度线性增长。这限制了模型能够处理的上下文长度,并增加了推理时的延迟,尤其是在预填充阶段。
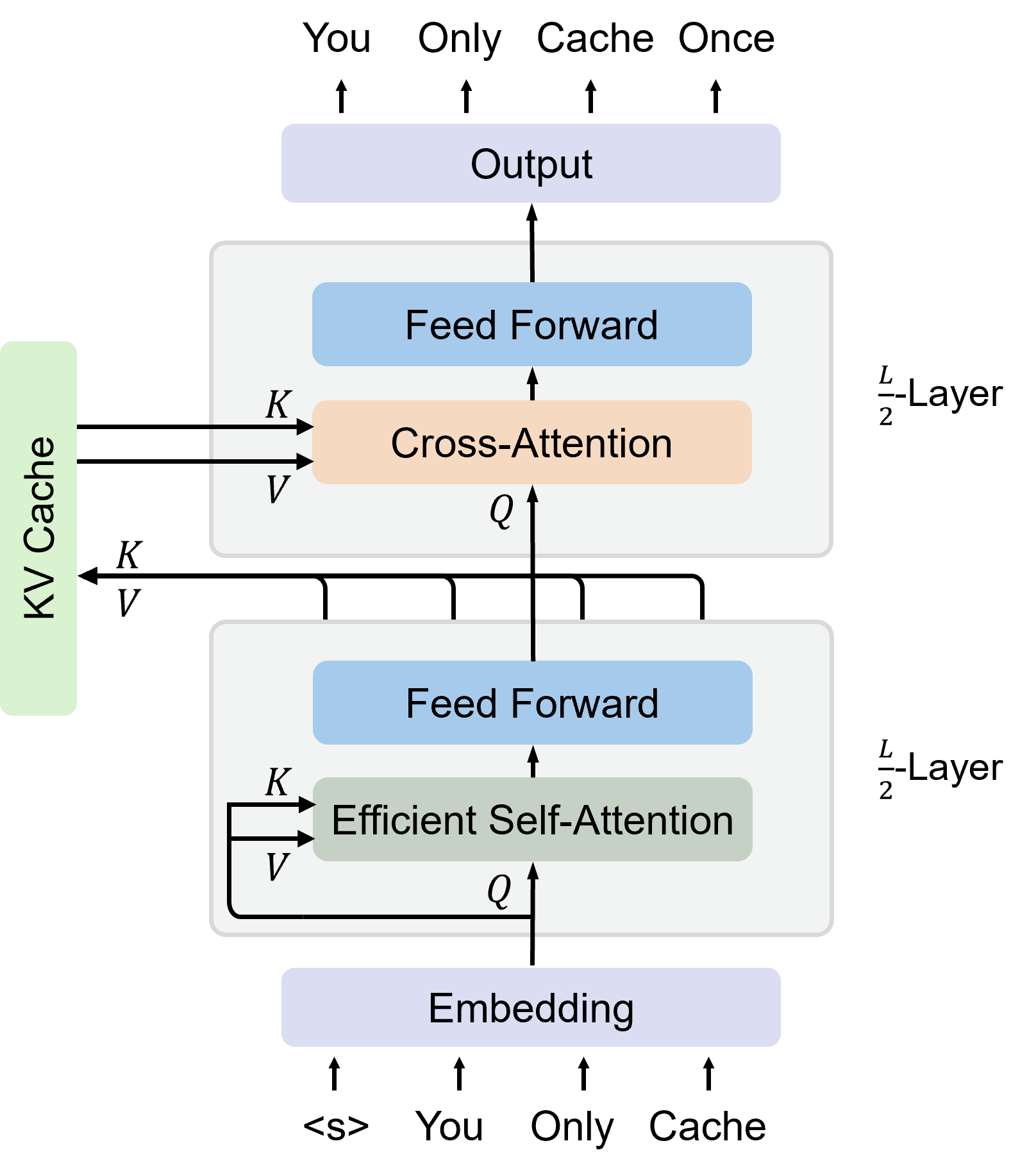
核心思路:YOCO的核心思路是将Transformer的解码器部分拆分为两个模块:一个自解码器(self-decoder)和一个交叉解码器(cross-decoder)。自解码器负责编码整个上下文的KV缓存,而交叉解码器则通过交叉注意力机制重用这些缓存。这样,KV缓存只需要计算和存储一次,从而显著降低了内存占用。
技术框架:YOCO架构包含两个主要模块:自解码器和交叉解码器。自解码器接收输入序列,并生成全局KV缓存。交叉解码器接收自解码器的输出和全局KV缓存,通过交叉注意力机制生成最终的输出。整体流程类似于Decoder-only Transformer,但KV缓存的计算和存储被解耦。预填充阶段可以提前退出,因为交叉解码器只需要访问全局KV缓存,而不需要依赖后续的token。
关键创新:YOCO最重要的创新在于其decoder-decoder架构,它允许KV缓存只被计算和存储一次,从而显著降低了内存需求。此外,YOCO的计算流程使得预填充阶段可以提前退出,从而加速了推理过程。这种架构在保持全局注意力能力的同时,提高了效率。
关键设计:YOCO的关键设计包括自解码器和交叉解码器的层数比例、注意力头的数量、以及激活函数等。论文中提到,YOCO可以扩展到1M上下文长度,这表明其架构具有良好的可扩展性。此外,YOCO的损失函数与标准的语言模型训练相同,没有引入额外的正则化项或目标函数。
🖼️ 关键图片
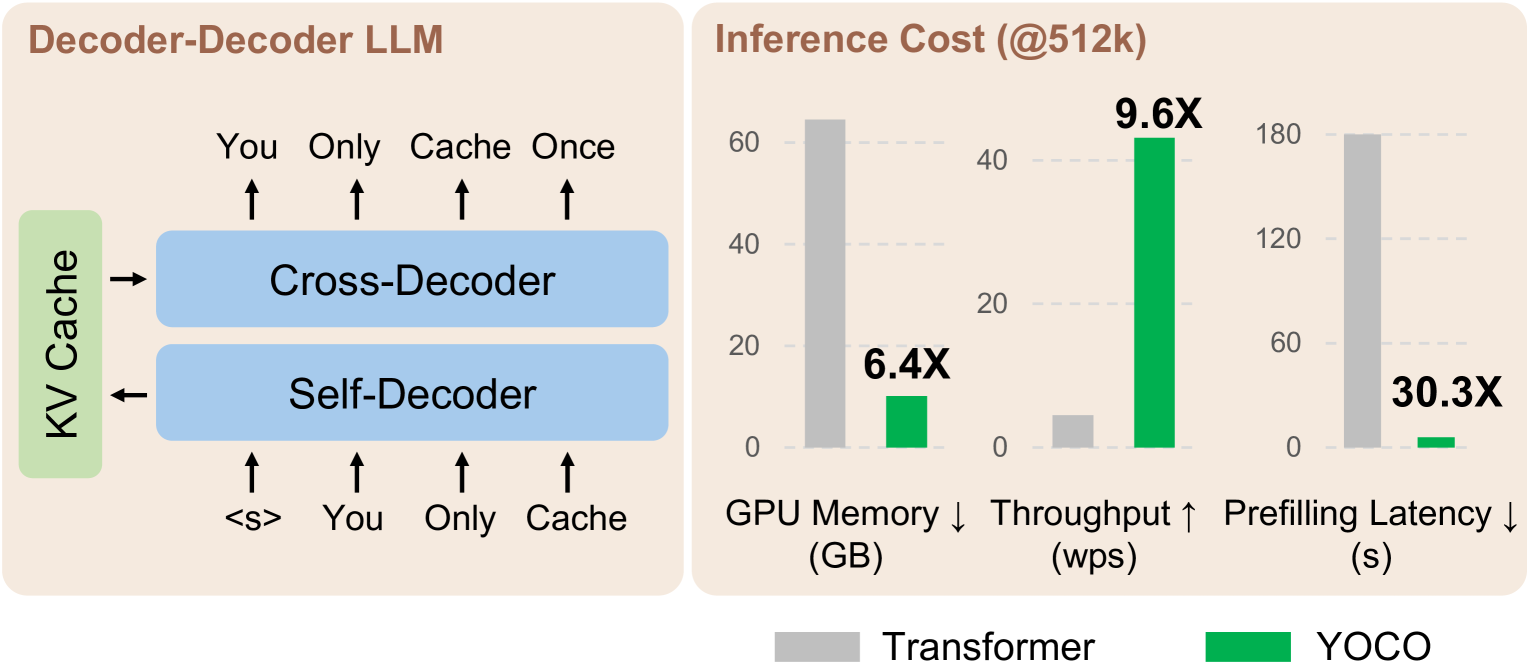

📊 实验亮点
YOCO在各种设置下都取得了与Transformer相当或更好的性能。在1M上下文长度的needle检索任务中,YOCO实现了接近完美的准确率。性能分析表明,YOCO在推理内存、预填充延迟和吞吐量方面都提高了几个数量级。例如,在长上下文场景下,YOCO的预填充速度比Transformer快很多,这使得YOCO更适合实时应用。
🎯 应用场景
YOCO架构适用于需要处理长序列的各种自然语言处理任务,例如机器翻译、文本摘要、对话生成和代码生成。其降低内存占用和加速推理的特性,使其特别适合部署在资源受限的设备上,例如移动设备和边缘服务器。此外,YOCO在长上下文建模方面的优势,使其能够更好地处理需要理解全局信息的任务。
📄 摘要(原文)
We introduce a decoder-decoder architecture, YOCO, for large language models, which only caches key-value pairs once. It consists of two components, i.e., a cross-decoder stacked upon a self-decoder. The self-decoder efficiently encodes global key-value (KV) caches that are reused by the cross-decoder via cross-attention. The overall model behaves like a decoder-only Transformer, although YOCO only caches once. The design substantially reduces GPU memory demands, yet retains global attention capability. Additionally, the computation flow enables prefilling to early exit without changing the final output, thereby significantly speeding up the prefill stage. Experimental results demonstrate that YOCO achieves favorable performance compared to Transformer in various settings of scaling up model size and number of training tokens. We also extend YOCO to 1M context length with near-perfect needle retrieval accuracy. The profiling results show that YOCO improves inference memory, prefill latency, and throughput by orders of magnitude across context lengths and model sizes. Code is available at https://aka.ms/YOCO.