Semantic Scaling: Bayesian Ideal Point Estimates with Large Language Models
作者: Michael Burnham
分类: cs.CL
发布日期: 2024-05-03
💡 一句话要点
提出Semantic Scaling,利用大语言模型进行文本理想点估计,提升意识形态测量灵活性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语义标度 大语言模型 理想点估计 项目反应理论 意识形态测量
📋 核心要点
- 现有基于文本的意识形态测量方法缺乏灵活性,难以明确定义意识形态维度。
- Semantic Scaling利用大语言模型对文本进行分类,提取立场信息,并使用项目反应理论进行标度。
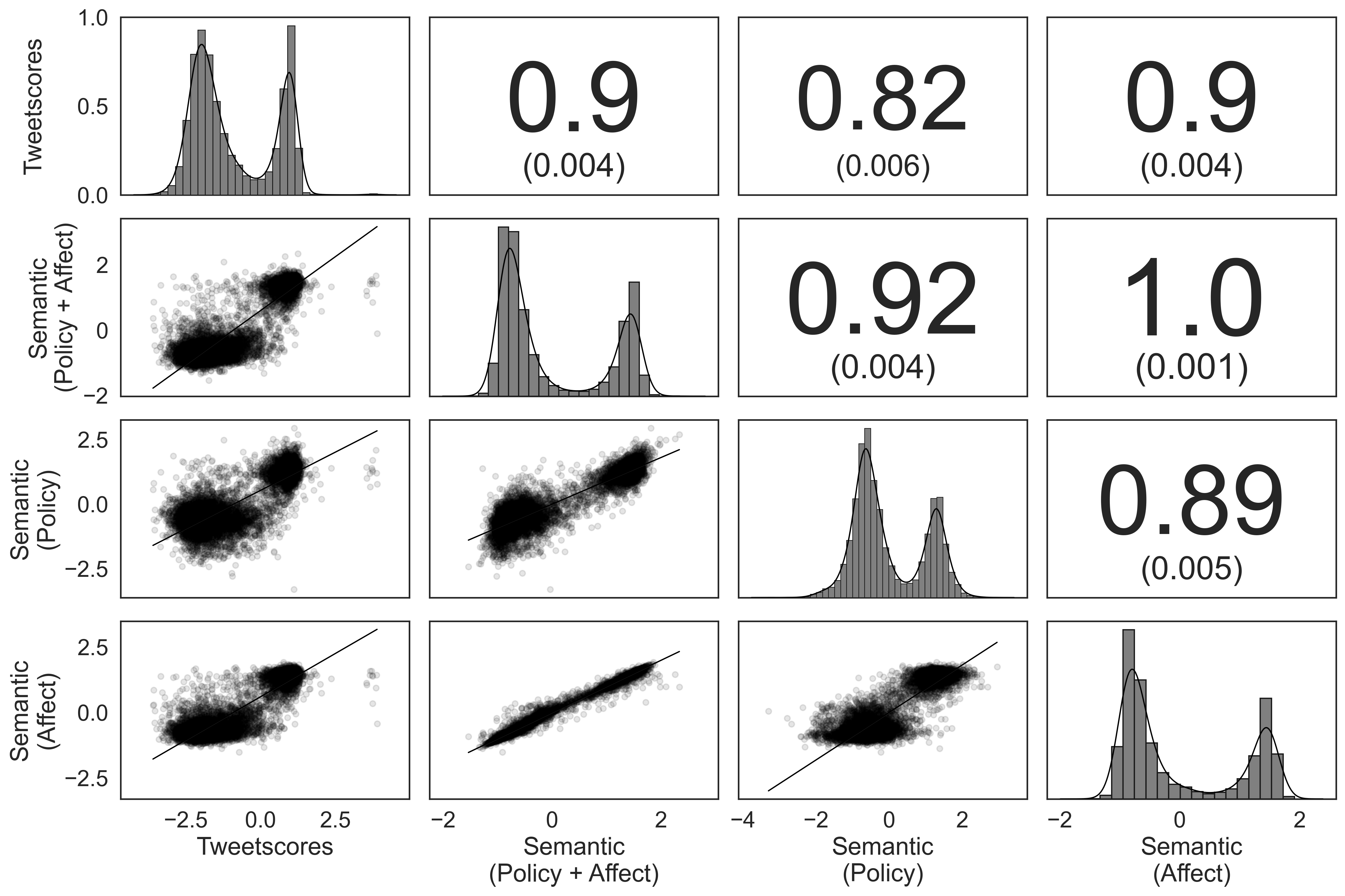
- 实验表明,该方法在公众和国会数据上均优于现有方法,并能区分政策偏好和群体情感。
📝 摘要(中文)
本文介绍了一种名为“Semantic Scaling”的新方法,用于从文本中估计理想点。该方法利用大型语言模型对文档进行分类,基于其表达的立场提取类似调查的数据。然后,使用项目反应理论对这些数据中的主体进行标度。Semantic Scaling显著优于现有的基于文本的标度方法,并允许研究人员明确定义他们测量的意识形态维度。这是第一个允许在调查工具之外具有这种灵活性的标度方法,并为难以调查的人群开辟了新的研究途径。此外,它适用于不同长度的文档,并产生对大众和精英意识形态的有效估计。实验证明,该方法可以区分政策偏好和群体内外情感。在公众中,Semantic Scaling在人类判断方面优于Tweetscores;在国会中,它重新获得了第一维DW-NOMINATE,同时在解决结构效度挑战方面具有更大的灵活性。
🔬 方法详解
问题定义:论文旨在解决从文本数据中进行意识形态理想点估计的问题。现有方法,如Tweetscores和DW-NOMINATE,存在灵活性不足、难以明确定义意识形态维度以及难以应用于非结构化文本等痛点。这些方法通常依赖于预定义的特征或专家知识,限制了其适用性和可解释性。
核心思路:Semantic Scaling的核心思路是利用大型语言模型(LLM)的语义理解能力,将文本数据转化为类似调查问卷的数据,然后应用项目反应理论(IRT)进行标度。通过LLM,可以自动提取文本中蕴含的意识形态立场,从而避免了人工特征工程的局限性,并允许研究人员更灵活地定义意识形态维度。
技术框架:Semantic Scaling的整体框架包含以下几个主要阶段: 1. 数据准备:收集需要进行意识形态标度的文本数据,例如社交媒体帖子、新闻文章或政治演讲。 2. LLM分类:使用预训练的LLM对文本数据进行分类,判断其在特定意识形态维度上的立场。例如,可以训练LLM判断文本对某项政策的支持程度。 3. 数据转换:将LLM的分类结果转换为类似调查问卷的数据格式,其中每个文本对应一个“受访者”,每个意识形态维度对应一个“问题”,LLM的分类结果对应“回答”。 4. IRT标度:使用项目反应理论(IRT)对转换后的数据进行标度,估计每个文本在意识形态维度上的理想点。IRT模型可以考虑不同“问题”的难度和区分度,从而更准确地估计理想点。
关键创新:Semantic Scaling最重要的技术创新点在于利用LLM进行文本的语义理解和立场提取,从而实现了更灵活、更自动化的意识形态标度。与现有方法相比,Semantic Scaling无需人工特征工程,可以处理非结构化文本,并允许研究人员明确定义意识形态维度。
