Labeling supervised fine-tuning data with the scaling law
作者: Huanjun Kong
分类: cs.CL
发布日期: 2024-05-05 (更新: 2024-08-16)
备注: 5 pages, 3 tables, 3 figures
🔗 代码/项目: GITHUB | HUGGINGFACE
💡 一句话要点
提出一种基于Scaling Law校准的多阶段人工标注方法,用于低资源环境下高质量SFT数据获取。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 监督式微调 Scaling Law 人工标注 低资源环境 大型语言模型
📋 核心要点
- 现有方法在低资源环境下难以获取高质量的监督式微调数据,限制了LLM在特定NLP任务上的应用。
- 该方法利用Scaling Law校准人工标注过程,通过多阶段标注确保数据质量,降低了对昂贵计算资源和API的依赖。
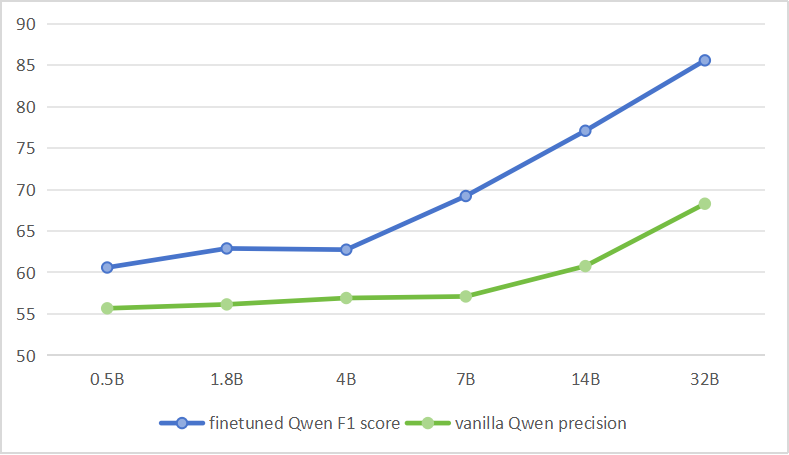
- 实验结果表明,使用该方法获得的SFT数据微调Qwen模型,在F1得分上取得了显著提升,验证了方法的有效性。
📝 摘要(中文)
本文介绍了一种基于Scaling Law校准的多阶段人工标注方法,为GPU资源匮乏、GPT访问受限以及资金不足等受限环境提供了一种高质量的监督式微调(SFT)数据获取方法。我们预处理了5.8万条真实的聊天数据,并手动标注了2.3千个问题。在此之后,我们对参数量从0.5B到32B的Qwen模型进行了微调。最佳版本在F1得分上提高了29.07。这证实了微调大型语言模型(LLM)对于下游自然语言处理(NLP)任务的可行性。我们的贡献是:1)创建了Alpaca格式的监督式微调(SFT)训练数据,以及一组低秩适应(LoRA)权重;2)开发了一种利用Scaling Law原理获取高质量数据的方法。脚本、Alpaca格式的原始数据和实验跟踪已在Github、HuggingFace和WandB上开源。所涉及数据的隐私已获得用户授权。SFT数据和许可证来自ncnn贡献者小组。
🔬 方法详解
问题定义:论文旨在解决在GPU资源有限、缺乏GPT访问权限以及资金受限等低资源环境下,如何高效地获取高质量的监督式微调(SFT)数据的问题。现有方法通常依赖于大规模预训练模型或昂贵的数据标注服务,这对于资源受限的场景来说是不可行的。
核心思路:论文的核心思路是利用Scaling Law来指导和校准人工标注过程。Scaling Law描述了模型性能与数据量、模型大小和计算资源之间的关系。通过分析不同规模模型在少量数据上的表现,可以预测更大规模模型所需的训练数据量,并指导人工标注的重点和方向,从而在有限的资源下获得高质量的数据。
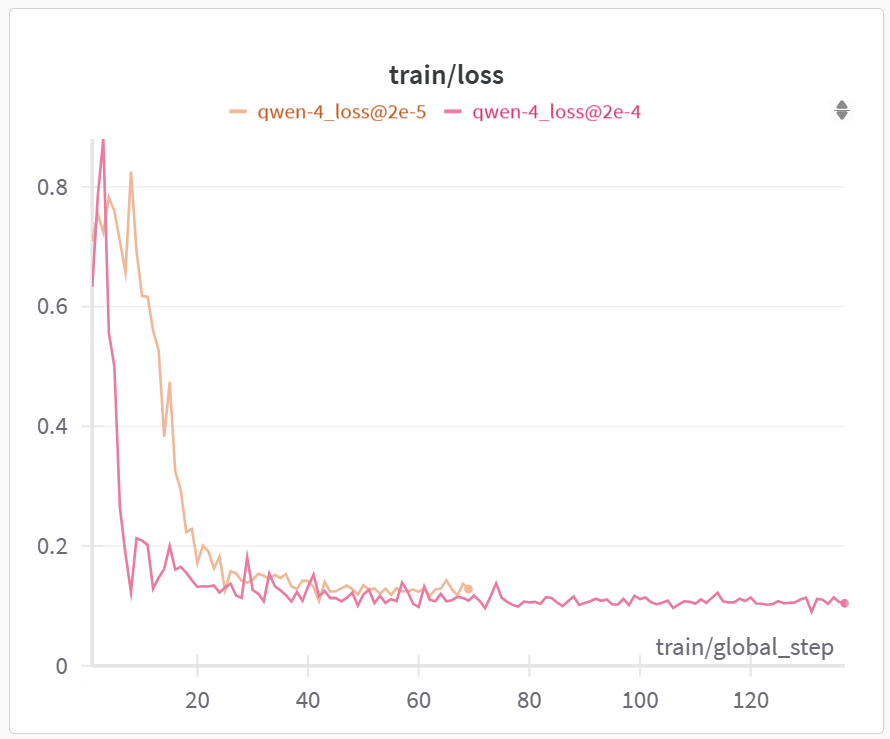
技术框架:该方法采用多阶段人工标注流程,具体步骤未知。整体框架可能包含以下几个阶段:1) 数据预处理:对原始聊天数据进行清洗和格式化,使其符合Alpaca格式。2) 初始标注:由人工对少量数据进行标注,生成初步的SFT数据集。3) 模型训练:使用不同规模的LLM(例如,Qwen-0.5B到Qwen-32B)在初始数据集上进行微调。4) Scaling Law分析:分析不同规模模型在验证集上的性能表现,根据Scaling Law预测更大规模模型所需的训练数据量和质量。5) 迭代标注:根据Scaling Law的分析结果,指导人工进行下一轮的标注,重点关注模型性能瓶颈和数据质量问题。6) 最终评估:使用最终的SFT数据集对LLM进行微调,并在下游NLP任务上进行评估。
关键创新:该方法最重要的创新点在于将Scaling Law引入到人工标注流程中,利用模型性能反馈来指导数据标注,从而在低资源环境下实现高质量的SFT数据获取。与传统的盲目标注方法相比,该方法更加高效和有针对性。
