Analyzing Narrative Processing in Large Language Models (LLMs): Using GPT4 to test BERT
作者: Patrick Krauss, Jannik Hösch, Claus Metzner, Andreas Maier, Peter Uhrig, Achim Schilling
分类: cs.CL, cs.AI
发布日期: 2024-05-03
💡 一句话要点
利用GPT4生成叙事文本,分析BERT在不同风格和内容下的表征差异
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 叙事理解 BERT 风格分析 多维尺度分析
📋 核心要点
- 现有研究缺乏对LLM内部语言处理机制的深入理解,难以模拟人脑的语言处理方式。
- 利用GPT4生成不同风格的叙事文本,输入BERT并分析其隐藏层激活模式,揭示不同层对风格和内容的表征差异。
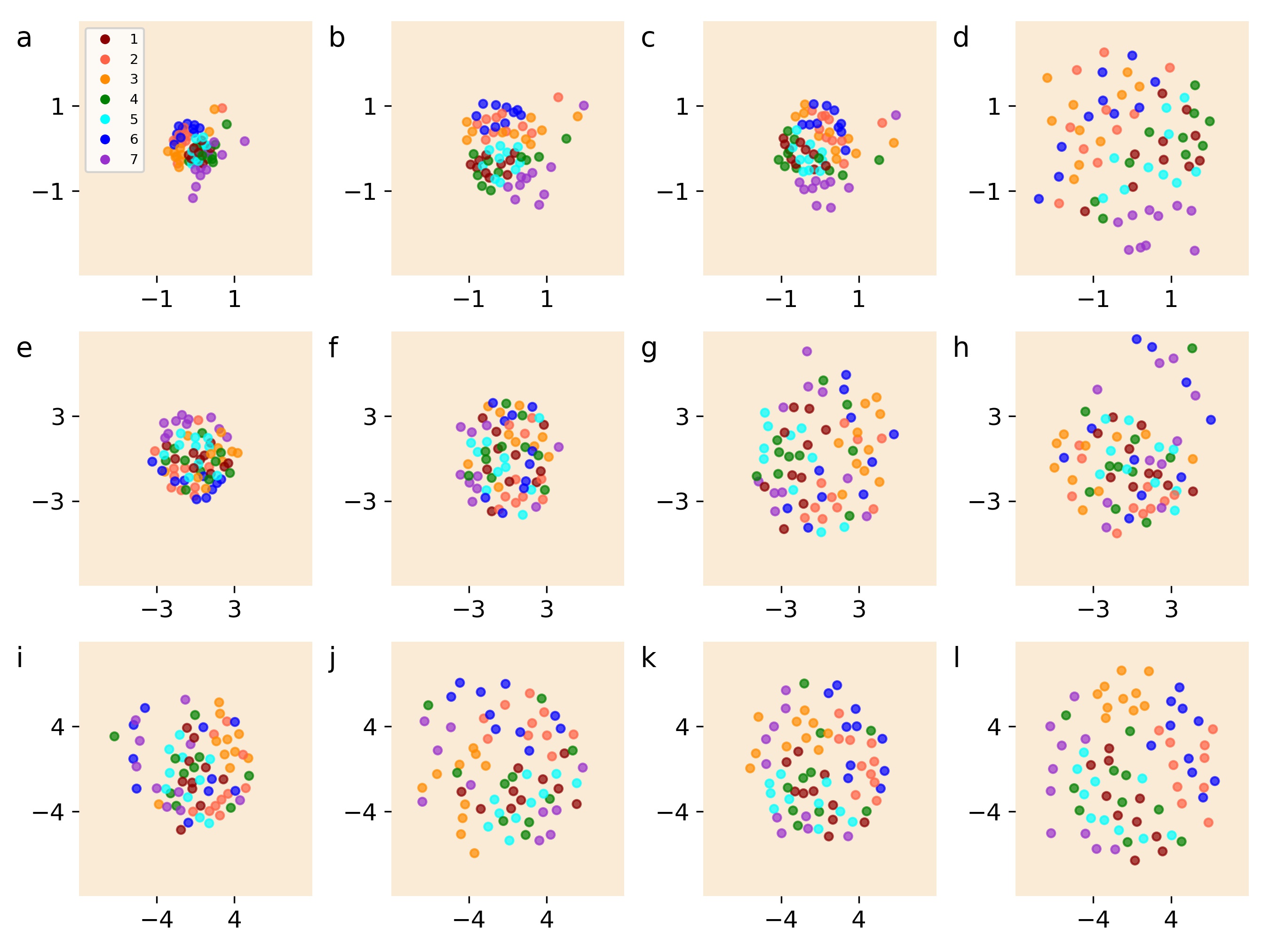
- 实验发现BERT早期层侧重于风格识别,而后期层侧重于内容理解,这与人脑语言处理的分层机制相似。
📝 摘要(中文)
本研究旨在利用大型语言模型(LLMs)作为模型,理解神经网络中语言处理的基本机制,从而预测和生成关于人类大脑如何进行语言处理的假设。研究使用ChatGPT生成了十个不同叙事(伊索寓言)的七种不同风格变体。然后,将这些故事作为开源LLM BERT的输入,并使用多维尺度分析和聚类分析来分析BERT隐藏单元的激活模式。研究发现,BERT早期层(1)的隐藏单元的激活向量根据风格变体进行聚类,而叙事内容在较后层(4-5)才开始聚类。这表明BERT的不同层执行不同的任务,类似于人脑中具有不同功能的自相似结构,从而高效地处理语言。该方法有望揭示LLM的黑盒,并进一步揭示人类语言处理和认知背后的神经过程。
🔬 方法详解
问题定义:论文旨在理解大型语言模型(LLMs)如何处理叙事文本中的风格和内容信息。现有方法难以区分LLM内部不同层对不同类型语言信息的处理方式,阻碍了对LLM语言理解机制的深入理解。
核心思路:论文的核心思路是利用可控的叙事文本生成方法(通过ChatGPT),系统性地改变叙事文本的风格和内容,然后分析LLM(BERT)在处理这些文本时的内部表征变化。通过观察不同层对风格和内容的敏感程度,推断LLM的语言处理机制。
技术框架:整体框架包括以下几个阶段:1) 使用ChatGPT生成多个叙事文本,每个叙事文本具有多种风格变体。2) 将这些文本输入到BERT模型中。3) 提取BERT每一层的隐藏单元的激活向量。4) 使用多维尺度分析(Multi-Dimensional Scaling, MDS)和聚类分析方法,分析激活向量的分布和聚类情况。5) 比较不同层对风格和内容的区分能力。
关键创新:该研究的关键创新在于:1) 将LLM(ChatGPT)用于生成可控的实验文本,从而能够系统性地研究另一个LLM(BERT)的语言处理机制。2) 通过分析BERT不同层的激活模式,揭示了其对风格和内容的分层处理方式。3) 将LLM的语言处理机制与人脑的语言处理机制进行类比,为理解人脑语言处理提供了新的视角。
关键设计:研究使用了10个不同的伊索寓言作为叙事内容,并使用ChatGPT生成了每个寓言的7种不同风格变体。BERT模型使用了预训练的BERT-base模型,没有进行额外的微调。多维尺度分析和聚类分析使用了标准的实现方法。激活向量的提取和分析是逐层进行的,以便观察不同层的表征变化。
🖼️ 关键图片


📊 实验亮点
实验结果表明,BERT的早期层(第1层)主要关注叙事文本的风格特征,而较后层(第4-5层)则更多地关注叙事内容。这表明BERT在处理语言信息时具有分层结构,类似于人脑的语言处理机制。该研究为理解LLM的内部机制提供了新的证据。
🎯 应用场景
