Zero-shot LLM-guided Counterfactual Generation: A Case Study on NLP Model Evaluation
作者: Amrita Bhattacharjee, Raha Moraffah, Joshua Garland, Huan Liu
分类: cs.CL, cs.AI, cs.LG
发布日期: 2024-05-08 (更新: 2024-11-19)
备注: Longer version of short paper accepted at IEEE BigData 2024 (Main Track)
💡 一句话要点
提出基于零样本LLM引导的反事实生成方法,用于NLP模型评估。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 反事实生成 零样本学习 大型语言模型 NLP模型评估 可解释性
📋 核心要点
- 现有反事实生成方法依赖于特定任务的数据集进行微调,成本高昂且难以适应新任务。
- 论文提出利用LLM的指令遵循和文本理解能力,零样本生成高质量反事实示例。
- 实验表明,该方法能有效评估和解释黑盒NLP模型,无需额外训练或微调。
📝 摘要(中文)
随着用于解决自然语言处理(NLP)任务的大型、复杂、黑盒模型的开发和普及,对这些模型进行压力测试并提供一定程度的可解释性或解释能力的需求也日益增加。反事实示例在这方面很有用,但自动生成反事实示例是一个数据和资源密集的过程。此类方法依赖于预训练语言模型等模型,这些模型需要在辅助的、通常是特定于任务的数据集上进行微调,这在实践中可能不可行,特别是对于新任务和数据领域。因此,在这项工作中,我们探索了利用大型语言模型(LLM)进行零样本反事实生成的可能性,以便对NLP模型进行压力测试。我们提出了一个结构化的流程来促进这种生成,并且我们假设,最近的LLM的指令遵循和文本理解能力可以有效地用于以零样本方式生成高质量的反事实,而无需任何训练或微调。通过对各种专有和开源LLM以及NLP中的各种下游任务进行全面的实验,我们探索了LLM作为零样本反事实生成器在评估和解释黑盒NLP模型方面的有效性。
🔬 方法详解
问题定义:现有NLP模型,特别是黑盒模型,缺乏可解释性,难以进行压力测试。反事实生成是一种有效的解释手段,但传统方法需要大量特定任务的数据进行模型微调,成本高,泛化性差。因此,如何低成本、高效地生成反事实示例,以评估和解释NLP模型,是一个亟待解决的问题。
