R4: Reinforced Retriever-Reorder-Responder for Retrieval-Augmented Large Language Models
作者: Taolin Zhang, Dongyang Li, Qizhou Chen, Chengyu Wang, Longtao Huang, Hui Xue, Xiaofeng He, Jun Huang
分类: cs.CL
发布日期: 2024-05-04 (更新: 2024-06-25)
备注: need to further experiment
💡 一句话要点
提出R⁴框架,通过强化学习重排序检索文档,提升检索增强大语言模型的事实问答能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 检索增强LLM 强化学习 文档排序 知识密集型问答 图注意力网络
📋 核心要点
- 现有检索增强LLM方法忽略了检索文档与LLM之间细粒度结构语义的交互,导致LLM在处理长文档时性能下降。
- R⁴框架通过强化学习优化文档排序,将文档组织到提示的开始、中间和结束位置,从而提升LLM的生成能力。
- 实验结果表明,R⁴框架在知识密集型问答任务上优于现有基线方法,证明了其有效性。
📝 摘要(中文)
检索增强大语言模型(LLMs)利用信息检索系统检索到的相关内容生成正确的回复,旨在缓解幻觉问题。然而,现有的检索-回复方法通常将相关文档附加到LLMs的提示中以执行文本生成任务,而没有考虑检索到的文档和LLMs之间细粒度结构语义的交互。这个问题对于准确的回复生成尤为重要,因为LLMs在处理用冗长文档增强的输入提示时容易“迷失在中间”。在这项工作中,我们提出了一种名为“强化检索-重排序-回复”(R⁴)的新流程,以学习检索增强LLMs的文档排序,从而进一步增强它们的生成能力,同时保持LLMs的大量参数冻结。重排序学习过程根据生成的回复质量分为两个步骤:文档顺序调整和文档表示增强。具体而言,文档顺序调整旨在基于图注意力学习将检索到的文档排序组织到开始、中间和结束位置,从而最大化回复质量的强化奖励。文档表示增强通过文档级梯度对抗学习进一步细化检索到的文档表示,以用于质量较差的回复。大量的实验表明,与各种公共数据集上的强大基线相比,我们提出的流程在知识密集型任务上实现了更好的事实问答性能。源代码和训练好的模型将在论文被接受后发布。
🔬 方法详解
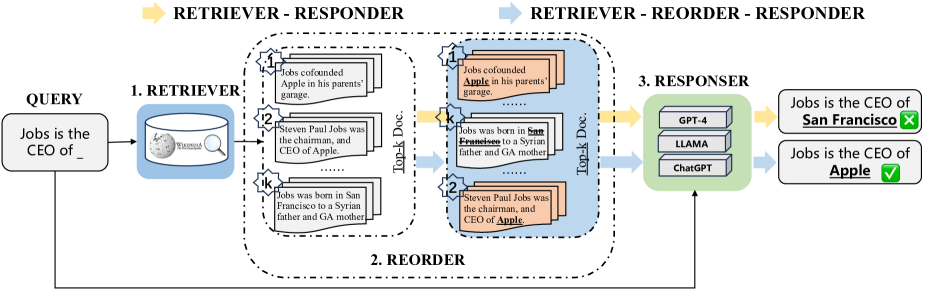
问题定义:现有检索增强LLM方法直接将检索到的文档附加到LLM的prompt中,忽略了文档之间的顺序关系以及文档与LLM之间的交互。由于LLM存在“lost in the middle”的问题,即对prompt中间部分的信息利用率较低,导致生成质量下降。因此,如何有效地组织检索到的文档,使其更好地服务于LLM的生成过程,是一个亟待解决的问题。
核心思路:R⁴框架的核心思路是通过强化学习来学习文档的排序,使得LLM能够更好地利用检索到的信息。具体来说,R⁴将文档排序问题建模为一个序列决策问题,通过奖励函数来指导排序策略的学习。奖励函数的设计与生成回复的质量相关联,高质量的回复会获得更高的奖励,从而鼓励模型学习更好的排序策略。
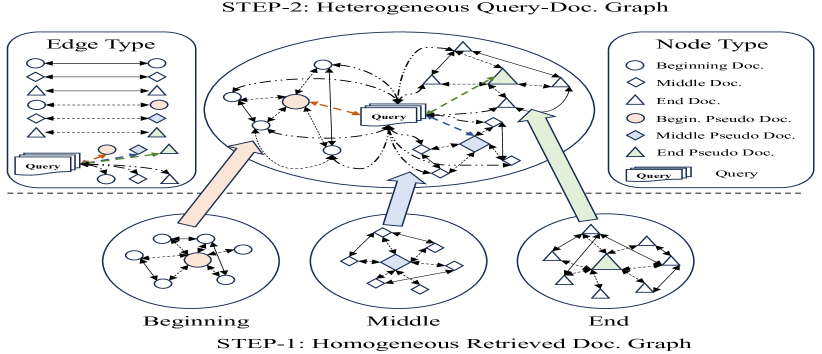
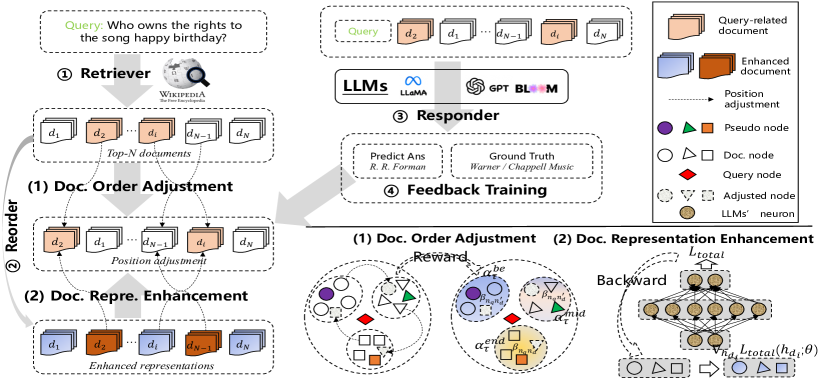
技术框架:R⁴框架包含三个主要模块:检索器(Retriever)、重排序器(Reorderer)和回复器(Responder)。首先,检索器从知识库中检索相关文档。然后,重排序器根据当前策略对检索到的文档进行排序。最后,回复器(LLM)根据排序后的文档生成回复。整个框架通过强化学习进行训练,重排序器的目标是最大化回复器生成高质量回复的期望奖励。框架包含文档顺序调整和文档表示增强两个阶段。
关键创新:R⁴框架的关键创新在于引入了强化学习来优化文档排序。与传统的基于规则或启发式的排序方法不同,R⁴能够根据LLM的反馈动态地调整排序策略,从而更好地适应不同的任务和数据集。此外,R⁴还通过文档级梯度对抗学习来增强文档表示,进一步提升了排序的准确性。
关键设计:文档顺序调整阶段使用图注意力网络学习文档之间的关系,并根据文档在prompt中的位置(开始、中间、结束)进行排序。奖励函数基于回复的质量进行设计,例如使用BLEU或ROUGE等指标。文档表示增强阶段使用文档级梯度对抗学习,通过对抗训练来提升文档表示的鲁棒性。具体参数设置和网络结构细节未在摘要中详细说明,需参考论文全文。
🖼️ 关键图片
📊 实验亮点
