Assessing Adversarial Robustness of Large Language Models: An Empirical Study
作者: Zeyu Yang, Zhao Meng, Xiaochen Zheng, Roger Wattenhofer
分类: cs.CL, cs.LG
发布日期: 2024-05-04 (更新: 2024-09-12)
备注: Oral presentation at KDD 2024 GenAI Evaluation workshop
💡 一句话要点
提出白盒攻击方法,评估并提升大型语言模型对抗鲁棒性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 对抗攻击 鲁棒性评估 白盒攻击 文本分类
📋 核心要点
- 大型语言模型在自然语言处理领域取得了显著进展,但其对抗攻击的鲁棒性仍然是一个关键问题。
- 论文提出了一种白盒攻击方法,通过精心设计的对抗样本来暴露LLMs的脆弱性,从而评估其鲁棒性。
- 通过在多个文本分类任务上的实验,论文建立了LLM鲁棒性的新基准,并分析了模型结构、大小和微调策略的影响。
📝 摘要(中文)
本文提出了一种新颖的白盒攻击方法,旨在揭示领先的开源大型语言模型(LLMs)中的漏洞,包括Llama、OPT和T5。研究评估了模型大小、结构和微调策略对LLMs抵抗对抗扰动的影响。通过在五个不同的文本分类任务上进行全面评估,为LLM的鲁棒性建立了一个新的基准。这项研究的发现对LLMs在实际应用中的可靠部署具有深远的影响,并有助于可信赖人工智能系统的发展。
🔬 方法详解
问题定义:现有的大型语言模型虽然在各种自然语言处理任务中表现出色,但容易受到对抗攻击的影响。这些攻击通过对输入文本进行微小的、不易察觉的修改,就能导致模型产生错误的输出。现有的防御方法往往难以有效应对各种类型的对抗攻击,并且缺乏对不同模型结构和训练策略的鲁棒性评估。
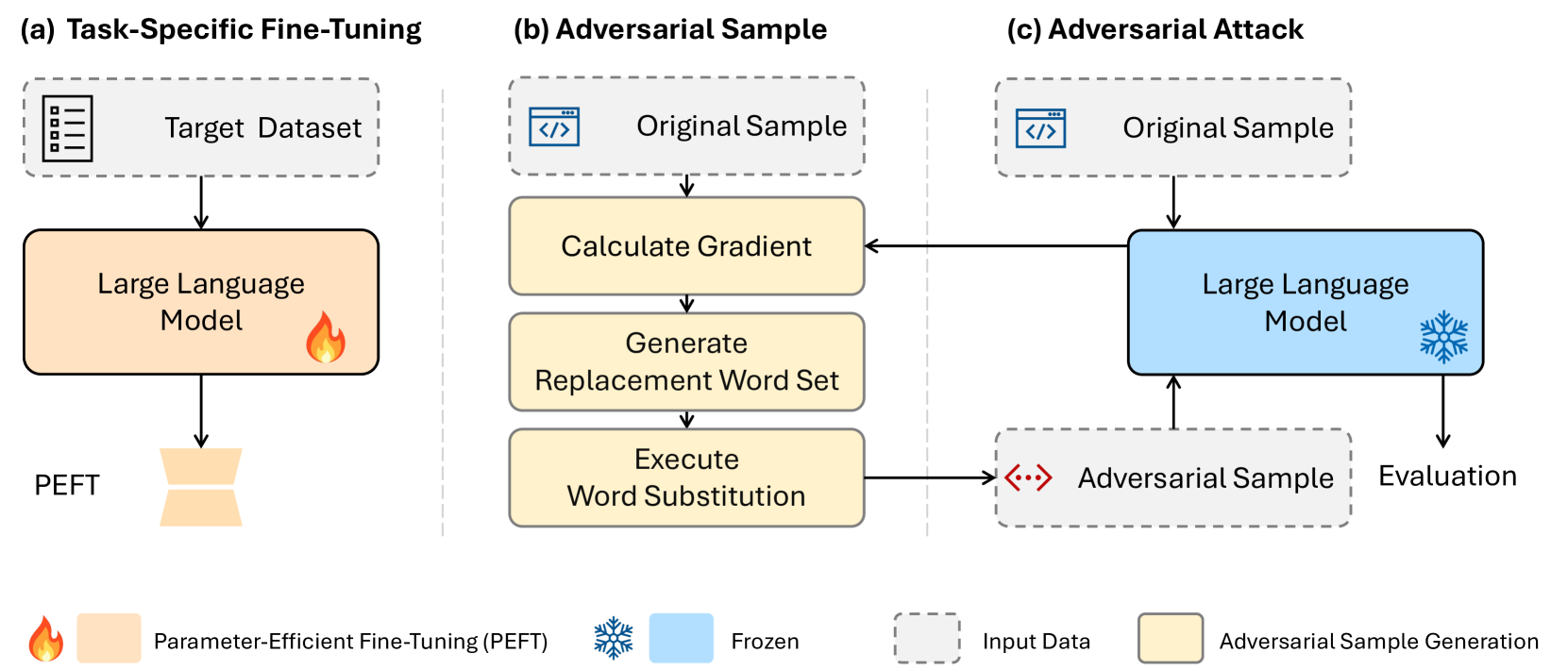
核心思路:论文的核心思路是设计一种白盒攻击方法,该方法能够充分利用模型的内部信息(如梯度)来生成有效的对抗样本。通过分析模型在对抗样本上的表现,可以深入了解模型的脆弱性,并为改进模型的鲁棒性提供指导。
技术框架:该研究的技术框架主要包括以下几个阶段:1) 选择目标大型语言模型(如Llama、OPT、T5);2) 设计白盒攻击算法,生成对抗样本;3) 在多个文本分类任务上评估模型的鲁棒性;4) 分析模型大小、结构和微调策略对鲁棒性的影响。
关键创新:论文的关键创新在于提出了一种新颖的白盒攻击方法,该方法能够有效地攻击大型语言模型,并揭示其潜在的脆弱性。此外,论文还通过全面的实验评估,为LLM的鲁棒性建立了一个新的基准,并分析了不同因素对鲁棒性的影响。