核心思路:论文的核心思路是利用大型语言模型(LLM)强大的零样本学习能力,直接生成反事实示例,而无需在特定任务的数据集上进行微调。LLM具备优秀的文本理解和生成能力,可以通过指令引导,生成与原始输入相似但导致模型预测结果不同的反事实示例。
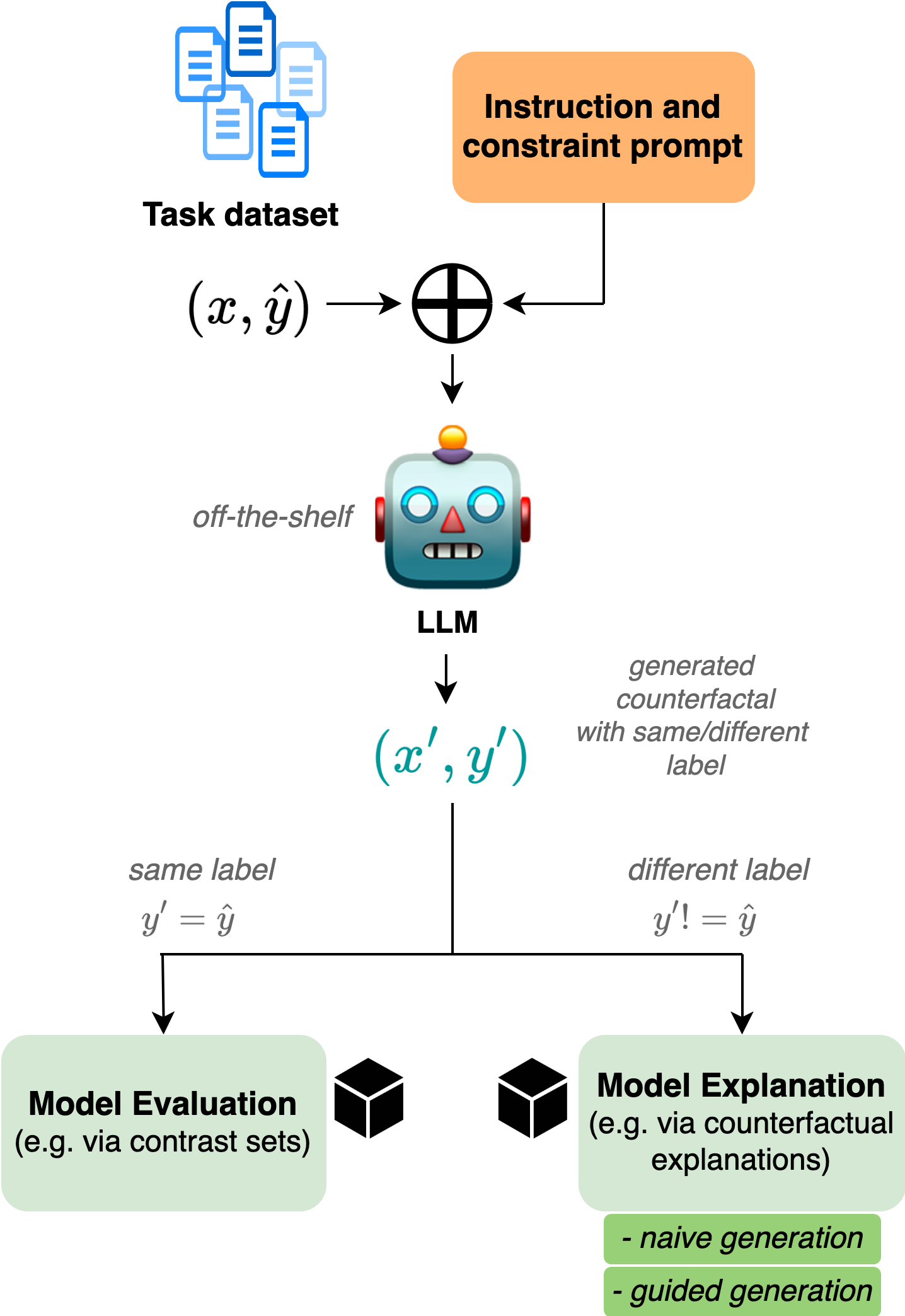
技术框架:论文提出了一个结构化的反事实生成流程,主要包括以下几个阶段:1) 输入原始文本;2) 使用LLM生成反事实候选集,通过特定的prompt工程,引导LLM生成与原始文本语义相似但关键属性不同的文本;3) 使用目标NLP模型对原始文本和反事实候选集进行预测;4) 根据预测结果,筛选出能够改变模型预测结果的反事实示例。
关键创新:该方法最重要的创新点在于利用LLM的零样本能力,避免了传统方法中耗时耗力的模型微调过程。通过精心设计的prompt,可以有效地引导LLM生成高质量的反事实示例,从而实现对NLP模型的有效评估和解释。与现有方法相比,该方法具有更高的效率和更好的泛化能力。
关键设计:论文的关键设计在于prompt的设计。Prompt需要清晰地定义反事实示例的生成目标,例如,改变文本的情感极性、实体类型等。此外,还需要设计合适的筛选策略,从LLM生成的多个候选示例中选择最佳的反事实示例。具体的参数设置和网络结构取决于所使用的LLM和目标NLP模型。
🖼️ 关键图片

📊 实验亮点
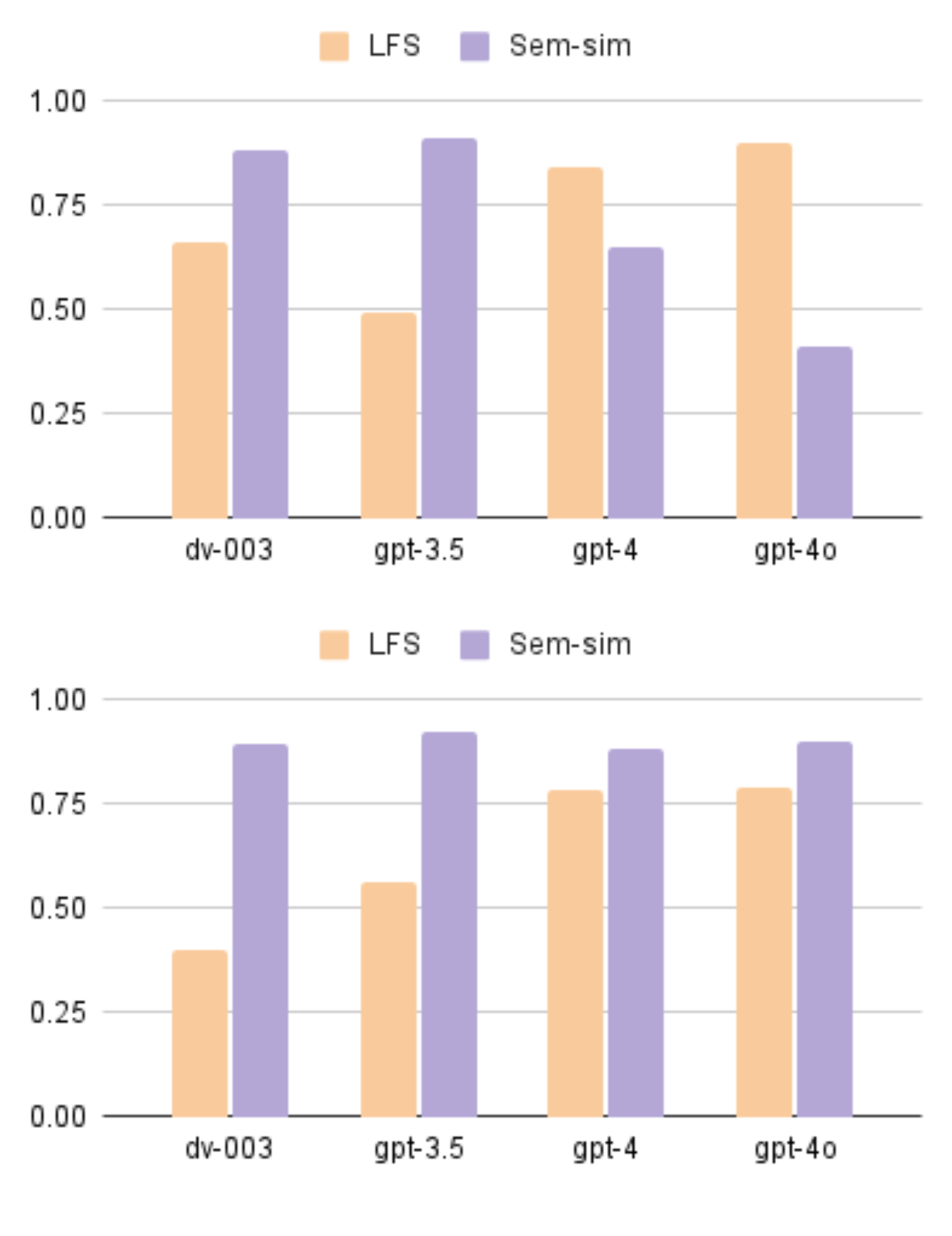
论文通过在多个NLP任务上进行实验,验证了该方法的有效性。实验结果表明,使用LLM生成的反事实示例能够有效地改变目标NLP模型的预测结果,并且生成的反事实示例具有较高的质量和可信度。具体的性能数据和对比基线在论文中有详细描述,但此处未知具体数值。
🎯 应用场景
该研究成果可广泛应用于NLP模型的评估、调试和可解释性分析。例如,可以利用该方法发现模型在特定场景下的弱点,提高模型的鲁棒性和可靠性。此外,该方法还可以用于生成对抗样本,提高模型的防御能力。该研究为开发更安全、更可靠的NLP系统提供了新的思路。
📄 摘要(原文)
With the development and proliferation of large, complex, black-box models for solving many natural language processing (NLP) tasks, there is also an increasing necessity of methods to stress-test these models and provide some degree of interpretability or explainability. While counterfactual examples are useful in this regard, automated generation of counterfactuals is a data and resource intensive process. such methods depend on models such as pre-trained language models that are then fine-tuned on auxiliary, often task-specific datasets, that may be infeasible to build in practice, especially for new tasks and data domains. Therefore, in this work we explore the possibility of leveraging large language models (LLMs) for zero-shot counterfactual generation in order to stress-test NLP models. We propose a structured pipeline to facilitate this generation, and we hypothesize that the instruction-following and textual understanding capabilities of recent LLMs can be effectively leveraged for generating high quality counterfactuals in a zero-shot manner, without requiring any training or fine-tuning. Through comprehensive experiments on a variety of propreitary and open-source LLMs, along with various downstream tasks in NLP, we explore the efficacy of LLMs as zero-shot counterfactual generators in evaluating and explaining black-box NLP models.