Detecting Anti-Semitic Hate Speech using Transformer-based Large Language Models
作者: Dengyi Liu, Minghao Wang, Andrew G. Catlin
分类: cs.CL
发布日期: 2024-05-06
💡 一句话要点
利用Transformer大语言模型检测反犹太主义仇恨言论
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 仇恨言论检测 反犹太主义 Transformer模型 LoRA微调 自然语言处理
📋 核心要点
- 现有仇恨言论检测方法难以应对数据规模庞大和仇恨言论动态变化的挑战。
- 该研究探索使用Transformer模型(BERT、RoBERTa、LLaMA-2等)结合LoRA微调来检测反犹太主义仇恨言论。
- 论文通过实验评估了不同Transformer模型在仇恨言论检测中的效果,并强调了负责任的AI应用。
📝 摘要(中文)
学术研究人员和社交媒体实体在识别仇恨言论方面面临巨大挑战,主要原因是数据规模庞大以及仇恨言论的动态性。鉴于ChatGPT等大型预测模型在直接处理此类敏感问题时存在伦理和实践限制,本研究自2019年以来探索了其他基于Transformer的先进技术和生成式AI技术。具体而言,我们开发了一种新的数据标注技术,并建立了一个针对反犹太主义仇恨言论的概念验证,利用了多种Transformer模型,如BERT、DistillBERT、RoBERTa和LLaMA-2,并辅以LoRA微调方法。本文阐述并评估了这些前沿方法在解决复杂仇恨言论检测问题方面的相对效力,强调需要在敏感环境中负责任地、谨慎地管理AI应用。
🔬 方法详解
问题定义:论文旨在解决在线反犹太主义仇恨言论的自动检测问题。现有方法在处理大规模数据和不断演变的仇恨言论表达方式时存在局限性,并且直接使用大型语言模型(如ChatGPT)进行仇恨言论检测存在伦理和实践风险。
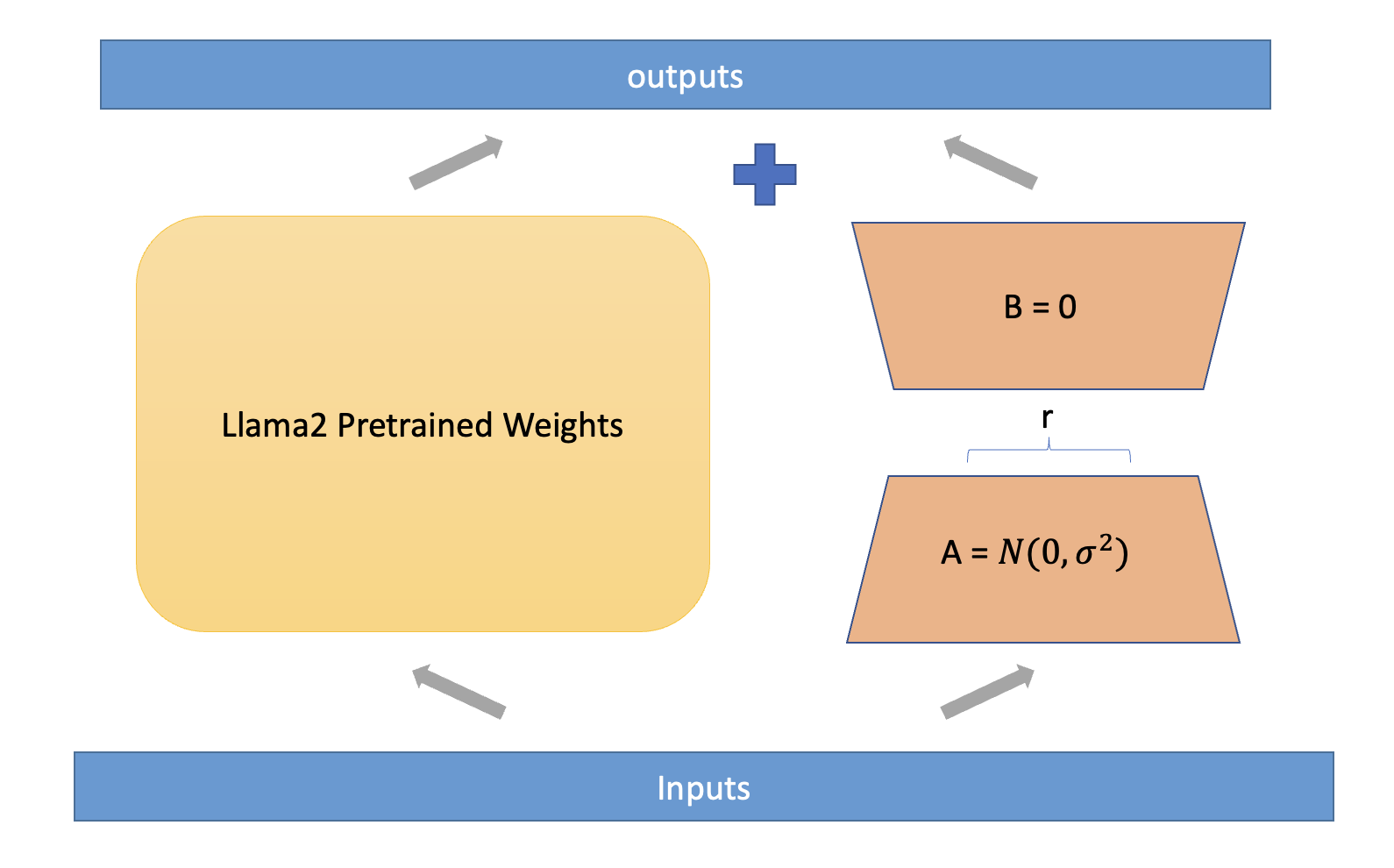
核心思路:论文的核心思路是利用Transformer架构的预训练语言模型,通过微调的方式使其适应反犹太主义仇恨言论的检测任务。选择Transformer模型是因为它们在自然语言处理任务中表现出色,能够捕捉文本中的复杂语义关系。结合LoRA(Low-Rank Adaptation)微调方法,可以在减少计算资源消耗的同时,有效提升模型性能。
技术框架:整体框架包括以下几个主要阶段:1) 数据收集与标注:开发新的数据标注技术,构建用于训练和评估模型的数据集。2) 模型选择与配置:选择一系列Transformer模型,包括BERT、DistillBERT、RoBERTa和LLaMA-2。3) LoRA微调:使用LoRA方法对选定的Transformer模型进行微调,使其适应反犹太主义仇恨言论检测任务。4) 性能评估:在测试集上评估不同模型的性能,并进行比较分析。
关键创新:论文的关键创新在于将LoRA微调方法应用于Transformer模型,以解决反犹太主义仇恨言论检测问题。LoRA通过冻结预训练模型的权重,并引入少量可训练的低秩矩阵,从而大大减少了微调所需的计算资源。此外,论文还提出了一种新的数据标注技术,以提高数据集的质量。
