FlashBack:Efficient Retrieval-Augmented Language Modeling for Long Context Inference
作者: Runheng Liu, Xingchen Xiao, Heyan Huang, Zewen Chi, Zhijing Wu
分类: cs.CL
发布日期: 2024-05-07 (更新: 2025-06-13)
备注: ACL 2025 Findings, 14 pages
💡 一句话要点
FlashBack:一种高效的检索增强语言模型,用于长文本推理,提升推理效率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 检索增强语言模型 长文本推理 推理效率 Key-Value缓存 低秩自适应
📋 核心要点
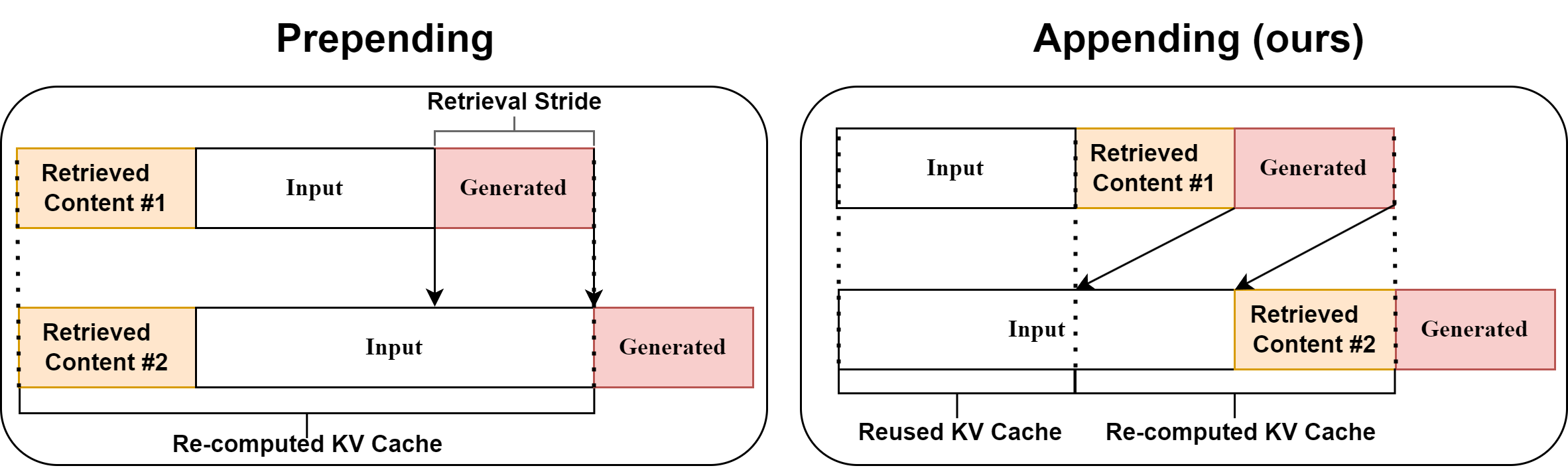
- 现有检索增强语言模型(RALM)通过前置检索内容,导致LLM推理效率降低,无法有效利用KV缓存。
- FlashBack通过将检索文档附加到上下文末尾,并引入标记Token来区分附加内容,从而有效利用KV缓存。
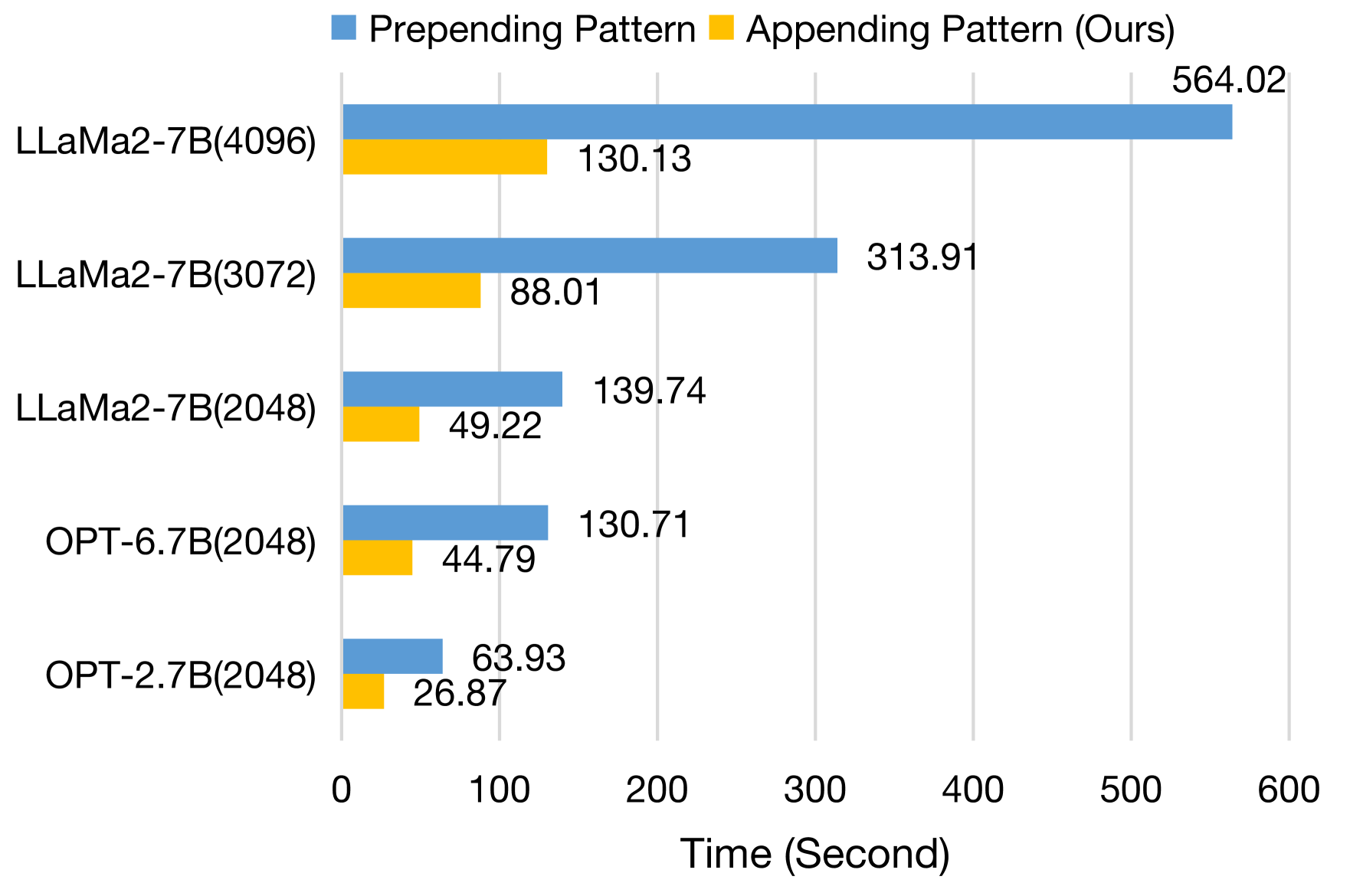
- 实验表明,FlashBack在保持生成质量的同时,推理速度比前置方法快4倍,显著降低了推理成本。
📝 摘要(中文)
本文提出FlashBack,一种模块化的检索增强语言模型(RALM),旨在提高RALM的推理效率,同时通过低秩自适应微调(LoRA)保持良好的性能。FlashBack将检索到的文档附加到上下文的末尾,从而有效地利用Key-Value(KV)缓存,而不是像传统方法那样前置。此外,引入了标记Token作为特殊的提示Token,用于在微调期间标记附加上下文的边界。实验结果表明,FlashBack在困惑度方面保持了良好的生成质量。在运行时测试中,FlashBack的推理速度比7B LLM (Llama 2)上的前置方法快达4倍。通过绕过不必要的重复计算,FlashBack显著提高了推理速度,从而大幅降低了推理成本。
🔬 方法详解
问题定义:现有RALM方法,如直接将检索到的文档前置于输入文本,导致LLM在推理时无法有效利用Key-Value (KV) 缓存。每次推理都需要重新计算整个上下文,造成计算冗余,推理速度慢,成本高。
核心思路:FlashBack的核心思路是将检索到的文档附加到上下文的末尾,而不是前置。这样,LLM可以复用之前计算的KV缓存,仅需计算附加部分的KV值,从而避免了对整个上下文的重复计算,显著提升推理效率。
技术框架:FlashBack是一个模块化的RALM框架,主要包含以下几个阶段:1) 检索:从外部知识库中检索相关文档;2) 附加:将检索到的文档附加到原始上下文的末尾;3) 标记:使用特殊的“标记Token”来标识附加文档的边界,以便LLM区分原始上下文和检索到的内容;4) 推理:LLM基于拼接后的上下文进行推理,并利用KV缓存加速计算。
关键创新:FlashBack的关键创新在于“后置附加”和“标记Token”的设计。后置附加允许LLM复用KV缓存,显著提升推理速度。标记Token则帮助LLM区分原始上下文和检索到的内容,从而保证生成质量。
关键设计:FlashBack使用低秩自适应(LoRA)进行微调,以适应后置附加的上下文结构。标记Token是两个特殊的prompt token,用于标记附加上下文的开始和结束位置。具体实现细节(如损失函数、网络结构等)未在摘要中详细说明,属于未知信息。
🖼️ 关键图片

📊 实验亮点
