DALLMi: Domain Adaption for LLM-based Multi-label Classifier
作者: Miruna Beţianu, Abele Mălan, Marco Aldinucci, Robert Birke, Lydia Chen
分类: cs.CL, cs.LG
发布日期: 2024-05-03
DOI: 10.1007/978-981-97-2259-4_21
💡 一句话要点
DALLMi:针对LLM多标签分类器的领域自适应方法,解决目标域标签不全和训练开销大的问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 领域自适应 多标签分类 大型语言模型 半监督学习 BERT
📋 核心要点
- 现有领域自适应方法主要集中在图像或文本二元分类,无法有效解决LLM多标签分类器在领域偏移时目标域标签不全和训练开销大的问题。
- DALLMi通过变分损失和MixUp正则化,有效利用有限的带标签和大量的无标签文本,以及BERT词嵌入的插值,实现半监督领域自适应。
- 实验结果表明,DALLMi在多个数据集上,相比无监督和部分监督方法,mAP分别提升了19.9%和52.2%,证明了其有效性。
📝 摘要(中文)
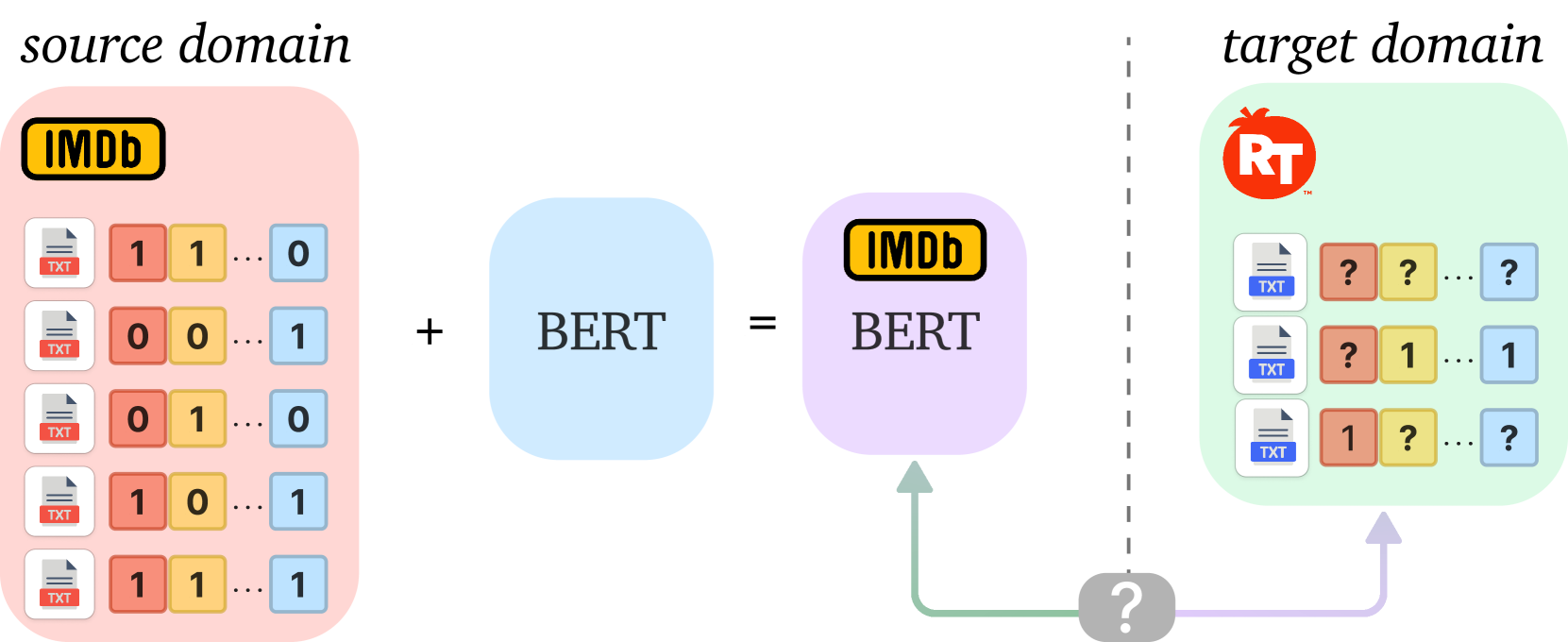
大型语言模型(LLM)越来越多地被用作对与不同领域相关联的文本进行分类,并同时分配多个标签(类别)。当遇到领域偏移时,例如将IMDb的电影评论分类器迁移到烂番茄,由于目标域中不完整的标签集和巨大的训练开销,自适应这种基于LLM的多标签分类器具有挑战性。现有的领域自适应方法主要针对图像多标签分类器或文本二元分类器。本文设计了DALLMi,即领域自适应大型语言模型插值器,这是一种首创的基于LLM的文本数据模型的半监督领域自适应方法,特别是基于BERT。DALLMi的核心是新颖的变分损失和MixUp正则化,它们共同利用了有限的带正标签的文本和大量的未标记文本,以及它们从BERT词嵌入中的插值。DALLMi还引入了一种标签平衡采样策略,以克服标记数据和未标记数据之间的不平衡。我们在三个数据集上,针对目标域标签可用性的不同场景,评估了DALLMi与部分监督和无监督方法的对比。结果表明,DALLMi比无监督和部分监督方法分别实现了高19.9%和52.2%的mAP。
🔬 方法详解
问题定义:论文旨在解决基于LLM的多标签文本分类器在领域自适应场景下的问题。具体来说,当源域和目标域的数据分布存在差异,且目标域的标签信息不完整时,如何有效地将模型从源域迁移到目标域。现有方法要么是针对图像多标签分类,要么是针对文本二元分类,无法直接应用于基于LLM的文本多标签分类,并且忽略了目标域中大量未标注数据的信息,导致模型性能下降。
核心思路:DALLMi的核心思路是利用半监督学习的方式,同时结合目标域中有限的带标签数据和大量的无标签数据。通过变分损失来约束模型学习到的特征表示,使其在源域和目标域之间保持一致性。同时,利用MixUp正则化来增强模型的泛化能力,并利用BERT词嵌入的插值来生成新的训练样本。
技术框架:DALLMi的整体框架包括以下几个主要模块:1) 基于BERT的文本编码器,用于将文本转换为词嵌入表示;2) 变分损失模块,用于约束源域和目标域的特征表示;3) MixUp正则化模块,用于增强模型的泛化能力;4) 标签平衡采样策略,用于解决标记数据和未标记数据之间的不平衡问题。整个流程是:首先使用BERT对文本进行编码,然后计算变分损失和MixUp正则化损失,最后使用标签平衡采样策略进行训练。
关键创新:DALLMi的关键创新在于以下几点:1) 提出了针对LLM多标签分类器的半监督领域自适应方法;2) 设计了新颖的变分损失,用于约束源域和目标域的特征表示;3) 引入了MixUp正则化,增强了模型的泛化能力;4) 提出了标签平衡采样策略,解决了标记数据和未标记数据之间的不平衡问题。与现有方法相比,DALLMi能够更有效地利用目标域中的无标签数据,从而提高模型的性能。
