Beyond Performance: Quantifying and Mitigating Label Bias in LLMs
作者: Yuval Reif, Roy Schwartz
分类: cs.CL
发布日期: 2024-05-04
备注: NAACL 2024
💡 一句话要点
提出一种标签偏差校准方法,提升LLM在少样本学习中的性能并缓解标签偏差。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 标签偏差 少样本学习 偏差校准 模型可靠性
📋 核心要点
- 现有方法难以可靠且大规模地检测和量化LLM中的标签偏差,阻碍了模型可靠性的提升。
- 提出一种新颖的标签偏差校准方法,专门针对少样本提示,旨在减轻LLM中的标签偏差。
- 实验结果表明,该方法在提高性能和缓解标签偏差方面优于现有的校准方法,验证了其有效性。
📝 摘要(中文)
大型语言模型(LLMs)通过利用包含指令或少量输入-输出示例的上下文提示,展现了对各种任务的卓越适应性。然而,最近的研究表明,它们也表现出标签偏差——一种对预测某些答案而非其他答案的不良偏好。尽管如此,可靠且大规模地检测和测量这种偏差仍然相对未被探索。在本研究中,我们评估了量化模型预测中标签偏差的不同方法,对279个分类任务和10个LLM进行了全面调查。我们的调查揭示了模型在去偏置尝试之前和之后都存在显著的标签偏差,并强调了基于结果的评估指标的重要性,而这些指标以前未被用于这方面。我们进一步提出了一种为少样本提示量身定制的新型标签偏差校准方法,该方法在提高性能和减轻标签偏差方面均优于最近的校准方法。我们的结果强调,LLM预测中的标签偏差仍然是其可靠性的一个障碍。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)中存在的标签偏差问题。现有方法在可靠且大规模地检测和量化这种偏差方面存在不足,导致难以有效地缓解标签偏差,从而影响了LLM的可靠性和泛化能力。尤其是在少样本学习场景下,标签偏差问题更为突出。
核心思路:论文的核心思路是设计一种专门针对少样本提示的标签偏差校准方法。该方法通过调整模型的预测概率分布,使其更加符合真实的标签分布,从而减轻标签偏差的影响。核心在于校准模型对不同标签的固有偏好,使其预测更加公平和准确。
技术框架:论文提出的方法主要包含以下几个阶段:1) 标签偏差评估:使用多种指标来量化模型在不同任务上的标签偏差程度。2) 偏差校准:基于评估结果,使用提出的校准方法调整模型的预测概率分布。3) 性能评估:使用基于结果的评估指标,评估校准后的模型在性能和偏差缓解方面的效果。整体流程旨在系统性地识别、量化和缓解LLM中的标签偏差。
关键创新:该方法的关键创新在于其针对少样本提示的特殊设计。与现有的通用校准方法不同,该方法考虑了少样本学习场景下的特殊挑战,例如数据稀疏性和模型对少量示例的过度拟合。通过专门的校准策略,该方法能够更有效地减轻标签偏差,并提高模型的泛化能力。
关键设计:具体的校准方法细节未知,摘要中只提到是“novel label bias calibration method tailored for few-shot prompting”,但可以推测可能涉及到以下设计:1) 偏差估计:利用少量的支持集样本来估计模型对不同标签的先验偏好。2) 概率调整:基于偏差估计结果,调整模型对每个标签的预测概率,例如通过加权或归一化等方式。3) 损失函数:可能设计了新的损失函数,以鼓励模型学习更加公平和准确的预测。