实验结果表明,FlashBack在保持良好生成质量(通过困惑度评估)的同时,显著提高了推理速度。在7B LLM (Llama 2)上的运行时测试中,FlashBack的推理速度比前置方法快达4倍。这一显著的性能提升表明FlashBack在实际应用中具有很高的价值。
🎯 应用场景
FlashBack可应用于各种需要长文本推理的场景,例如问答系统、文档摘要、机器翻译等。通过提高推理效率,FlashBack可以降低部署成本,并支持更大规模的应用。未来,FlashBack可以进一步扩展到多模态数据,例如图像和视频,从而支持更复杂的应用场景。
📄 摘要(原文)
Retrieval-Augmented Language Modeling (RALM) by integrating large language models (LLM) with relevant documents from an external corpus is a proven method for enabling the LLM to generate information beyond the scope of its pre-training corpus. Previous work utilizing retrieved content by simply prepending it to the input poses a high runtime issue, which degrades the inference efficiency of the LLMs because they fail to use the Key-Value (KV) cache efficiently. In this paper, we propose FlashBack, a modular RALM designed to improve the inference efficiency of RALM with appending context pattern while maintaining decent performance after fine-tuning by Low-Rank Adaption. FlashBack appends retrieved documents at the end of the context for efficiently utilizing the KV cache instead of prepending them. And we introduce Marking Token as two special prompt tokens for marking the boundary of the appending context during fine-tuning. Our experiments on testing generation quality show that FlashBack can remain decent generation quality in perplexity. And the inference speed of FlashBack is up to $4\times$ faster than the prepending counterpart on a 7B LLM (Llama 2) in the runtime test. Via bypassing unnecessary re-computation, it demonstrates an advancement by achieving significantly faster inference speed, and this heightened efficiency will substantially reduce inferential cost.