关键设计:DALLMi的关键设计包括:1) 变分损失的设计,具体形式未知,但其目的是最小化源域和目标域特征分布的差异;2) MixUp正则化的应用,通过对BERT词嵌入进行插值,生成新的训练样本;3) 标签平衡采样策略,具体实现未知,但其目的是平衡标记数据和未标记数据之间的比例,避免模型过度拟合标记数据。
🖼️ 关键图片


📊 实验亮点
实验结果表明,DALLMi在三个数据集上,针对目标域标签可用性的不同场景,均优于无监督和部分监督方法。具体而言,DALLMi比无监督方法实现了高19.9%的mAP,比部分监督方法实现了高52.2%的mAP,充分证明了DALLMi的有效性。
🎯 应用场景
DALLMi可应用于各种文本分类场景,例如情感分析、主题分类、垃圾邮件检测等。尤其适用于目标领域数据标注成本高昂或标签信息不完整的场景。该研究有助于提升LLM在跨领域文本分类任务中的性能和泛化能力,具有重要的实际应用价值。
📄 摘要(原文)
Large language models (LLMs) increasingly serve as the backbone for classifying text associated with distinct domains and simultaneously several labels (classes). When encountering domain shifts, e.g., classifier of movie reviews from IMDb to Rotten Tomatoes, adapting such an LLM-based multi-label classifier is challenging due to incomplete label sets at the target domain and daunting training overhead. The existing domain adaptation methods address either image multi-label classifiers or text binary classifiers. In this paper, we design DALLMi, Domain Adaptation Large Language Model interpolator, a first-of-its-kind semi-supervised domain adaptation method for text data models based on LLMs, specifically BERT. The core of DALLMi is the novel variation loss and MixUp regularization, which jointly leverage the limited positively labeled and large quantity of unlabeled text and, importantly, their interpolation from the BERT word embeddings. DALLMi also introduces a label-balanced sampling strategy to overcome the imbalance between labeled and unlabeled data. We evaluate DALLMi against the partial-supervised and unsupervised approach on three datasets under different scenarios of label availability for the target domain. Our results show that DALLMi achieves higher mAP than unsupervised and partially-supervised approaches by 19.9% and 52.2%, respectively.