关键设计:论文的关键设计包括:1) 选择合适的预训练Transformer模型作为基础模型。2) 设计有效的数据标注策略,确保数据集的质量和多样性。3) 调整LoRA的参数,例如低秩矩阵的维度,以优化模型性能。4) 使用适当的损失函数(例如交叉熵损失)来训练模型。5) 采用合适的评估指标(例如精确率、召回率、F1值)来衡量模型性能。
🖼️ 关键图片

📊 实验亮点
论文通过实验对比了BERT、DistillBERT、RoBERTa和LLaMA-2等模型在反犹太主义仇恨言论检测任务上的性能。实验结果表明,结合LoRA微调的Transformer模型能够有效检测反犹太主义仇恨言论。具体的性能数据(如精确率、召回率、F1值)和提升幅度需要在论文中查找。
🎯 应用场景
该研究成果可应用于社交媒体平台、在线论坛等,用于自动检测和过滤反犹太主义仇恨言论,从而维护网络空间的健康环境。此外,该方法也可推广到其他类型的仇恨言论检测,例如种族歧视、性别歧视等。未来,该研究可以进一步探索如何利用生成式AI技术来生成对抗样本,从而提高模型的鲁棒性。
📄 摘要(原文)
Academic researchers and social media entities grappling with the identification of hate speech face significant challenges, primarily due to the vast scale of data and the dynamic nature of hate speech. Given the ethical and practical limitations of large predictive models like ChatGPT in directly addressing such sensitive issues, our research has explored alternative advanced transformer-based and generative AI technologies since 2019. Specifically, we developed a new data labeling technique and established a proof of concept targeting anti-Semitic hate speech, utilizing a variety of transformer models such as BERT (arXiv:1810.04805), DistillBERT (arXiv:1910.01108), RoBERTa (arXiv:1907.11692), and LLaMA-2 (arXiv:2307.09288), complemented by the LoRA fine-tuning approach (arXiv:2106.09685). This paper delineates and evaluates the comparative efficacy of these cutting-edge methods in tackling the intricacies of hate speech detection, highlighting the need for responsible and carefully managed AI applications within sensitive contexts.