关键设计:论文中可能包含以下关键设计细节:1) Scaling Law模型的选择和参数设置。2) 数据质量评估指标的设计。3) 人工标注的指导原则和流程。4) 不同规模模型的训练策略和超参数设置。这些细节的具体内容未知。
🖼️ 关键图片
📊 实验亮点
该研究通过对Qwen模型(0.5B-32B)进行微调,验证了该方法的有效性。实验结果显示,使用该方法获得的SFT数据进行微调后,最佳版本在F1得分上提高了29.07%。这表明该方法能够在低资源环境下有效地提升LLM在下游NLP任务上的性能。
🎯 应用场景
该研究成果可应用于各种资源受限的NLP场景,例如在特定领域或小语种中构建高质量的LLM应用。该方法降低了SFT数据的获取成本,使得更多研究者和开发者能够参与到LLM的微调和应用中,促进了LLM技术的普及和发展。
📄 摘要(原文)
This paper introduces a multi-stage manual annotation calibrated by the scaling law, offering a high-quality Supervised Fine-Tuning data acquisition method for environments with constrained resources like GPU poor, limited GPT access, and funding restrictions. We have preprocessed 58k authentic chat data and manually annotated 2.3k questions. After this, we conducted fine-tuning on Qwen models, ranging from 0.5B to 32B parameters. The optimal version improved 29.07 in F1 score. This confirms the viability of fine-tuning Large Language Model (LLM) for downstream Natural Language Processing (NLP) tasks. Our contributions are: 1) Created Supervised Fine-Tuning (SFT) training data in alpaca format, along with a set of Low-Rank Adaptation (LoRA) weights, and 2) Developed a method for acquiring high-quality data leveraging scaling law principle. The script, raw data with alpaca format and experiments track are open-sourced on Github (https://github.com/InternLM/HuixiangDou/tree/main/web/tools), HuggingFace (https://huggingface.co/tpoisonooo) and WandB (https://wandb.ai/tpoisonooo/huixiangdou-cr/table?nw=nwusertpoisonooo). The privacy of the data involved has been authorized by users. SFT data and license comes from ncnn contributors group.