关键设计:具体的攻击算法设计细节未知,摘要中未提及。但可以推测,该白盒攻击方法可能利用梯度信息来指导对抗样本的生成,例如通过梯度上升或梯度下降等方法来寻找能够最大化模型损失的输入扰动。损失函数的设计可能考虑了模型的预测结果与真实标签之间的差异,以及对抗样本与原始样本之间的相似度。
🖼️ 关键图片
📊 实验亮点
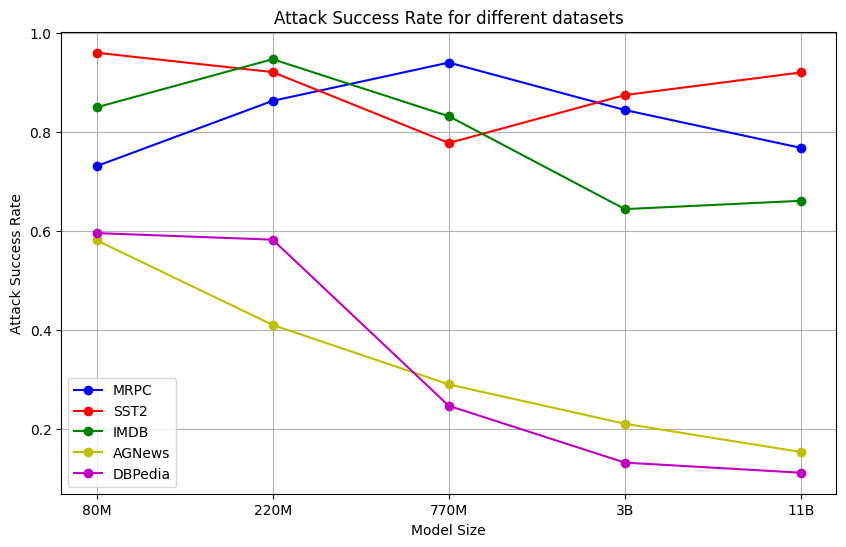
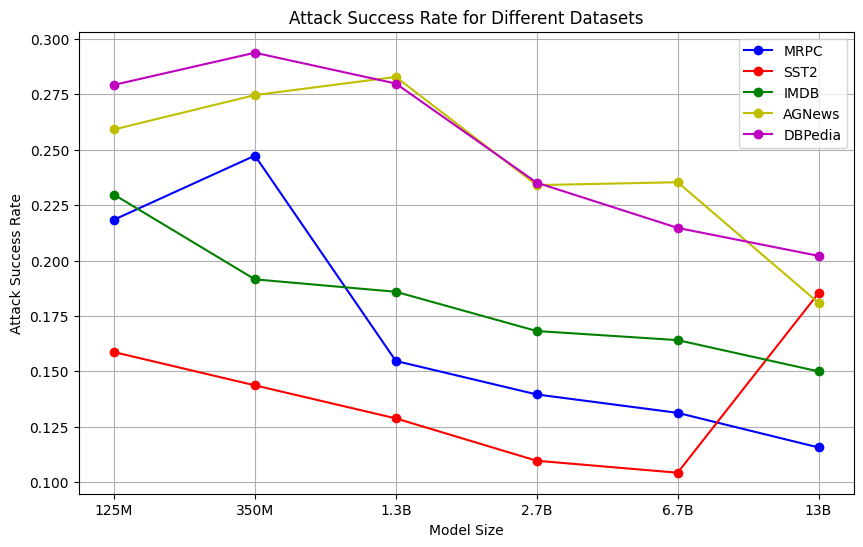
该研究通过在五个不同的文本分类任务上进行评估,为Llama、OPT和T5等主流LLM建立了一个新的鲁棒性基准。研究结果表明,模型大小、结构和微调策略对LLM的鲁棒性有显著影响。具体的性能数据和提升幅度未知,但该研究为后续的LLM鲁棒性研究提供了重要的参考。
🎯 应用场景
该研究成果可应用于提升大型语言模型在各种实际应用场景中的安全性,例如情感分析、文本分类、机器翻译等。通过提高LLMs的对抗鲁棒性,可以减少恶意攻击对AI系统的影响,保障用户数据的安全和隐私,并促进可信赖人工智能系统的发展。未来的研究可以进一步探索更有效的防御方法,并将其应用于更广泛的LLM应用场景。
📄 摘要(原文)
Large Language Models (LLMs) have revolutionized natural language processing, but their robustness against adversarial attacks remains a critical concern. We presents a novel white-box style attack approach that exposes vulnerabilities in leading open-source LLMs, including Llama, OPT, and T5. We assess the impact of model size, structure, and fine-tuning strategies on their resistance to adversarial perturbations. Our comprehensive evaluation across five diverse text classification tasks establishes a new benchmark for LLM robustness. The findings of this study have far-reaching implications for the reliable deployment of LLMs in real-world applications and contribute to the advancement of trustworthy AI systems.