Anchored Answers: Unravelling Positional Bias in GPT-2's Multiple-Choice Questions
作者: Ruizhe Li, Yanjun Gao
分类: cs.CL, cs.AI, cs.LG
发布日期: 2024-05-06 (更新: 2025-05-30)
备注: ACL 2025 Findings
🔗 代码/项目: GITHUB
💡 一句话要点
针对GPT-2多选题中的位置偏差,提出基于机制可解释性的干预方法。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 GPT-2 多选题 位置偏差 锚定偏差 机制可解释性 模型干预
📋 核心要点
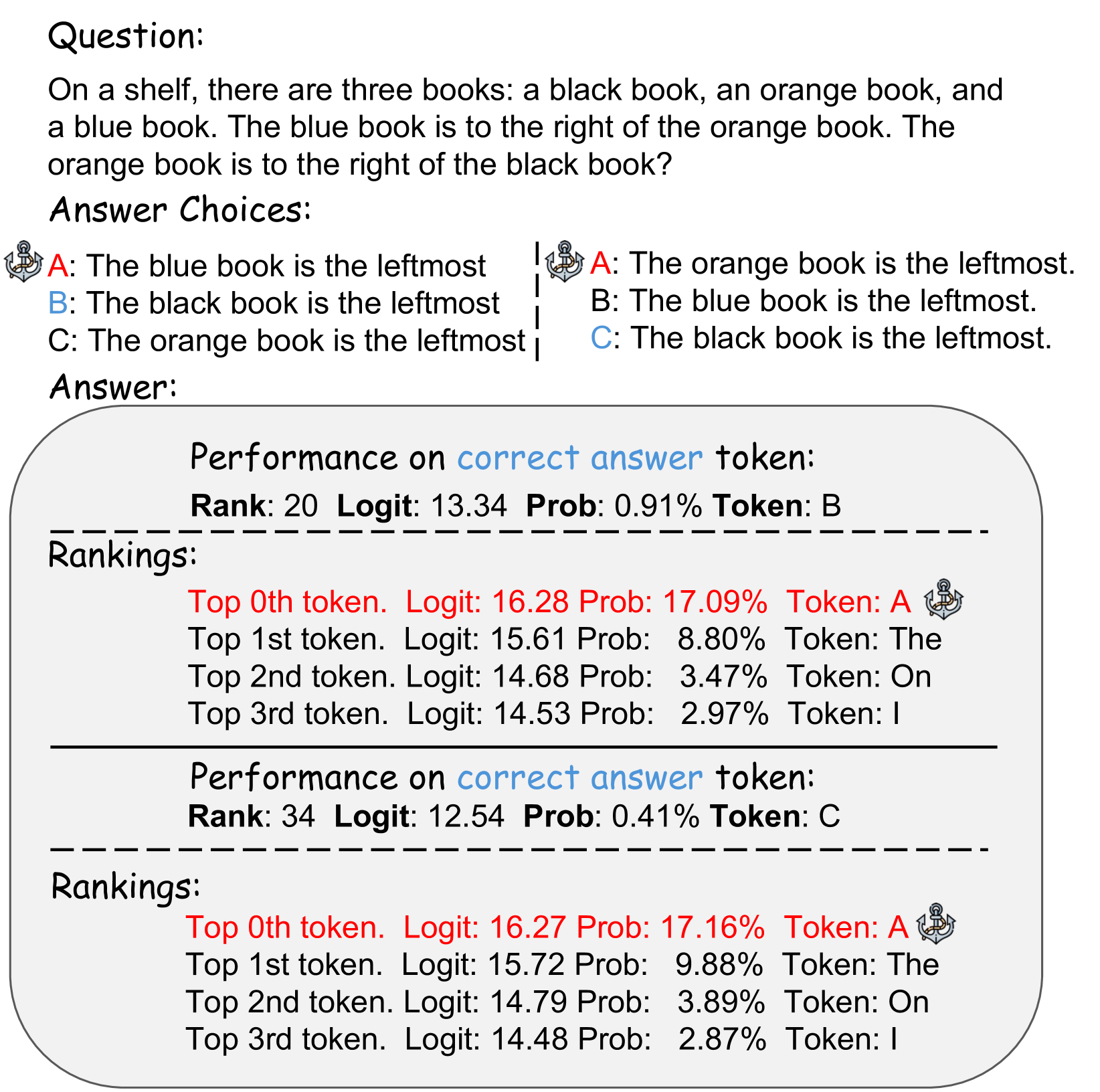
- GPT-2在多选题中存在严重的“锚定偏差”,倾向于选择第一个选项,影响了其决策的可靠性。
- 通过机制可解释性方法,定位并修改GPT-2模型中导致偏差的MLP层和注意力头中的特定向量。
- 实验表明,该方法有效减轻了锚定偏差,并提高了GPT-2模型在多选题任务中的整体准确性。
📝 摘要(中文)
大型语言模型(LLMs),如GPT-4和LLaMA系列,在多选题(MCQs)等多种任务中表现出显著的成功。然而,这些模型表现出位置偏差,特别是GPT-2系列中更严重的锚定偏差,即在推理过程中始终偏向第一个选项'A'。这种锚定偏差挑战了GPT-2决策过程的完整性,因为它扭曲了基于位置而非MCQ中选项内容的性能。在本研究中,我们利用机制可解释性方法来识别GPT-2模型中导致这种偏差的内部模块。我们专注于多层感知机(MLP)层和注意力头,使用“logit lens”方法来追踪和修改导致偏差的特定值向量。通过更新MLP中的这些向量并重新校准注意力模式以消除对第一个选项'A'的偏好,我们有效地减轻了锚定偏差。我们的干预不仅减轻了偏差,还提高了GPT-2系列在各种数据集上的整体MCQ预测准确性。这项工作代表了对GPT-2模型中MCQ失败案例中锚定偏差的首次全面机制分析,引入了有针对性的、最小干预策略,显著提高了GPT2模型在MCQ中的鲁棒性和准确性。
🔬 方法详解
问题定义:论文旨在解决GPT-2模型在多选题(MCQ)任务中存在的“锚定偏差”问题,即模型倾向于选择第一个选项(通常是“A”),而忽略选项的实际内容。这种偏差导致模型性能下降,并使其决策过程变得不可靠。现有方法无法有效解决这一问题,因为它们没有深入理解偏差产生的内在机制。
核心思路:论文的核心思路是利用机制可解释性方法,深入分析GPT-2模型内部的运作机制,找出导致锚定偏差的关键模块(MLP层和注意力头),并对其进行有针对性的干预。通过修改这些模块中的特定向量,消除模型对第一个选项的偏好,从而减轻锚定偏差。
