Iterative Experience Refinement of Software-Developing Agents
作者: Chen Qian, Jiahao Li, Yufan Dang, Wei Liu, YiFei Wang, Zihao Xie, Weize Chen, Cheng Yang, Yingli Zhang, Zhiyuan Liu, Maosong Sun
分类: cs.CL, cs.AI, cs.MA, cs.SE
发布日期: 2024-05-07
备注: Work in progress
💡 一句话要点
提出迭代经验精炼框架,提升软件开发Agent在任务执行中的适应性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 软件开发Agent 大型语言模型 经验精炼 迭代学习 自主Agent
📋 核心要点
- 现有LLM Agent依赖静态经验,无法在任务执行中动态调整,限制了其适应性和性能。
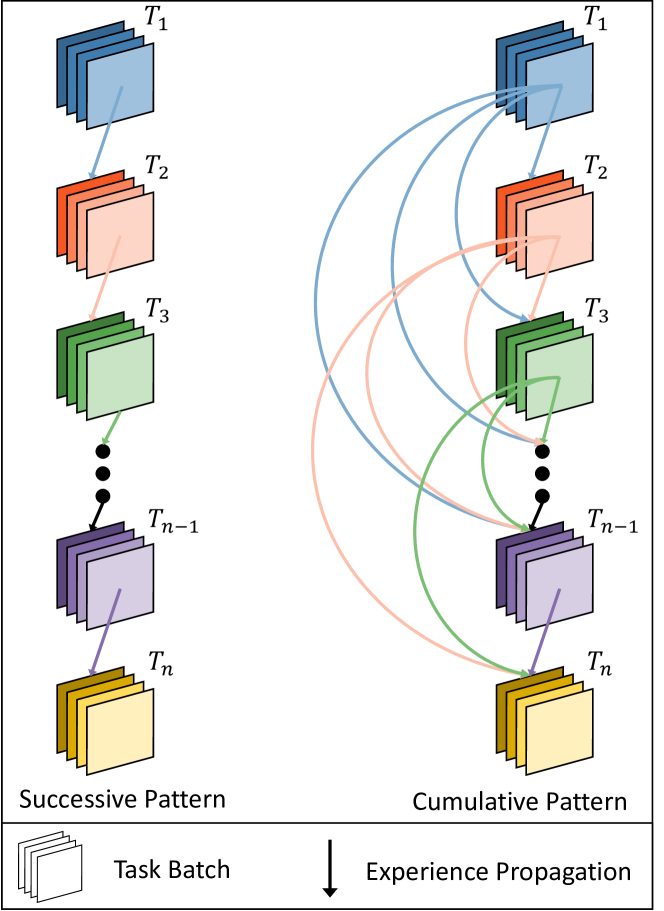
- 提出迭代经验精炼框架,通过连续和累积两种模式,使Agent能在任务中不断学习和优化经验。
- 实验表明,该框架能有效提升Agent性能,经验消除机制还能在减少经验数量的同时保持甚至提升性能。
📝 摘要(中文)
本文提出了一种迭代经验精炼框架,旨在提升基于大型语言模型(LLM)的自主Agent在软件开发等场景中的自主性。现有方法依赖于静态的、启发式获取的经验集合,缺乏迭代精炼,限制了Agent的适应性。该框架使LLM Agent能够在任务执行过程中迭代地精炼经验。我们提出了两种基本模式:连续模式,基于任务批次中最接近的经验进行精炼;累积模式,跨所有先前的任务批次获取经验。结合启发式经验消除方法,该方法优先考虑高质量和常用的经验,有效地管理经验空间并提高效率。大量实验表明,连续模式可能产生更好的结果,而累积模式提供更稳定的性能。此外,经验消除有助于仅使用高质量子集的11.54%来实现更好的性能。
🔬 方法详解
问题定义:现有基于LLM的软件开发Agent通常依赖于预先设定的或启发式收集的经验,这些经验在Agent执行任务的过程中是静态不变的。这种静态经验库无法根据Agent在实际任务中的表现进行调整和优化,导致Agent在面对新的或变化的场景时,难以有效地利用过去的经验,从而影响其性能和效率。因此,如何使Agent能够动态地学习和精炼经验,以适应不同的任务环境,是一个亟待解决的问题。
核心思路:本文的核心思路是引入迭代经验精炼机制,使Agent能够在任务执行过程中不断地学习和优化其经验。具体来说,Agent在完成一个任务批次后,会根据其表现和任务的特点,对已有的经验进行评估和筛选,并生成新的经验。这些新的经验会被添加到经验库中,并在后续的任务中使用。通过这种迭代的方式,Agent可以不断地提升其经验的质量和相关性,从而提高其在软件开发任务中的性能。
技术框架:该框架包含以下几个主要模块:1) 任务执行模块:Agent执行软件开发任务,并记录任务执行过程中的相关信息,例如代码片段、错误信息等。2) 经验评估模块:Agent根据任务执行的结果,对已有的经验进行评估,判断其质量和相关性。3) 经验精炼模块:Agent根据经验评估的结果,对经验进行精炼,例如删除冗余的经验、合并相似的经验等。4) 经验生成模块:Agent根据任务执行过程中的信息,生成新的经验,并添加到经验库中。该框架支持两种经验精炼模式:连续模式和累积模式。连续模式基于当前任务批次中最相关的经验进行精炼,而累积模式则考虑所有历史任务批次的经验。
关键创新:该论文的关键创新在于提出了迭代经验精炼框架,使Agent能够在任务执行过程中动态地学习和优化经验。与传统的静态经验方法相比,该框架能够更好地适应不同的任务环境,并提高Agent的性能和效率。此外,该论文还提出了两种不同的经验精炼模式(连续模式和累积模式),并研究了它们在不同场景下的表现。
