Attribution in Scientific Literature: New Benchmark and Methods
作者: Yash Saxena, Deepa Tilwani, Ali Mohammadi, Edward Raff, Amit Sheth, Srinivasan Parthasarathy, Manas Gaur
分类: cs.CL, cs.AI, cs.IR
发布日期: 2024-05-03 (更新: 2025-04-11)
备注: Work in progress
💡 一句话要点
提出REASONS数据集,解决科学文献中LLM自动引用时的幻觉问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 科学文献引用 大型语言模型 幻觉抑制 REASONS数据集 元数据增强 检索增强生成 自然语言处理
📋 核心要点
- 现有引用生成方法在科学文献中存在歧义和LLM过度泛化问题,影响自动引用的准确性。
- 论文提出REASONS数据集,包含句子级注释和元数据,用于评估和改进LLM在科学引用中的表现。
- 实验表明,元数据增强和RAG方法能有效降低LLM的幻觉率,提升引用准确性,但仍存在挑战。
📝 摘要(中文)
大型语言模型(LLM)为科学交流中的自动来源引用提供了一个有前景但充满挑战的前沿。以往的引用生成方法受到引用歧义和LLM过度泛化的限制。我们引入了REASONS,这是一个新的数据集,包含来自arXiv的12个科学领域的句子级注释。我们的评估框架涵盖了两个关键的引用场景:间接查询(将句子与论文标题匹配)和直接查询(作者归属),两者都通过上下文元数据得到增强。我们使用GPT-O1、GPT-4O、GPT-3.5、DeepSeek以及其他较小的模型(如Perplexity AI (7B))进行了广泛的实验。虽然顶级LLM在句子归属方面取得了很高的性能,但它们在高幻觉率方面表现不佳,这是科学可靠性的一个关键指标。我们的元数据增强方法降低了所有任务中的幻觉率,为改进提供了一个有希望的方向。带有Mistral的检索增强生成(RAG)提高了间接查询的性能,将幻觉率降低了42%,并保持了与大型模型相当的精度。然而,对抗性测试突出了将论文标题与摘要联系起来的挑战,揭示了当前LLM的基本局限性。REASONS为开发科学应用中可靠和值得信赖的LLM提供了一个具有挑战性的基准。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在科学文献中进行自动引用时出现的幻觉问题。现有方法在处理引用歧义和LLM过度泛化方面存在不足,导致引用不准确,影响科学研究的可靠性。
核心思路:论文的核心思路是通过构建一个高质量的基准数据集REASONS,并结合元数据增强和检索增强生成(RAG)技术,来评估和改进LLM在科学引用任务中的性能,特别是降低幻觉率。
技术框架:整体框架包括三个主要部分:1) 构建REASONS数据集,包含句子级注释和上下文元数据;2) 设计评估框架,涵盖间接查询(句子到论文标题)和直接查询(作者归属)两种场景;3) 使用多种LLM(如GPT系列、DeepSeek、Mistral等)进行实验,并分析结果。RAG方法被用于增强LLM的检索能力。
关键创新:论文的关键创新在于:1) 提出了REASONS数据集,为科学引用任务提供了一个新的、更具挑战性的基准;2) 探索了元数据增强方法,通过利用上下文信息来减少LLM的幻觉;3) 验证了RAG方法在降低幻觉率和提高引用准确性方面的有效性。
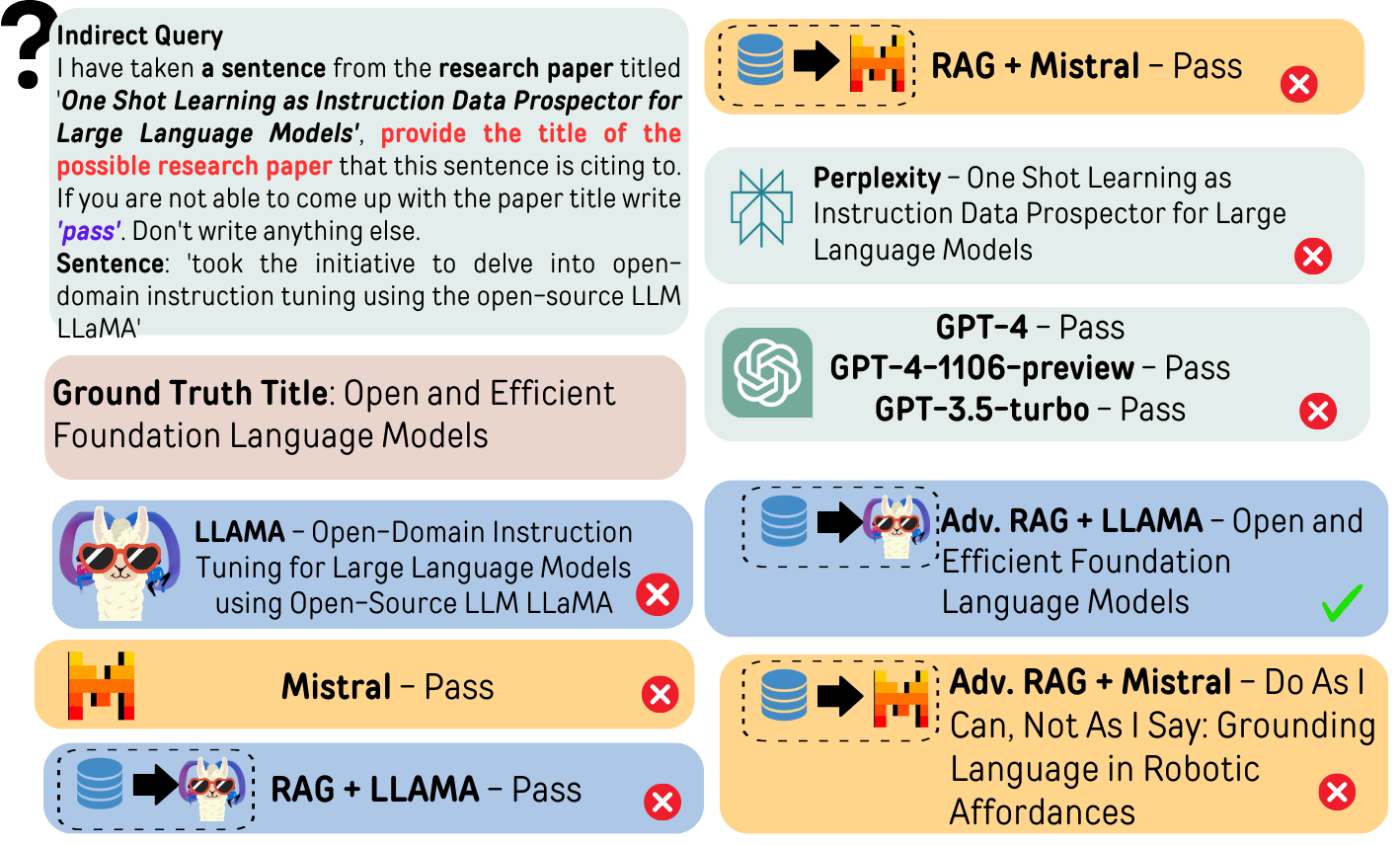
关键设计:REASONS数据集包含来自arXiv的12个科学领域的句子级注释,并附带上下文元数据。评估框架设计了间接查询和直接查询两种场景,以全面评估LLM的引用能力。RAG方法使用Mistral模型进行检索,并结合LLM进行生成。对抗性测试用于评估LLM在处理论文标题和摘要关联方面的鲁棒性。
🖼️ 关键图片
