A Causal Explainable Guardrails for Large Language Models
作者: Zhixuan Chu, Yan Wang, Longfei Li, Zhibo Wang, Zhan Qin, Kui Ren
分类: cs.CL
发布日期: 2024-05-07 (更新: 2024-09-04)
备注: 16 pages
💡 一句话要点
提出LLMGuardrail,通过因果分析消除偏差,提升大语言模型的可控性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 因果分析 偏差消除 对抗学习 可解释性 模型引导 安全AI
📋 核心要点
- 现有大语言模型引导方法依赖无偏表示假设,但预训练引入的语义偏差会影响引导效果。
- LLMGuardrail结合因果分析与对抗学习,消除偏差影响,提取无偏引导表示。
- 实验证明LLMGuardrail能有效引导LLM朝向期望属性,同时减轻偏差,提升模型安全性。
📝 摘要(中文)
大型语言模型(LLMs)在自然语言任务中表现出令人印象深刻的性能,但其输出可能表现出不良属性或偏差。现有的引导LLMs朝向期望属性的方法通常假设无偏表示,并且仅依赖于引导提示。然而,从预训练中学习到的表示可能会引入影响引导过程的语义偏差,从而导致次优结果。我们提出了LLMGuardrail,这是一个新颖的框架,它结合了因果分析和对抗学习,以获得LLMs中无偏的引导表示。LLMGuardrail系统地识别并阻止偏差的混淆效应,从而能够提取无偏的引导表示。此外,它还包括一个可解释的组件,该组件提供了对生成输出与期望方向之间对齐的见解。实验表明,LLMGuardrail在引导LLMs朝向期望属性的同时减轻偏差方面是有效的。我们的工作有助于开发安全可靠的LLMs,使其与期望的属性对齐。
🔬 方法详解
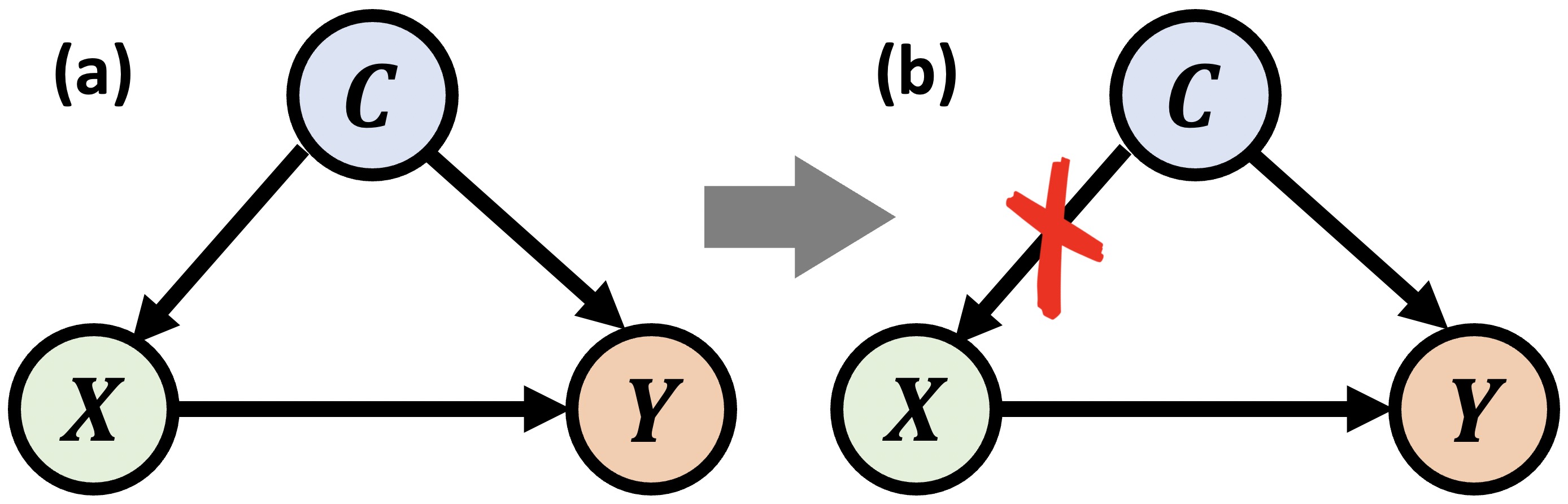
问题定义:现有的大语言模型引导方法在控制模型输出属性时,往往假设模型内部的表示是无偏的。然而,预训练数据中固有的偏差会导致模型学习到的表示带有语义偏差,这些偏差会干扰引导过程,使得模型难以准确地按照期望的属性生成内容。因此,如何消除这些偏差,获得无偏的引导表示,是本文要解决的关键问题。
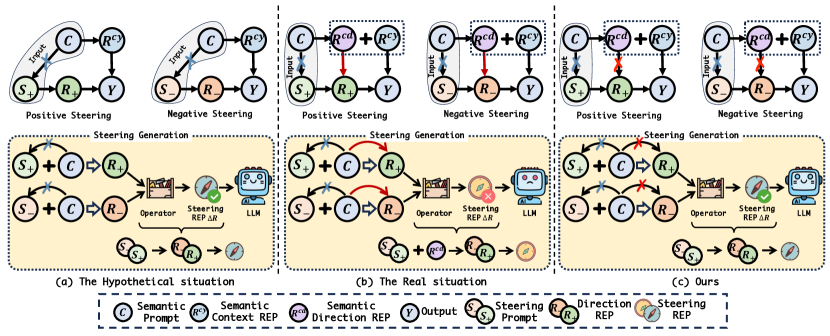
核心思路:LLMGuardrail的核心思路是通过因果分析识别并消除偏差的混淆效应。具体来说,它将偏差视为影响模型输出的混淆因素,通过干预模型内部的表示,阻断偏差的影响路径,从而获得无偏的表示。此外,LLMGuardrail还利用对抗学习来增强模型的鲁棒性,使其能够更好地抵抗偏差的干扰。
技术框架:LLMGuardrail框架主要包含三个模块:1) 偏差识别模块:用于识别模型内部表示中存在的偏差;2) 偏差消除模块:利用因果干预技术,阻断偏差对模型输出的影响;3) 可解释性模块:提供对模型输出与期望属性对齐情况的解释,帮助用户理解模型的行为。整个流程是,首先通过偏差识别模块找到偏差,然后通过偏差消除模块进行干预,最后通过可解释性模块进行验证。
关键创新:LLMGuardrail最重要的创新点在于它将因果分析引入到大语言模型的引导过程中。与传统的基于提示的引导方法不同,LLMGuardrail能够系统地识别和消除偏差的影响,从而获得更准确、更可靠的引导效果。此外,LLMGuardrail的可解释性模块也为用户提供了对模型行为的深入理解,增强了模型的可信度。