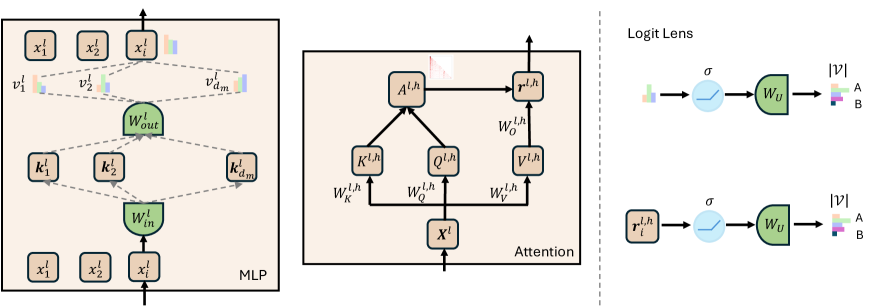
技术框架:该方法主要包含以下几个阶段:1) 使用“logit lens”方法追踪GPT-2模型中各层(特别是MLP层和注意力头)的输出,分析其对最终预测结果的影响。2) 定位导致锚定偏差的关键模块和向量。3) 修改这些向量,使其不再偏向第一个选项。4) 重新校准注意力模式,以消除对第一个选项的偏好。5) 在多个数据集上评估干预效果。
关键创新:该论文最重要的技术创新点在于其对锚定偏差的机制性分析。通过深入理解偏差产生的内在机制,论文提出了有针对性的干预策略,避免了盲目地调整模型参数。此外,论文还首次将机制可解释性方法应用于解决语言模型中的偏差问题。
关键设计:论文的关键设计包括:1) 使用“logit lens”方法进行模型内部状态的追踪和分析。2) 精确定位导致偏差的关键模块和向量。3) 设计有效的向量修改策略,以消除对第一个选项的偏好。4) 设计合适的评估指标,以衡量干预效果。
🖼️ 关键图片
📊 实验亮点
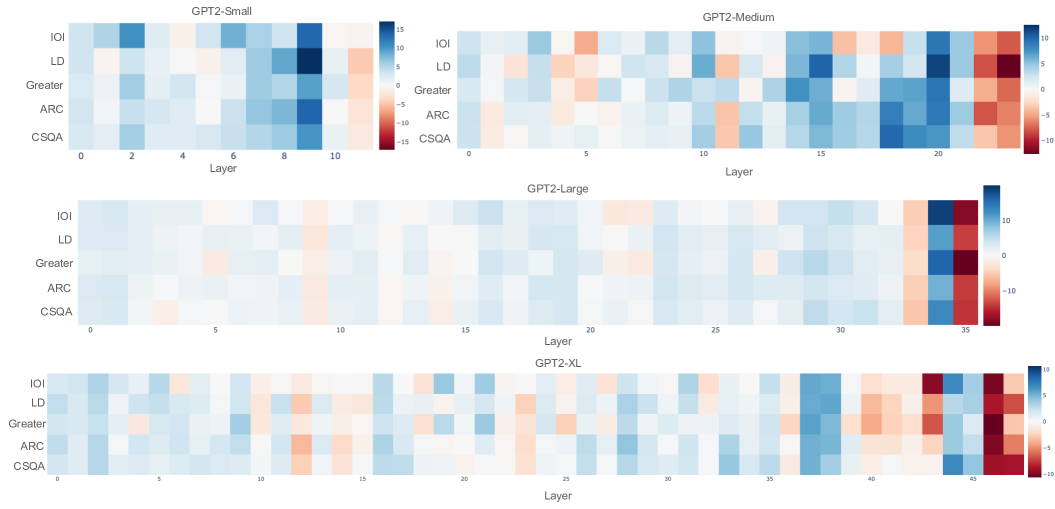
实验结果表明,该方法能够有效减轻GPT-2模型在多选题任务中的锚定偏差,并显著提高其预测准确性。具体而言,通过对MLP层和注意力头进行干预,模型对第一个选项的偏好明显降低,同时在多个数据集上的整体准确率得到了提升。这些结果验证了该方法的有效性和实用性。
🎯 应用场景
该研究成果可应用于提升大型语言模型在各种需要进行选择判断的任务中的可靠性和准确性,例如问答系统、信息检索和决策支持系统。通过消除模型中的偏差,可以提高其在实际应用中的表现,并使其能够做出更公正、更合理的决策。此外,该研究也为理解和解决其他类型的语言模型偏差提供了新的思路。
📄 摘要(原文)
Large Language Models (LLMs), such as the GPT-4 and LLaMA families, have demonstrated considerable success across diverse tasks, including multiple-choice questions (MCQs). However, these models exhibit a positional bias, particularly an even worse anchored bias in the GPT-2 family, where they consistently favour the first choice 'A' in MCQs during inference. This anchored bias challenges the integrity of GPT-2's decision-making process, as it skews performance based on the position rather than the content of the choices in MCQs. In this study, we utilise the mechanistic interpretability approach to identify the internal modules within GPT-2 models responsible for this bias. We focus on the Multi-Layer Perceptron (MLP) layers and attention heads, using the "logit lens" method to trace and modify the specific value vectors that contribute to the bias. By updating these vectors within MLP and recalibrating attention patterns to neutralise the preference for the first choice 'A', we effectively mitigate the anchored bias. Our interventions not only mitigate the bias but also improve the overall MCQ prediction accuracy for the GPT-2 family across various datasets. This work represents the first comprehensive mechanistic analysis of anchored bias from the failing cases in MCQs within the GPT-2 models, introducing targeted, minimal-intervention strategies that significantly enhance GPT2 model robustness and accuracy in MCQs. Our code is available at https://github.com/ruizheliUOA/Anchored_Bias_GPT2.