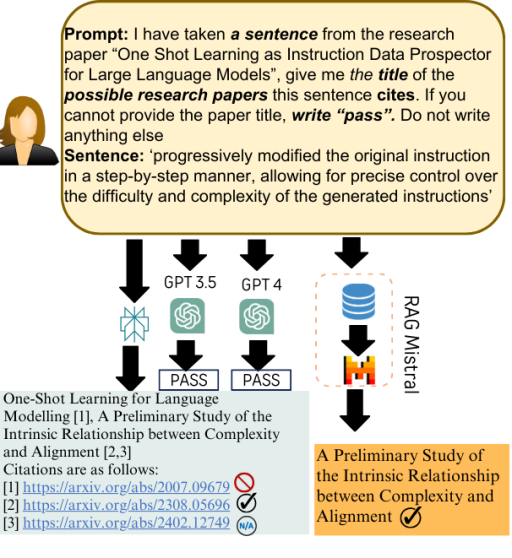

📊 实验亮点
实验结果表明,元数据增强方法能够有效降低LLM在科学引用任务中的幻觉率。使用Mistral的RAG方法在间接查询中将幻觉率降低了42%,同时保持了与大型模型相当的精度。然而,对抗性测试也揭示了当前LLM在处理论文标题和摘要关联方面的局限性。
🎯 应用场景
该研究成果可应用于自动文献综述、科研写作辅助、学术搜索引擎优化等领域。通过提高LLM在科学引用中的准确性和可靠性,有助于提升科研效率,促进知识传播,并为构建可信赖的AI系统奠定基础。未来可进一步探索更复杂的引用场景和更有效的幻觉抑制方法。
📄 摘要(原文)
Large language models (LLMs) present a promising yet challenging frontier for automated source citation in scientific communication. Previous approaches to citation generation have been limited by citation ambiguity and LLM overgeneralization. We introduce REASONS, a novel dataset with sentence-level annotations across 12 scientific domains from arXiv. Our evaluation framework covers two key citation scenarios: indirect queries (matching sentences to paper titles) and direct queries (author attribution), both enhanced with contextual metadata. We conduct extensive experiments with models such as GPT-O1, GPT-4O, GPT-3.5, DeepSeek, and other smaller models like Perplexity AI (7B). While top-tier LLMs achieve high performance in sentence attribution, they struggle with high hallucination rates, a key metric for scientific reliability. Our metadata-augmented approach reduces hallucination rates across all tasks, offering a promising direction for improvement. Retrieval-augmented generation (RAG) with Mistral improves performance in indirect queries, reducing hallucination rates by 42% and maintaining competitive precision with larger models. However, adversarial testing highlights challenges in linking paper titles to abstracts, revealing fundamental limitations in current LLMs. REASONS provides a challenging benchmark for developing reliable and trustworthy LLMs in scientific applications