该研究成果可应用于改进LLM的语言理解能力,例如,通过调整网络结构或训练策略,使其更好地模拟人脑的语言处理机制。此外,该研究方法还可以用于分析其他LLM的内部机制,从而促进通用人工智能的发展。该研究还有助于理解人脑的语言处理机制,为认知科学和神经科学提供新的 insights。
📄 摘要(原文)
The ability to transmit and receive complex information via language is unique to humans and is the basis of traditions, culture and versatile social interactions. Through the disruptive introduction of transformer based large language models (LLMs) humans are not the only entity to "understand" and produce language any more. In the present study, we have performed the first steps to use LLMs as a model to understand fundamental mechanisms of language processing in neural networks, in order to make predictions and generate hypotheses on how the human brain does language processing. Thus, we have used ChatGPT to generate seven different stylistic variations of ten different narratives (Aesop's fables). We used these stories as input for the open source LLM BERT and have analyzed the activation patterns of the hidden units of BERT using multi-dimensional scaling and cluster analysis. We found that the activation vectors of the hidden units cluster according to stylistic variations in earlier layers of BERT (1) than narrative content (4-5). Despite the fact that BERT consists of 12 identical building blocks that are stacked and trained on large text corpora, the different layers perform different tasks. This is a very useful model of the human brain, where self-similar structures, i.e. different areas of the cerebral cortex, can have different functions and are therefore well suited to processing language in a very efficient way. The proposed approach has the potential to open the black box of LLMs on the one hand, and might be a further step to unravel the neural processes underlying human language processing and cognition in general.