关键设计:Semantic Scaling的关键设计包括: 1. LLM选择:选择合适的预训练LLM,并根据具体任务进行微调。可以使用监督学习或少样本学习方法训练LLM。 2. 意识形态维度定义:明确定义需要测量的意识形态维度,并设计相应的LLM分类任务。 3. IRT模型选择:选择合适的IRT模型,例如二参数logistic模型或三参数logistic模型。可以使用贝叶斯方法估计IRT模型的参数。
🖼️ 关键图片


📊 实验亮点
实验结果表明,Semantic Scaling在公众数据上优于Tweetscores,在国会数据上能够重现DW-NOMINATE的第一维度,同时具有更高的灵活性。该方法能够有效区分政策偏好和群体情感,证明了其在意识形态测量方面的有效性和可靠性。具体性能提升数据未知。
🎯 应用场景
Semantic Scaling可广泛应用于政治学、社会学、传播学等领域,用于分析公众舆论、政治人物立场、媒体偏见等。它能够帮助研究人员更深入地理解社会意识形态的分布和演变,为政策制定和社会治理提供参考。该方法尤其适用于难以进行传统调查的人群,例如历史人物或匿名网络用户。
📄 摘要(原文)
This paper introduces "Semantic Scaling," a novel method for ideal point estimation from text. I leverage large language models to classify documents based on their expressed stances and extract survey-like data. I then use item response theory to scale subjects from these data. Semantic Scaling significantly improves on existing text-based scaling methods, and allows researchers to explicitly define the ideological dimensions they measure. This represents the first scaling approach that allows such flexibility outside of survey instruments and opens new avenues of inquiry for populations difficult to survey. Additionally, it works with documents of varying length, and produces valid estimates of both mass and elite ideology. I demonstrate that the method can differentiate between policy preferences and in-group/out-group affect. Among the public, Semantic Scaling out-preforms Tweetscores according to human judgement; in Congress, it recaptures the first dimension DW-NOMINATE while allowing for greater flexibility in resolving construct validity challenges.