MIDGARD: Self-Consistency Using Minimum Description Length for Structured Commonsense Reasoning
作者: Inderjeet Nair, Lu Wang
分类: cs.CL, cs.AI
发布日期: 2024-05-08 (更新: 2024-06-02)
备注: Accepted at ACL 2024(main)
💡 一句话要点
提出MIDGARD,利用最小描述长度进行自洽性推理,解决结构化常识推理中的误差传播问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 结构化推理 常识推理 自洽性 最小描述长度 推理图
📋 核心要点
- 现有方法在结构化推理中,由于自回归和单次解码,存在误差传播且缺乏纠错能力。
- MIDGARD利用最小描述长度(MDL)来聚合多个推理图样本,识别一致属性并排除错误信息。
- 实验表明,MIDGARD在论证结构提取、解释图生成等多个结构化推理任务中优于现有方法。
📝 摘要(中文)
本文研究了使用大型语言模型(LLMs)从自然语言输入生成推理图,从而进行结构化推理的任务。先前的方法探索了各种提示方案,但由于自回归特性和基于单次解码,它们存在误差传播的问题,缺乏纠错能力。此外,仅依赖单个样本可能导致真实节点和边的遗漏。为了解决这个问题,我们从自洽性(SC)中获得灵感,即采样一组不同的推理链,并将多数投票作为最终答案。为了应对在生成的图上应用SC的巨大挑战,我们提出了MIDGARD(基于最小描述长度引导的有向无环图推理聚合),它利用基于最小描述长度(MDL)的公式来识别LLM生成的不同图样本之间的一致属性。该公式有助于拒绝仅出现在少数样本中的属性(这些属性很可能是错误的),同时能够在不影响精度的情况下包含缺失的元素。我们的方法在各种结构化推理任务中表现出优于对比方法的性能,包括论证结构提取、解释图生成、推断日常任务中动作之间的依赖关系以及从自然文本生成语义图。
🔬 方法详解
问题定义:论文旨在解决结构化常识推理中,利用大型语言模型生成推理图时出现的误差传播和信息遗漏问题。现有方法依赖于单次解码,容易受到早期错误的影响,并且无法有效利用多个推理路径的信息。这导致生成的推理图质量不高,影响下游任务的性能。
核心思路:论文的核心思路是借鉴自洽性(Self-Consistency)的思想,通过生成多个推理图样本,并利用最小描述长度(MDL)原则来聚合这些样本。MDL原则倾向于选择能够以最短编码长度描述数据的模型,从而在多个推理图中找到最一致和可靠的结构。
技术框架:MIDGARD的整体框架包括以下几个主要步骤:1) 使用大型语言模型(LLM)对给定的自然语言输入进行多次采样,生成多个候选的推理图;2) 对每个推理图进行编码,计算其描述长度;3) 利用MDL原则,选择能够以最短描述长度描述所有推理图的结构,即选择在多个图中出现频率较高且一致的节点和边;4) 将选择出的节点和边组合成最终的推理图。
关键创新:MIDGARD的关键创新在于将最小描述长度(MDL)原则应用于推理图的聚合。与简单的多数投票相比,MDL能够更有效地识别和排除噪声信息,同时保留重要的结构信息。此外,MIDGARD能够自动学习不同推理图之间的依赖关系,从而更好地利用多个推理路径的信息。
关键设计:MIDGARD的关键设计包括:1) 推理图的编码方式,需要能够有效地表示图的结构信息,例如可以使用邻接矩阵或图嵌入;2) 描述长度的计算方式,需要考虑节点和边的复杂度和出现频率;3) MDL原则的具体实现方式,例如可以使用贪心算法或优化算法来选择最优的推理图结构。论文中可能还涉及一些超参数的设置,例如采样次数、描述长度的权重等。
🖼️ 关键图片


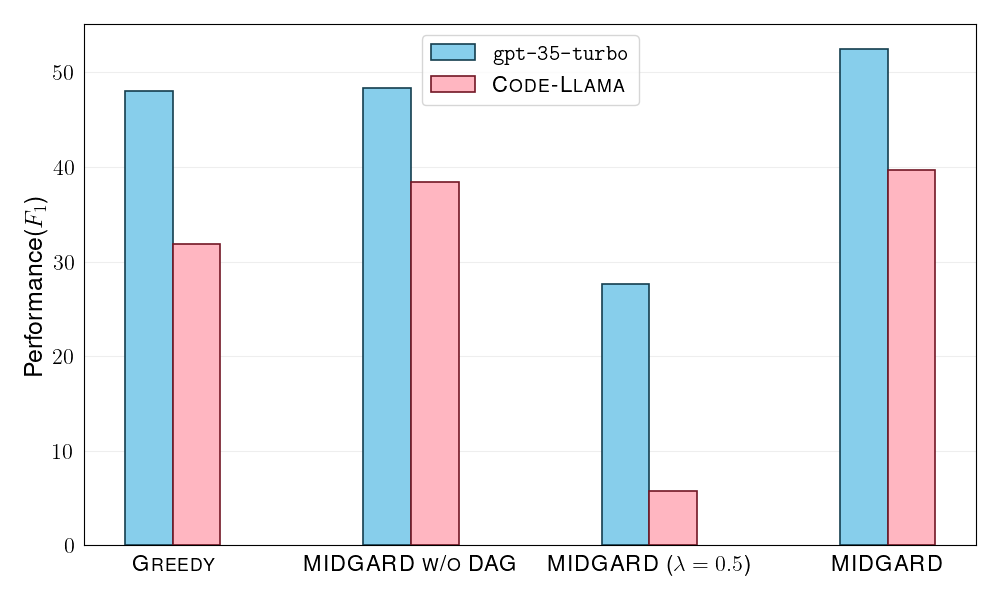
📊 实验亮点
MIDGARD在多个结构化推理任务上取得了显著的性能提升。例如,在论证结构提取任务中,MIDGARD的性能优于现有方法,在解释图生成、推断日常任务中动作之间的依赖关系以及从自然文本生成语义图等任务中也表现出优越性。具体提升幅度未知,但摘要中明确指出“superior performance than comparisons”。
🎯 应用场景
MIDGARD可应用于多种需要结构化常识推理的场景,例如:智能问答、知识图谱构建、文本摘要、对话系统等。通过提升推理图的质量,可以提高这些应用在理解和生成复杂逻辑关系方面的能力,从而实现更智能、更可靠的AI系统。未来,该方法有望应用于更广泛的自然语言处理任务中。
📄 摘要(原文)
We study the task of conducting structured reasoning as generating a reasoning graph from natural language input using large language models (LLMs). Previous approaches have explored various prompting schemes, yet they suffer from error propagation due to the autoregressive nature and single-pass-based decoding, which lack error correction capability. Additionally, relying solely on a single sample may result in the omission of true nodes and edges. To counter this, we draw inspiration from self-consistency (SC), which involves sampling a diverse set of reasoning chains and taking the majority vote as the final answer. To tackle the substantial challenge of applying SC on generated graphs, we propose MIDGARD (MInimum Description length Guided Aggregation of Reasoning in Directed acyclic graph) that leverages Minimum Description Length (MDL)-based formulation to identify consistent properties among the different graph samples generated by an LLM. This formulation helps reject properties that appear in only a few samples, which are likely to be erroneous, while enabling the inclusion of missing elements without compromising precision. Our method demonstrates superior performance than comparisons across various structured reasoning tasks, including argument structure extraction, explanation graph generation, inferring dependency relations among actions for everyday tasks, and semantic graph generation from natural texts.