Assessing and Verifying Task Utility in LLM-Powered Applications
作者: Negar Arabzadeh, Siqing Huo, Nikhil Mehta, Qinqyun Wu, Chi Wang, Ahmed Awadallah, Charles L. A. Clarke, Julia Kiseleva
分类: cs.CL, cs.AI
发布日期: 2024-05-03 (更新: 2024-05-12)
备注: arXiv admin note: text overlap with arXiv:2402.09015
💡 一句话要点
AgentEval:用于评估和验证LLM应用任务效用的新框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM应用评估 任务效用验证 自动化评估框架 AgentEval 评估标准生成
📋 核心要点
- 现有LLM应用缺乏有效评估其任务效用的方法,难以保证应用功能与用户需求的对齐。
- AgentEval框架通过自动生成评估标准,量化LLM应用在特定任务上的效用,实现全面评估。
- 在数学问题解决和ALFWorld任务上的实验表明,AgentEval能够有效评估LLM应用的性能。
📝 摘要(中文)
大型语言模型(LLM)的快速发展催生了大量促进多智能体协作的应用,以辅助人们的日常任务。然而,在评估LLM驱动的应用在多大程度上真正提升用户体验和任务执行效率方面,仍然存在显著差距。这突显了验证LLM驱动的应用效用的必要性,特别是通过确保应用的功能与最终用户需求之间的一致性。我们介绍AgentEval,这是一个新颖的框架,旨在通过自动提出一套针对任何给定应用的独特目的量身定制的标准,来简化效用验证过程。这允许进行全面的评估,根据建议的标准量化应用的效用。我们对AgentEval在数学问题解决和ALFWorld家庭相关任务这两个开源数据集上的有效性和鲁棒性进行了全面分析。为了便于重现,我们将数据、代码和所有日志公开在https://bit.ly/3w3yKcS。
🔬 方法详解
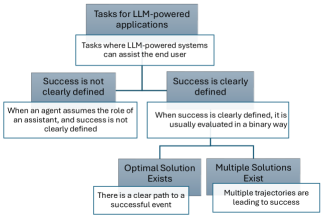
问题定义:论文旨在解决如何有效评估和验证基于LLM的应用的任务效用问题。现有方法缺乏针对特定应用的评估标准,难以准确衡量LLM应用对用户体验和任务效率的提升。现有方法的痛点在于缺乏自动化和通用性,无法适应不同LLM应用的评估需求。
核心思路:论文的核心思路是构建一个自动化框架,该框架能够根据LLM应用的具体任务,自动生成一套评估标准,并利用这些标准来量化应用的效用。通过这种方式,可以更准确地评估LLM应用是否真正满足用户需求,并提高任务执行效率。
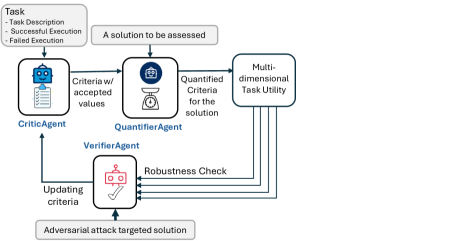
技术框架:AgentEval框架包含以下主要模块:1) 任务理解模块:分析LLM应用的任务描述,提取关键信息。2) 评估标准生成模块:基于任务理解的结果,自动生成一套针对该任务的评估标准。3) 效用评估模块:利用生成的评估标准,对LLM应用的性能进行量化评估。4) 结果分析模块:对评估结果进行分析,提供关于LLM应用优缺点的反馈。
关键创新:AgentEval的关键创新在于其自动生成评估标准的能力。与传统的手动定义评估标准的方法相比,AgentEval能够更快速、更灵活地适应不同LLM应用的评估需求。此外,AgentEval还提供了一种量化评估LLM应用效用的方法,使得评估结果更具可比性和可解释性。
关键设计:AgentEval在评估标准生成模块中,使用了基于LLM的生成模型,该模型能够根据任务描述,生成一套包含多个评估指标的评估标准。在效用评估模块中,使用了多种评估指标,包括准确率、召回率、F1值等。具体参数设置和损失函数等技术细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片
📊 实验亮点
AgentEval在数学问题解决和ALFWorld家庭相关任务两个数据集上进行了评估。实验结果表明,AgentEval能够有效地评估LLM应用的性能,并提供有价值的反馈。具体的性能数据和提升幅度在论文中未详细说明,属于未知信息。但论文强调了AgentEval的有效性和鲁棒性。
🎯 应用场景
AgentEval可广泛应用于各种基于LLM的应用的评估和验证,例如智能助手、自动化客服、代码生成工具等。通过AgentEval,开发者可以更好地了解其LLM应用的性能,并根据评估结果进行优化,从而提高用户体验和任务执行效率。该研究有助于推动LLM技术在实际应用中的发展。
📄 摘要(原文)
The rapid development of Large Language Models (LLMs) has led to a surge in applications that facilitate collaboration among multiple agents, assisting humans in their daily tasks. However, a significant gap remains in assessing to what extent LLM-powered applications genuinely enhance user experience and task execution efficiency. This highlights the need to verify utility of LLM-powered applications, particularly by ensuring alignment between the application's functionality and end-user needs. We introduce AgentEval, a novel framework designed to simplify the utility verification process by automatically proposing a set of criteria tailored to the unique purpose of any given application. This allows for a comprehensive assessment, quantifying the utility of an application against the suggested criteria. We present a comprehensive analysis of the effectiveness and robustness of AgentEval for two open source datasets including Math Problem solving and ALFWorld House-hold related tasks. For reproducibility purposes, we make the data, code and all the logs publicly available at https://bit.ly/3w3yKcS .