实验结果表明,R⁴框架在多个知识密集型问答数据集上取得了显著的性能提升,优于现有的检索增强LLM方法。具体的性能数据和提升幅度需要在论文全文中查找。该结果验证了R⁴框架在优化文档排序方面的有效性,并证明了强化学习在检索增强LLM中的潜力。
🎯 应用场景
R⁴框架可应用于各种知识密集型任务,例如问答系统、对话系统和文本生成。通过优化检索文档的排序,R⁴能够提升LLM的生成质量和准确性,减少幻觉问题。该研究对于构建更可靠、更智能的AI系统具有重要意义,并有望在教育、医疗、金融等领域发挥重要作用。
📄 摘要(原文)
Retrieval-augmented large language models (LLMs) leverage relevant content retrieved by information retrieval systems to generate correct responses, aiming to alleviate the hallucination problem. However, existing retriever-responder methods typically append relevant documents to the prompt of LLMs to perform text generation tasks without considering the interaction of fine-grained structural semantics between the retrieved documents and the LLMs. This issue is particularly important for accurate response generation as LLMs tend to "lose in the middle" when dealing with input prompts augmented with lengthy documents. In this work, we propose a new pipeline named "Reinforced Retriever-Reorder-Responder" (R$^4$) to learn document orderings for retrieval-augmented LLMs, thereby further enhancing their generation abilities while the large numbers of parameters of LLMs remain frozen. The reordering learning process is divided into two steps according to the quality of the generated responses: document order adjustment and document representation enhancement. Specifically, document order adjustment aims to organize retrieved document orderings into beginning, middle, and end positions based on graph attention learning, which maximizes the reinforced reward of response quality. Document representation enhancement further refines the representations of retrieved documents for responses of poor quality via document-level gradient adversarial learning. Extensive experiments demonstrate that our proposed pipeline achieves better factual question-answering performance on knowledge-intensive tasks compared to strong baselines across various public datasets. The source codes and trained models will be released upon paper acceptance.