🖼️ 关键图片

📊 实验亮点
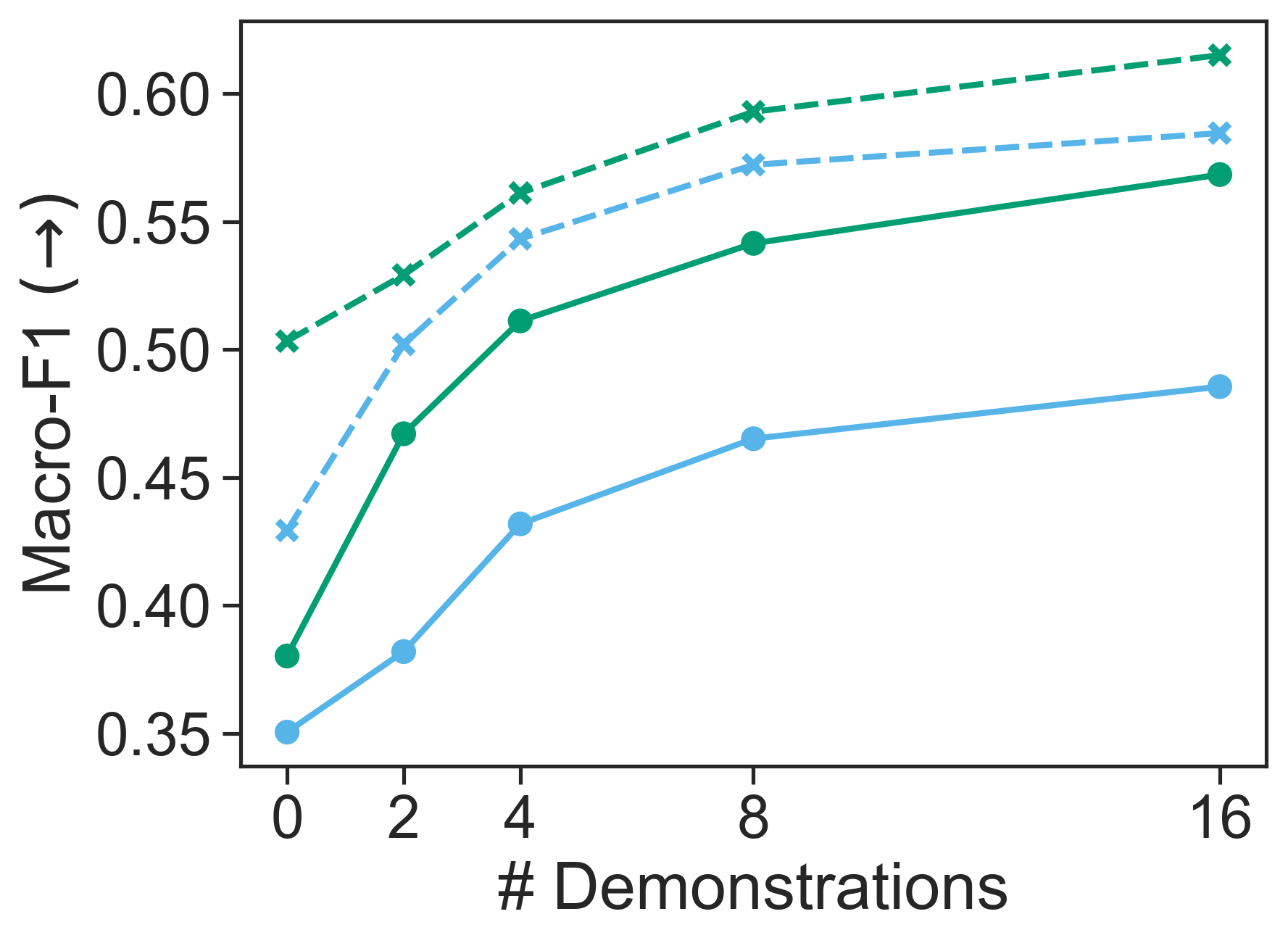
该研究通过对279个分类任务和10个LLM的全面调查,揭示了模型在去偏置尝试前后都存在显著的标签偏差。提出的新型标签偏差校准方法在提高性能和减轻标签偏差方面均优于最近的校准方法,表明了其有效性。具体性能提升数据未知,但强调了基于结果的评估指标的重要性。
🎯 应用场景
该研究成果可应用于各种需要可靠和公平的LLM预测的场景,例如文本分类、情感分析、问答系统等。通过减轻标签偏差,可以提高LLM在实际应用中的性能和可信度,尤其是在医疗、金融等敏感领域,可以避免因偏差导致的错误决策,具有重要的实际价值和未来影响。
📄 摘要(原文)
Large language models (LLMs) have shown remarkable adaptability to diverse tasks, by leveraging context prompts containing instructions, or minimal input-output examples. However, recent work revealed they also exhibit label bias -- an undesirable preference toward predicting certain answers over others. Still, detecting and measuring this bias reliably and at scale has remained relatively unexplored. In this study, we evaluate different approaches to quantifying label bias in a model's predictions, conducting a comprehensive investigation across 279 classification tasks and ten LLMs. Our investigation reveals substantial label bias in models both before and after debiasing attempts, as well as highlights the importance of outcomes-based evaluation metrics, which were not previously used in this regard. We further propose a novel label bias calibration method tailored for few-shot prompting, which outperforms recent calibration approaches for both improving performance and mitigating label bias. Our results emphasize that label bias in the predictions of LLMs remains a barrier to their reliability.