What does the Knowledge Neuron Thesis Have to do with Knowledge?
作者: Jingcheng Niu, Andrew Liu, Zining Zhu, Gerald Penn
分类: cs.CL
发布日期: 2024-05-03
备注: ICLR 2024 (Spotlight)
💡 一句话要点
质疑知识神经元假说:大型语言模型知识存储并非仅依赖MLP权重
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 知识神经元 大型语言模型 模型编辑 知识表示 可解释性
📋 核心要点
- 现有知识神经元假说(KN)认为LLM通过MLP权重存储和回忆事实,但该假说可能过于简化。
- 本文通过模型编辑方法,不仅能编辑事实表达,还能编辑其他语言现象,表明KN假说解释力不足。
- 研究强调需超越MLP权重,探索LLM中更复杂的层结构和注意力机制,以理解知识表示。
📝 摘要(中文)
本文重新评估了知识神经元(KN)假说,该假说旨在解释大型语言模型从训练语料库中回忆事实的能力。该假说认为,事实的召回是通过MLP权重以类似于键值记忆的方式实现的,这意味着“知识”存储在网络中。此外,通过修改MLP模块,可以控制语言模型生成的事实信息。KN假说的合理性已通过受KN启发的模型编辑方法的成功得到证明。然而,本文发现该假说充其量是一种过度简化。研究发现,可以使用相同的模型编辑方法来编辑某些语言现象的表达。通过更全面的评估,发现KN假说不足以解释事实表达的过程。虽然可以认为MLP权重存储了在句法和语义上都可解释的复杂模式,但这些模式并不构成“知识”。为了更全面地理解知识表示过程,必须超越MLP权重,探索最新模型复杂的层结构和注意力机制。
🔬 方法详解
问题定义:论文旨在评估和挑战知识神经元(KN)假说,该假说认为大型语言模型(LLM)中的知识主要存储在MLP层的权重中,并可以通过编辑这些权重来控制模型的事实输出。现有方法的痛点在于,它们过度简化了LLM中知识表示的复杂性,忽略了其他重要组件(如注意力机制和层结构)的作用。
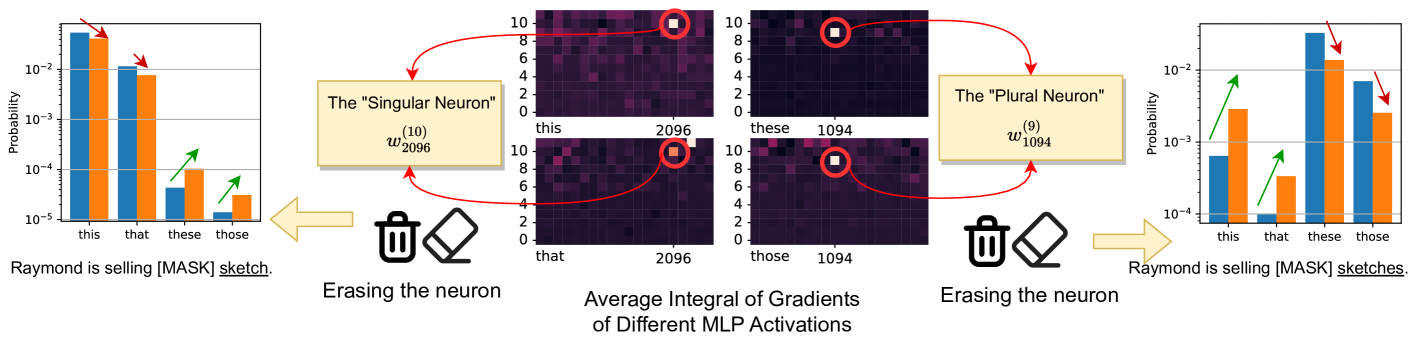
核心思路:论文的核心思路是通过实验验证KN假说的局限性。具体来说,研究者们尝试使用基于KN假说的模型编辑方法,不仅编辑模型的事实知识,还编辑其他类型的语言现象。如果相同的编辑方法能够成功编辑非事实性的语言现象,则说明KN假说无法充分解释LLM中的知识表示。
技术框架:论文的技术框架主要包括以下几个步骤:1) 选择一个预训练的LLM作为基础模型;2) 使用基于KN假说的模型编辑方法(如修改MLP权重)来编辑模型;3) 设计实验来评估编辑后的模型在事实知识和其他语言现象上的表现;4) 分析实验结果,判断KN假说是否能够充分解释模型的行为。
关键创新:论文最重要的技术创新点在于,它通过实验证明了KN假说的局限性,并指出LLM中的知识表示可能更加复杂,涉及到多个组件的协同作用。与现有方法相比,该论文更加注重对KN假说的批判性评估,而不是简单地应用或扩展该假说。
关键设计:论文的关键设计包括:1) 选择合适的LLM和模型编辑方法;2) 设计能够区分事实知识和其他语言现象的实验;3) 使用合适的评估指标来衡量模型编辑的效果。具体的参数设置、损失函数和网络结构等细节取决于所选择的LLM和模型编辑方法。
🖼️ 关键图片


📊 实验亮点
研究发现,基于知识神经元假说的模型编辑方法不仅可以编辑事实知识,还可以编辑其他类型的语言现象,例如句法结构和语义关系。这表明知识神经元假说无法充分解释大型语言模型中的知识表示。实验结果表明,需要更全面地考虑模型的层结构和注意力机制。
🎯 应用场景
该研究成果有助于更深入地理解大型语言模型内部的知识表示机制,从而为改进模型的可解释性、可控性和可靠性提供指导。潜在应用包括:开发更有效的模型编辑方法,提高模型生成内容的准确性和一致性,以及设计更鲁棒的自然语言处理系统。
📄 摘要(原文)
We reassess the Knowledge Neuron (KN) Thesis: an interpretation of the mechanism underlying the ability of large language models to recall facts from a training corpus. This nascent thesis proposes that facts are recalled from the training corpus through the MLP weights in a manner resembling key-value memory, implying in effect that "knowledge" is stored in the network. Furthermore, by modifying the MLP modules, one can control the language model's generation of factual information. The plausibility of the KN thesis has been demonstrated by the success of KN-inspired model editing methods (Dai et al., 2022; Meng et al., 2022). We find that this thesis is, at best, an oversimplification. Not only have we found that we can edit the expression of certain linguistic phenomena using the same model editing methods but, through a more comprehensive evaluation, we have found that the KN thesis does not adequately explain the process of factual expression. While it is possible to argue that the MLP weights store complex patterns that are interpretable both syntactically and semantically, these patterns do not constitute "knowledge." To gain a more comprehensive understanding of the knowledge representation process, we must look beyond the MLP weights and explore recent models' complex layer structures and attention mechanisms.