Who Wrote This? The Key to Zero-Shot LLM-Generated Text Detection Is GECScore
作者: Junchao Wu, Runzhe Zhan, Derek F. Wong, Shu Yang, Xuebo Liu, Lidia S. Chao, Min Zhang
分类: cs.CL
发布日期: 2024-05-07 (更新: 2025-03-01)
备注: COLING 2025
🔗 代码/项目: GITHUB
💡 一句话要点
提出基于GECScore的零样本LLM生成文本检测方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM文本检测 零样本学习 语法错误纠正 GECScore 黑盒方法
📋 核心要点
- 现有LLM生成文本检测器依赖大量训练数据,零样本检测器则受限于源模型的可访问性。
- 论文提出基于GECScore的黑盒零样本检测方法,利用人工文本通常包含更多语法错误的特性。
- 实验表明,该方法在多个数据集上优于现有零样本和监督方法,并具有良好的泛化能力。
📝 摘要(中文)
现有的大语言模型(LLM)生成文本检测器的有效性很大程度上依赖于大规模训练数据的可用性。然而,无需训练数据的白盒零样本检测器受到LLM生成文本的源模型可访问性的限制。本文提出了一种简单而有效的黑盒零样本检测方法,该方法基于这样的观察:从LLM的角度来看,人工撰写的文本通常比LLM生成的文本包含更多的语法错误。该方法涉及计算给定文本的语法错误纠正分数(GECScore),以区分人工撰写和LLM生成的文本。实验结果表明,我们的方法优于当前最先进的(SOTA)零样本和监督方法,在XSum和Writing Prompts数据集上实现了98.62%的平均AUROC。此外,我们的方法在实际应用中表现出很强的可靠性,具有强大的泛化能力和对释义攻击的抵抗力。数据和代码可在https://github.com/NLP2CT/GECScore 获取。
🔬 方法详解
问题定义:论文旨在解决无需训练数据或访问LLM源模型的情况下,如何有效检测LLM生成的文本的问题。现有方法要么需要大量训练数据,要么依赖于对生成模型的内部机制的了解,这在实际应用中具有很大的局限性。因此,如何设计一种通用的、黑盒的零样本检测方法是一个挑战。
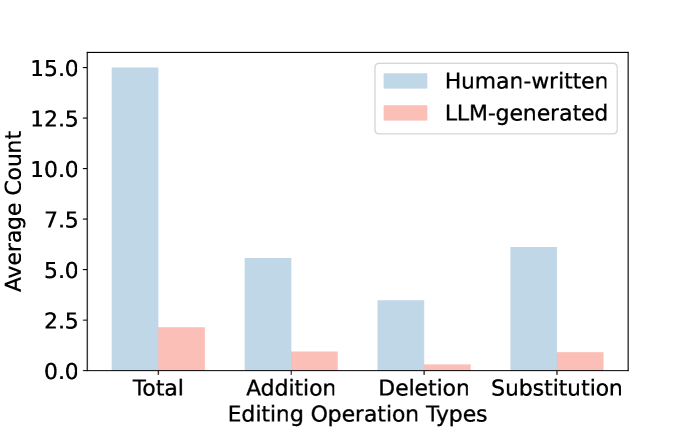
核心思路:论文的核心思路是基于一个观察:相对于LLM生成的文本,人工撰写的文本通常包含更多的语法错误。这是因为LLM在生成文本时,会尽量避免语法错误,而人类在写作时则可能出现各种各样的错误。因此,可以通过评估文本的语法错误程度来区分人工撰写和LLM生成的文本。
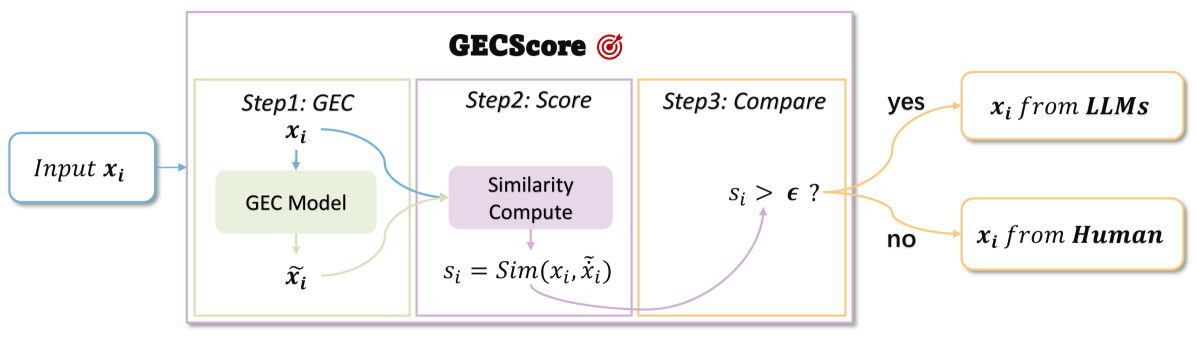
技术框架:该方法的核心是计算文本的语法错误纠正分数(GECScore)。具体流程如下:1. 输入一段文本。2. 使用一个语法纠错模型对文本进行纠错。3. 计算纠错前后文本的相似度得分,作为GECScore。相似度得分越高,说明文本的语法错误越少,越有可能是LLM生成的文本。反之,相似度得分越低,说明文本的语法错误越多,越有可能是人工撰写的文本。
关键创新:该方法最重要的技术创新点在于,它利用了人工文本和LLM生成文本在语法错误上的差异,提出了一种简单有效的黑盒零样本检测方法。与现有方法相比,该方法无需训练数据,也不需要访问LLM的源模型,具有更强的通用性和实用性。
关键设计:GECScore的计算依赖于一个语法纠错模型和一个相似度计算函数。论文中使用了基于Transformer的语法纠错模型,并使用BERTScore作为相似度计算函数。BERTScore能够更好地捕捉文本的语义信息,从而更准确地评估文本的语法错误程度。此外,论文还对GECScore进行了一些归一化处理,以提高其鲁棒性。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法在XSum和Writing Prompts数据集上取得了显著的成果,平均AUROC达到98.62%,超过了当前最先进的零样本和监督方法。此外,该方法还表现出强大的泛化能力和对释义攻击的抵抗力,证明了其在实际应用中的可靠性。
🎯 应用场景
该研究成果可应用于检测虚假新闻、学术欺诈、网络水军等领域。通过识别LLM生成的文本,可以有效防止恶意信息传播,维护网络安全和信息真实性。未来,该方法可以集成到各种内容审核平台和工具中,提高自动化内容审核的效率和准确性。
📄 摘要(原文)
The efficacy of detectors for texts generated by large language models (LLMs) substantially depends on the availability of large-scale training data. However, white-box zero-shot detectors, which require no such data, are limited by the accessibility of the source model of the LLM-generated text. In this paper, we propose a simple yet effective black-box zero-shot detection approach based on the observation that, from the perspective of LLMs, human-written texts typically contain more grammatical errors than LLM-generated texts. This approach involves calculating the Grammar Error Correction Score (GECScore) for the given text to differentiate between human-written and LLM-generated text. Experimental results show that our method outperforms current state-of-the-art (SOTA) zero-shot and supervised methods, achieving an average AUROC of 98.62% across XSum and Writing Prompts dataset. Additionally, our approach demonstrates strong reliability in the wild, exhibiting robust generalization and resistance to paraphrasing attacks. Data and code are available at: https://github.com/NLP2CT/GECScore.