关键设计:在偏差消除模块中,论文可能采用了诸如后门调整(backdoor adjustment)或前门调整(front-door adjustment)等因果干预技术,具体选择取决于偏差的因果结构。对抗学习部分可能使用了对抗训练(adversarial training)来增强模型的鲁棒性,损失函数可能包括一个用于衡量模型输出与期望属性之间距离的项,以及一个用于惩罚偏差的项。可解释性模块可能使用了注意力机制(attention mechanism)或其他解释性方法来分析模型输出的关键因素。
🖼️ 关键图片
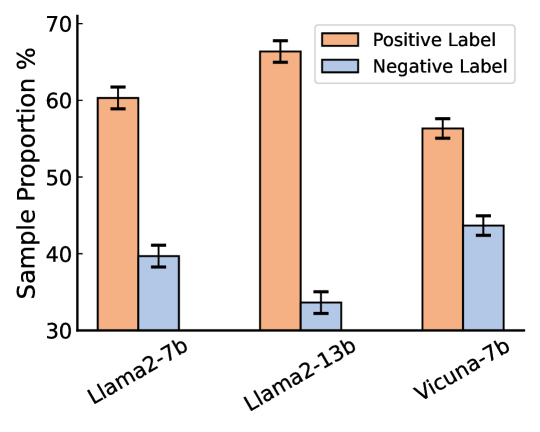
📊 实验亮点
实验结果表明,LLMGuardrail在引导LLM朝向期望属性的同时,能够有效减轻偏差的影响。具体来说,在多个基准测试中,LLMGuardrail相比于现有的引导方法,在属性对齐度和偏差抑制方面均取得了显著提升。例如,在生成新闻报道的任务中,LLMGuardrail能够生成更客观、更公正的内容,避免了性别、种族等方面的歧视。
🎯 应用场景
LLMGuardrail可应用于各种需要控制大语言模型输出属性的场景,例如生成无偏见的新闻报道、创作符合特定风格的文学作品、以及构建安全可靠的对话系统。该研究有助于提升大语言模型在敏感领域的应用价值,并降低其潜在风险,例如生成有害或不当内容。未来,该技术有望进一步推广到其他类型的生成模型中。
📄 摘要(原文)
Large Language Models (LLMs) have shown impressive performance in natural language tasks, but their outputs can exhibit undesirable attributes or biases. Existing methods for steering LLMs toward desired attributes often assume unbiased representations and rely solely on steering prompts. However, the representations learned from pre-training can introduce semantic biases that influence the steering process, leading to suboptimal results. We propose LLMGuardrail, a novel framework that incorporates causal analysis and adversarial learning to obtain unbiased steering representations in LLMs. LLMGuardrail systematically identifies and blocks the confounding effects of biases, enabling the extraction of unbiased steering representations. Additionally, it includes an explainable component that provides insights into the alignment between the generated output and the desired direction. Experiments demonstrate LLMGuardrail's effectiveness in steering LLMs toward desired attributes while mitigating biases. Our work contributes to the development of safe and reliable LLMs that align with desired attributes.