关键设计:该框架的关键设计包括:1) 经验评估指标:用于评估经验的质量和相关性,例如任务完成率、错误率等。2) 经验精炼策略:用于删除冗余的经验、合并相似的经验等。3) 经验生成策略:用于根据任务执行过程中的信息,生成新的经验。4) 经验消除机制:用于控制经验库的大小,并优先保留高质量和常用的经验。具体来说,经验消除机制会定期对经验库中的经验进行评估,并删除那些质量较低或使用频率较低的经验。
🖼️ 关键图片


📊 实验亮点
实验结果表明,迭代经验精炼框架能够显著提升软件开发Agent的性能。具体来说,连续模式在某些任务上表现更优,而累积模式则提供更稳定的性能。更重要的是,经验消除机制能够在仅保留11.54%的高质量经验子集的情况下,实现更好的性能,这表明该框架能够有效地管理经验空间,并提高Agent的效率。
🎯 应用场景
该研究成果可应用于各种需要自主软件开发的场景,例如自动化代码生成、缺陷修复、软件测试等。通过不断学习和优化经验,Agent可以更好地适应不同的开发环境和任务需求,提高软件开发的效率和质量。此外,该框架还可以扩展到其他领域,例如机器人控制、自然语言处理等,为实现更智能、更自主的Agent提供技术支持。
📄 摘要(原文)
Autonomous agents powered by large language models (LLMs) show significant potential for achieving high autonomy in various scenarios such as software development. Recent research has shown that LLM agents can leverage past experiences to reduce errors and enhance efficiency. However, the static experience paradigm, reliant on a fixed collection of past experiences acquired heuristically, lacks iterative refinement and thus hampers agents' adaptability. In this paper, we introduce the Iterative Experience Refinement framework, enabling LLM agents to refine experiences iteratively during task execution. We propose two fundamental patterns: the successive pattern, refining based on nearest experiences within a task batch, and the cumulative pattern, acquiring experiences across all previous task batches. Augmented with our heuristic experience elimination, the method prioritizes high-quality and frequently-used experiences, effectively managing the experience space and enhancing efficiency. Extensive experiments show that while the successive pattern may yield superior results, the cumulative pattern provides more stable performance. Moreover, experience elimination facilitates achieving better performance using just 11.54% of a high-quality subset.